素人がトピックモデルを試してみた (第1回)
2018年05月07日 月曜日
CONTENTS
私たちは毎日のように文書を読んでいます。 メール、SNS 投稿、技術文書、ニュース記事などなど…… もちろん読むだけでなく、自分たちで書いたりもします。 日々たくさんの文書に囲まれて生活しています。
こうした文書生活の利便性を上げるために、自動的に整理したり補助情報を付加する方法が考え出され使われています。 いくつか例を挙げると
- タグ付け
その文書がどんな話題を扱っているか端的に示すタグ(複数)が付いている - グループ化
同じ話題に関する文書をひとつにまとめてある - 関連文書の提示
話題の近い文書をおすすめ
などがあります。
もしこれらを実現する技術が手元にあれば、複数の情報源(サイトやシステム)を横断して自分たちの用途に合わせて統一的なタグを付けたり、グループ化をしたりするシステムが作れそうです。 また、自分たちで書いてきた組織内文書の山にも適用できるでしょう。 さらにその発展として、文書以外のデータに同じ技術を適用して役立たせることも考えられます。
さて、「これらを実現する技術」はどこらへんにあるのでしょう? 少し調べてみると、どうやら自然言語処理と機械学習にその基礎技術があって、特に機械学習の方では統計学的なアプローチによる手法が主流のようです。 筆者は統計学の詳しいことはサッパリわかりませんが、解説書を読むなどして(統計学的な部分を抜いて)理解したことを実験しつつ、紹介していきたいと思います。
筆者が特に気になっているのはグループ化です。
仕事柄、身の回りに一番多いのはセキュリティに関連した文書ですが、内容も質もかなり偏ったものです。 一般的な文書ではない、いわば「偏った文書」たちをうまくグループ化できるのか。
セキュリティ分野に偏ったと言っても、さまざまな種類の文書があります。 API や通信プロトコルの仕様が書かれた技術文書のようなものもあれば、新たな法令が施行されたなど社会情勢のニュース記事もあるでしょう。 つまり、「偏っている」というのは単なる思い込みかもしれません。
また、一般的な文書では分類精度が上がらないが、文書の種類を限って「本当に偏った文書」のみを対象にすれば精度を上げられる手法が見つかるかもしれません。
このように、気になることはたくさんあります。 自分たちがやりたいことを踏まえながら、それに合いそうな手法を選び、実際に処理対象とする文書を使って実験していくことにしましょう。
トピックモデル
まずは、機械学習の分野から「トピックモデル」と呼ばれるものの概要を紹介します。 機械学習ではありますが、昨今の AI ブームを牽引しているディープラーニングではありません。
文書にはさまざまな種類のものがあります。 今回、対象としているセキュリティ分野に限っても、技術文書やマニュアルと、社会情勢のニュース記事とはまったく違う種類の文書だと考えられます。
また、文書が属するジャンルはひとつとは限りません。 例えば、当記事にジャンルを示すタグを付けるとしたら『自然言語処理, 機械学習, ド素人, チラシの裏』などを付けたくなります。
そして、文書のジャンルによってそこに登場する言葉の種類と頻度(つまり言葉ごとの出現確率)に違いがあるでしょう。 これは極端な例ですが、RFC を読んでいると “MUST” や “SHOULD” などがたくさん出てきます。
こうした観察を背景に、トピックモデルでは、文書は次のようにしてできあがると仮定しています。
まず、ある確率分布に従って文書のトピック(ジャンルのこと)の混ざり具合が決まります。そこからトピックごとの言葉の出現確率を使って文書が言葉で埋まっていき、最終的な文書ができあがります。
たくさんの文書データから、これらトピックや単語に関する確率分布を求めておけば、今ホットなトピックが何か調べたり、トピックに基づいて文書を分類したりということができるわけです。
このような考え方に基づく手法を総称してトピックモデルと呼んでいます。潜在的ディリクレ配分法(LDA)という手法を代表とするさまざまなバリエーションが考え出され、研究されているようです。 筆者が調べた範囲では、文書のメタデータ(著者名など)をモデルに組み込んだ拡張や、確率分布が時間とともに変化していくことを想定した拡張などがありました。
今回は LDA を採用して実験してみることにします。
LDA 適用前に必要な下準備
さて、LDA を使った試行錯誤をしてみたいわけなのですが、LDA のアルゴリズムは「テキストのリストを渡すだけで処理してくれる」ようにはなっていません。 自分で様々な前処理を施してから、数値化したデータ列を渡す必要があります。
必要とされる前処理が何段階かありますので、順に説明します。
- 文書からテキスト本文を抽出する
