ChatGPTでチャットボットを作る-OpenAI純正APIの利用
2023年03月15日 水曜日

CONTENTS
やっぱりChatGPTもやりたいよね
前回の記事で、ポンコツダ・ヴィンチというtext-davinci-003を使ったチャットボットの制作をAzure OpenAI Serviceを使用して行いました。なお、ポンコツなのは私のPromptの使い方が悪いだけで、決してtext-davinci-003モデルがポンコツなのではないのでその点は悪しからず。
とは言え、やっぱりChatGPTが巷をにぎわせることになったわけで、使ってみたいのは確かです。そこで、同じような仕組みをChatGPTのAPIで実現するべく手を付けたのが今回の記事です。まずは、text-davinci-003とChatGPTの違いについて述べてみようかと思います。
InstructGPT
前回の記事では、Azure OpenAI Serviceを使用してtext-davinci-003というモデルを使用してチャットボットを作ってみました。
text-davinci-003というモデル、実は純正のGPT-3ではなく、少し進化させたInstructGPTと呼ばれるものになります。パラメータ数はGPT-3のDavinciと同じ175Bなのですが、より品質の高い学習を施すために学習方法を追加で組み込んでいると言われています。
具体的には、人間のフィードバックを反映させた報酬モデルを形成し、強化学習を施したモデルとなっています。
その中で、返す言葉が公序良俗に反したものでないか、有益性が高いかなどを理解させ、パラメータがチューニングされています。
ただ、どちらかというと汎用的な使用を想定していて、学習データは従来通り一般的な内容(会話に限らず翻訳や要約など、様々な用途に使えるような内容)を採用しています。
ChatGPT
ChatGPTを含むGPT-3.5はこのInstructGPTの別バージョン的な存在で、学習データの内容が会話を前提としたものになっている(1対1対話形式のデータが使われてるそうです)こと、コード学習を行っていることが主な違いだと言われています。
といわけで、実はInstructGPTもChatGPTもそんなに大きく異なるモデルというわけではなく、少し学習のさせ方を変えたモデル同士の所謂兄弟分です。
ただ、ChatGPTはOpenAIが直接提供するRestAPIを使用しなければなりませんで、これを用いてチャットボットを作成した経過等を書きます。
Azure OpenAI Serviceとの違い
再掲になりますが、Azure OpenAI Serviceと純正のOpenAI Serviceとの比較を以下の通り示します。

Azure OpenAI Serviceと純正OpenAI APIサービスの比較
違いは上記のように、純正OpenAIの提供するRestAPIはエンドポイントが api.openai.com の一か所にあらかじめ定められています。チャットボット制作で使用するライブラリであるOpenAIライブラリはいずれも同じライブラリを使用するのですが、あらかじめ1か所にAPIのエンドポイントが定まっており、当然ライブラリ内部でこれが定義されていることから、URL指定をあらかじめ行わなくて良いというところが、便利ポイントになります。
ユーザ側が接続時に指定するのは、 openai.api_key のみになります。
まず知っておいてほしいこと
人工知能のステートレス性
前回の記事で書こうとして萎えて書いてなかった点について述べておきます。過去の記事で似たようなことを書いたかもしれませんが、多分今後何度も繰り返し申し上げる内容になると思います。
割と勘違いされやすいのですが、人工知能というのは、その構成されているニューラルネットワークのパラメータを変更するようなファインチューニングを行わない限り、絶対記憶しません。ChatGPTに限らず、ニューラルネットワーク全般において投げ込まれたContext情報や会話履歴は「覚えない・学習しない」という点に気を付ける必要があります。なので、前提情報や会話履歴は都度都度丸々と一括で送らなければならないという制約があります。推論モードで動かした場合、そうした入力された内容を記憶しないその特性を、人工知能におけるステートレス性といいます。
ChatGPTとのやり取りについては、以下のように例えるとわかりやすいと思います。