文書データにはさまざまなフォーマットがあります。 そこから、分類の対象となるテキスト本文を抽出します。 例えば HTML 形式であれば、各種 HTML タグは取り除かなければいけませんし、& で始まる文字参照を実際の文字に置き換える必要があるでしょう。 - テキストを単語に分割
英語の文書であれば、スペースや改行で分割すればおおむね良さそうです。 ただし、例えば一行の文字数制限でハイフネーション後に改行された場合など、いくつか対応が必要なポイントがあります。 活用形を同じ単語として扱いたければ(例: word – words や write – wrote – written)、stemming や lemmatizing といった自然言語処理分野の技術を使います。 日本語文書では単語を分ける明確な区切りがないので、形態素解析と呼ばれる処理を使うことになるでしょう。 - “邪魔”な単語の削除
例えばどの文書にも頻繁に登場する「です/ます」などは文書の内容にはあまり関係なさそうです。 こうした、目的に対して役立ちそうにもない単語でデータが大きく膨らんだところで分析結果が良くなるとは考えにくいので、この段階で削除するのが常套手段のようです。 削除対象とする単語をあらかじめ決めておく(ストップワードと呼ばれます)方式のほか、入力テキスト中で登場回数の多い単語を削除する方式、ごく稀にしか使われない単語も削除する方式なども使われています。 このような語を除去したほうが良いというのは感覚的には首肯できる気がしますが、論理的・数理的根拠があるのかどうかは、調べた範囲ではよくわかりませんでした。 - 単語に ID を割り当て
出現した単語にそれぞれ ID を割り当てて、単語 – ID 間の変換辞書を作成します。 - 文書ごとの ID 別頻度表を作成
文書内の単語の登場回数を数え上げて出現頻度を調べます。 このような単語の出現頻度表を bag-of-words と呼びます。 それぞれの文書ごとにひとつずつ頻度表を作成します。 LDA に実際に渡すのはこれらの頻度票のリストです。 お気づきのとおり bag-of-words では単語の登場順序は考慮していないので、前後関係や文脈は LDA では使われないことがわかります。
それぞれの処理で一般的に使われるアルゴリズムは、オープンソースで公開されている自然言語処理や機械学習のライブラリに実装されています。 そのため、たいていは自分の用途にあったライブラリ関数をそれぞれのステップで選択して使うだけで簡単にプログラムを書くことができます。
今回の実験方針
今回は、この手法を使って実際にセキュリティ分野の文書が自動分類できそうかを試してみることにしました。
自分で日々使えるようにすることを考えて、基本方針は「ユルく」「雑に」「自動化する」です。 それを踏まえていくつかの前提条件をつけました。
- その時点で手元にある文書のみを対象にして、グループ分けする
- テキスト本文の抽出は、機械的にできる範囲で実施する
- 単語分割が楽にできそうな英語文書のみをターゲットにする
データで実験
それでは、実際にトピックモデルを試してみましょう。
今回は元データとして、セキュリティ関連文書の中でもあえて偏りのあるものを選択してみました。
IIJ では四半期ごとに IIR という出版物をリリースしています。 筆者の所属するセキュリティ情報統括室では、そのセキュリティの章を執筆しています。
https://www.iij.ad.jp/dev/report/iir/
IIR Vol.3 以降は英語版もリリースしているので、その原稿を元データとして使用します。
https://www.iij.ad.jp/en/dev/iir/
今回は英語版の開始から最初の 10 号分にあたる、vol.3〜12 をサンプルとして使うことにしました。
データの成形
英語版の PDF からセキュリティの章のテキストを抽出して、節ごとのファイルに分割します。 この作業では、スクリプトで機械的に分割したファイルを確認しながら手作業での修正も実施しました。
本当は手作業を入れたくなかったのですが、PDF から抽出したテキストを眺めてみたら節タイトルをまたいで文章が前後している部分があったため、やむなく手作業を入れました。 手間を省くためには、本文の抽出が簡単にできる形式の文書を手に入れる必要がありそうです。
また、PDF から抽出したデータには表やグラフに含まれる表題やラベル文字列、数値なども含まれています。
本件ではそのようなデータもあえて取り除かず、プログラムによる一律のクリーニングでどこまでできるかを試すことにしました。
このようなテキストファイルに対して、下記の前処理を実施しました。
-
- いわゆる全角文字列が含まれていた場合、半角にする
- ハイフンで終わっている行はハイフネーションされた英単語が途中改行されたものなので、ハイフンを取り除いて接続する
- 改行を取り除き、半角スペースに置き換える
- URL 文字列を取り除く
- 単語の分割と活用形の正規化(lemmatizing)。gensim ライブラリと、そこから呼び出される pattern ライブラリをそのまま使いました。ライブラリの仕様上、ここで名詞、動詞、形容詞、副詞だけが取り出されます
tokens = [re.sub(r'/[A-Z]+$', '', x.decode('utf-8')) for x in gensim.utils.lemmatize(txt)] - ストップワードを取り除く。NLTK のストップワードをそのまま使いました
stopwords = nltk.corpus.stopwords.words('english') tokens = [token for token in tokens if token not in stopwords]
モデル作成
節ごとの分割と、前述した最低限のクリーニングを施したテキストからモデルを作成します。 LDA によるモデル作成では、データを与える前に、あらかじめトピックの数を決めて設定しておく必要があります。 今回の実験用データではひとつの号から 12〜14 個のファイルができました。その内の 3 個ほどは、毎号異なる内容を扱った解説記事です。これらがそれぞれ別のトピックに割り振られることを想定し、ひとまずの値としてトピック数を 20 とします。値の調整は後で検討することにしましょう。
# クリーニング済みのテキストから、単語 - ID 間の変換辞書を作成する dic = gensim.corpora.Dictionary(docs) # 単語の出現頻度表を作成する bow = [dic.doc2bow(doc) for doc in docs] # LDA モデルを作成する lda = gensim.models.ldamodel.LdaModel(bow, id2word=dic, num_topics=20)
これでモデルができあがりました。
モデルの確認
この段階で、できあがったモデルをざっくり確認してみます。
それぞれのトピックで、出現頻度が高い単語 Top 3 は次のようになりました。
トピック番号 第1位 第2位 第3位
00 attack 7.27 server 1.74 information 1.20
01 attack 2.55 information 1.88 incident 1.36
02 attack 4.72 malware 1.76 tcp 1.52
03 incident 1.89 security 1.55 attack 1.44
04 attack 2.58 information 1.81 security 1.62
05 attack 3.55 malware 1.29 information 1.11
06 malware 2.81 used 1.58 vulnerability 1.24
07 attack 3.35 malware 2.06 used 1.64
08 attack 2.71 incident 1.32 malware 1.26
09 attack 2.57 security 1.51 incident 1.50
10 malware 2.09 specimen 1.82 attack 1.48
11 information 2.26 attack 1.79 server 0.94
12 incident 2.40 malware 1.59 security 1.47
13 attack 1.84 information 1.71 malware 1.29
14 attack 4.65 tcp 1.45 malware 1.27
15 malware 1.64 used 1.30 file 1.09
16 attack 2.47 incident 1.04 information 0.97
17 security 1.68 attack 1.49 malware 1.14
18 attack 4.10 information 1.73 malware 1.48
19 vulnerability 1.69 attack 1.62 information 1.28
……元が偏った原稿なだけに、とても偏った単語が並んでいます。
Top が attack になっているトピックが 12 個、2 番目、3 番目を含めると、attack は 17 個のトピックに出現しています。
次に目につくのは malware です。こちらも Top に 3 つ、全体では 12 個のトピックに出現しています。
ちまたの blog 記事や論文などを読んでいると、このモデル作成をした段階で単語の分布を見ることでだいたい傾向がわかる結果になっているものが多いです。 トピックの上位に出てくるキーワードがこんなに偏ったモデルができてしまって、果たしてうまく文書の分類ができているのでしょうか?
分類を推定
では、このモデルを使って、ターゲットファイル群のトピックを計算してみます。
ファイルごとに計算されたトピックの分布をヒートマップで表示すると下記のようになります。
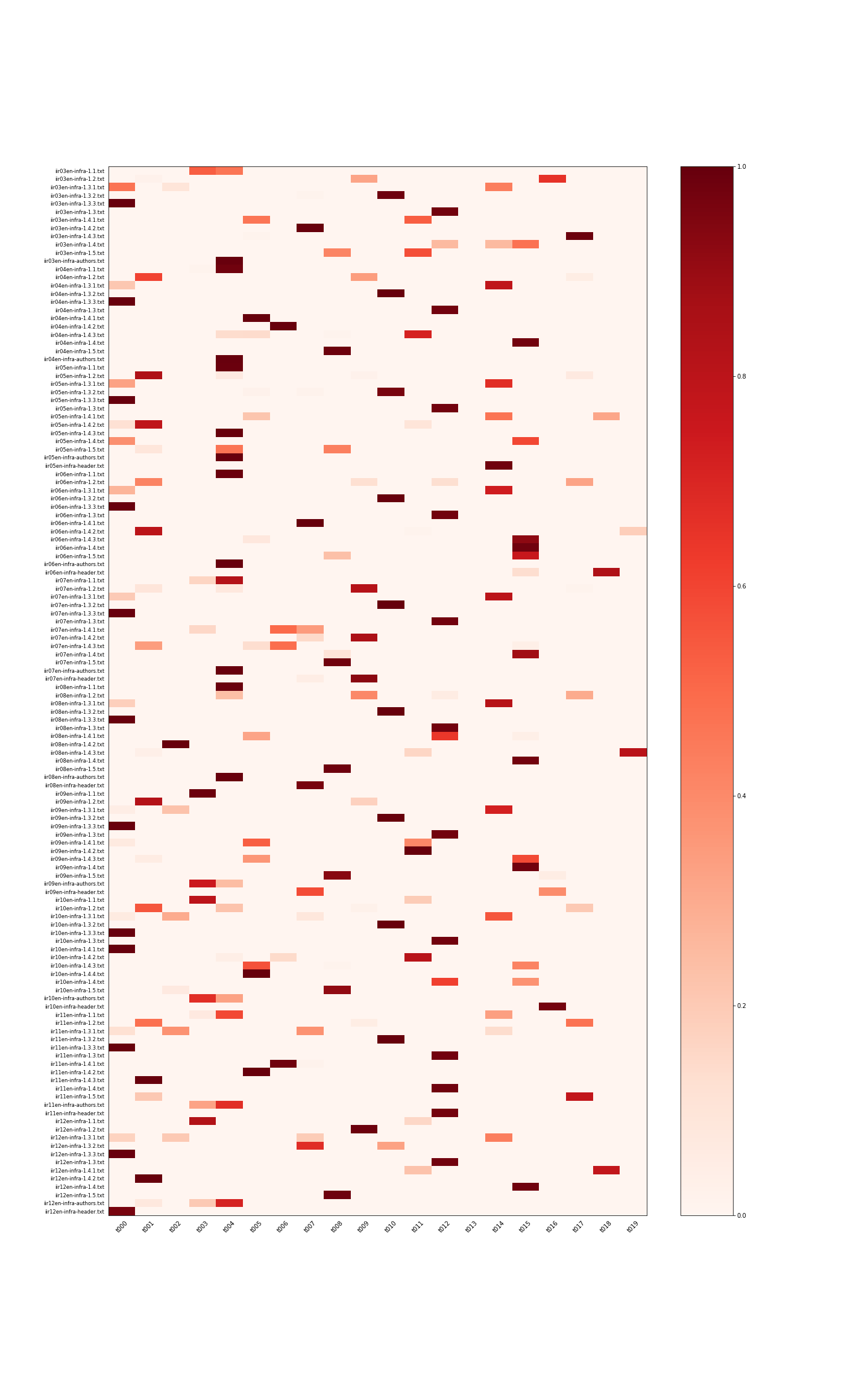
それぞれの文書でトピックごとの推定値が計算できていることが見てとれます。
それでは、各節ごとの分析をいくつかピックアップして見てみましょう。

1.1 節は序文です。頭に IIJ や IIR の説明があり、その後にこの号では何をレポートしたかを簡単に書いています。 トピック分布の微妙なばらつきは、後半の違いによるものと考えられます。

1.3.3 節は SQL インジェクション攻撃の観測情報です。 毎号同じ内容について状況や数値の変化などをレポートしているため内容のばらつきが少なく、トピックの分布もほとんど揃っています。

同じように、ハニーポットの観測情報をレポートしている 1.3.2 節ですが、こちらでは IIR 12 号のみがずれた結果になりました。 ほぼ同じことを書いているのになぜ…… と本文を見てみたところ、12 号から Dionaea を観測システムに取り入れており、その解説などが追加されていました。 トピックモデルが内容の変更をちゃんととらえられていることがわかりますね。

1.4 節はフォーカスリサーチで、毎号 3 つほどの記事があり、それぞれまったく違う内容を違う著者が書いています。 毎号のトピック分布はバラバラになり、傾向が全くなさそうなのが見てとれます。
全体として、序文や著者プロフィールなど、元々文章のばらつきが少ない箇所に関して同じトピックのパラメータが強く反応していることが見てとれます。 また、1.3 節のように、元となるデータは変化しているけれど定点観測的な分析を行っている部分に関しては、やはり本文の変化が比較的少ないために同じパラメータが強く出ていることも読み取れます。 逆に、毎号別のトピックを扱っている 1.4 節に関しては、強く出るパラメーターもバラバラになる傾向がわかりました。
つづく
次回、ここで作成したモデルの内容をもう少し詳細に分析してみます。