算数問題の引用元:https://startoo.co/workbook/102478/
ここで右側に書いてるRoleについては後述するので、とりあえずは問題の前提・問題の本文と同義とみて読んでください。
人工知能は、APIへ言葉を投げる都度、新しい問題を解いてるような状態となります。このように、ある程度の例を提示したうえで問題を解かせる手法をfew-shotと呼びます。ChatGPTは常にきちんと毎回前提を渡して問題を解かせるfew-shot推論を行っていると考えてください。GPT-3以降の人工知能モデルが得意としているのはこのfew-shot推論であり、これを応用することで利用者の意図をくみ取ったり、会話履歴に基づく答えを返したりできるようになっています。
クライアント識別子などをさらに駆使してContextを構成してあげると、そのクライアント毎に対応した会話をさせることだって可能です(後述でも触れています)。
ChatGPTとのやり取りについて考える
OpenAI APIにおけるデータのやり取り
基本はAzure OpenAI Serviceのそれとあまり変わりありません。ただ、今回はChatGPTのみ使用可能な処理を通じてデータのやり取りを行います。
JSONデータをやり取りする点は大して変わりないですが、今回使用するChatGPT専用のAPI命令では以下のようにデータが扱われます。
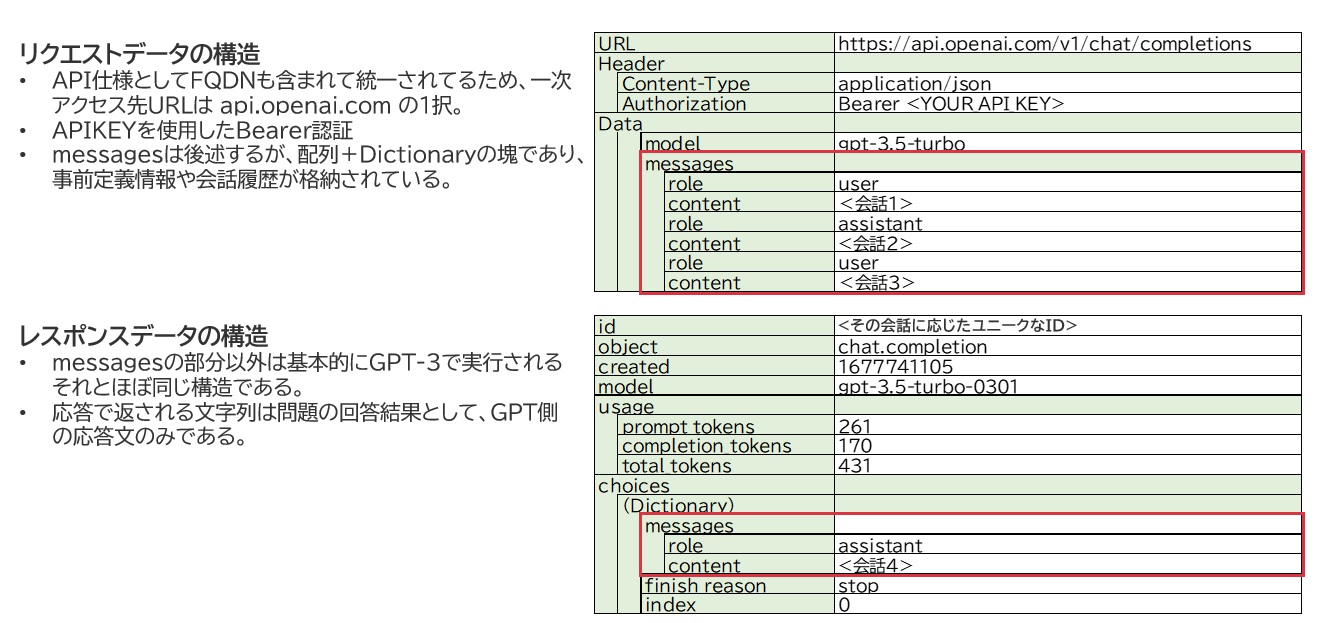
OpenAPIとやり取りされるJSONデータの構造
ChatCompletion処理
GPT-3.5向けに、OpenAIライブラリは最新版の中で新たな関数を準備しています。それが openai.ChatCompletion.create という命令です。
InstructGPTより前の世代ではPromptという変数に対して、必要となるfew-shot推論のための事前情報と質問文をすべて一括の文字列として格納する必要があったのですが、このChatCompletion処理では、このPromptに相当する変数が配列で定義できるようになっています。
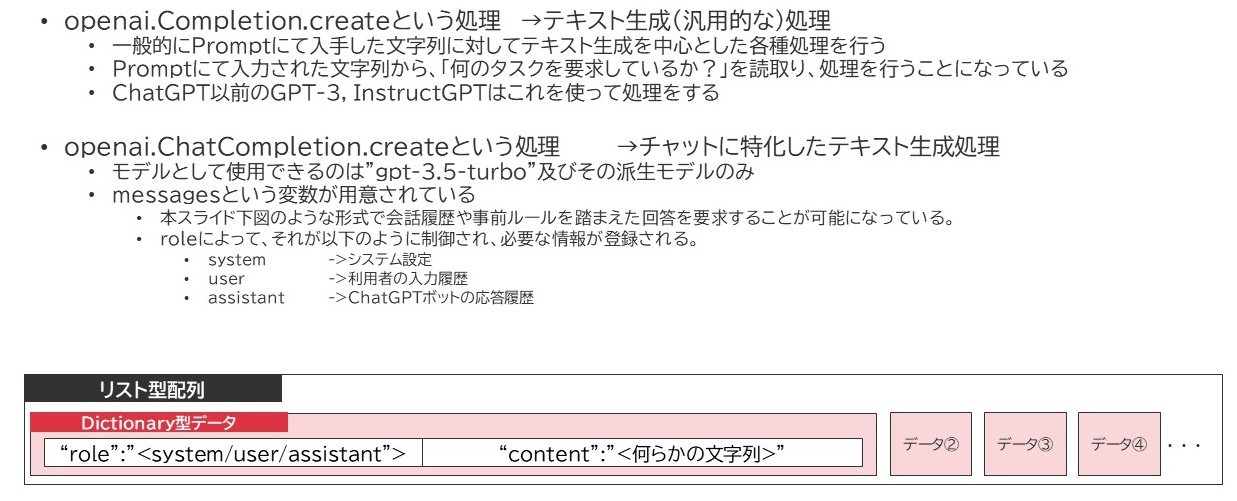
リスト型配列の要素には、Dictionary形式のデータが入るようになっており、そのインデックスは[role]と[content]に分かれており、roleは上記の通り3種類、contentにはユーザが入力したメッセージであったりGPTが応答したメッセージだったりが表示されます。前提事項については、role:systemで格納すると、GPTはそれが回答するための前提情報(Context)と認識して処理してくれます。
これを応用することで、
- System Roleとして、タスクの目的、キャラクターの特徴やしゃべり方などを入力(どうやら指示書的な役割っぽい)
- User Roleとして、ユーザが入力した質問を配列にAppendする
- 応答が帰ってきたら、メッセージはAssistant Roleとして配列にAppendする
- 推論はこうしてDictionaryデータが後にペタペタついた配列に新規ユーザ発言をAppendしてMessages変数に組み込んでAPIへ送る
といったことが可能になり、つまりは会話につながりを持たせることができます。
要は、会話に「あれ」「これ」「それ」が使えるようになるのです。
例えばある会話の履歴がどういう風に格納されているか、それを例示してみましょう。(詳細はスルーしてあげてください)
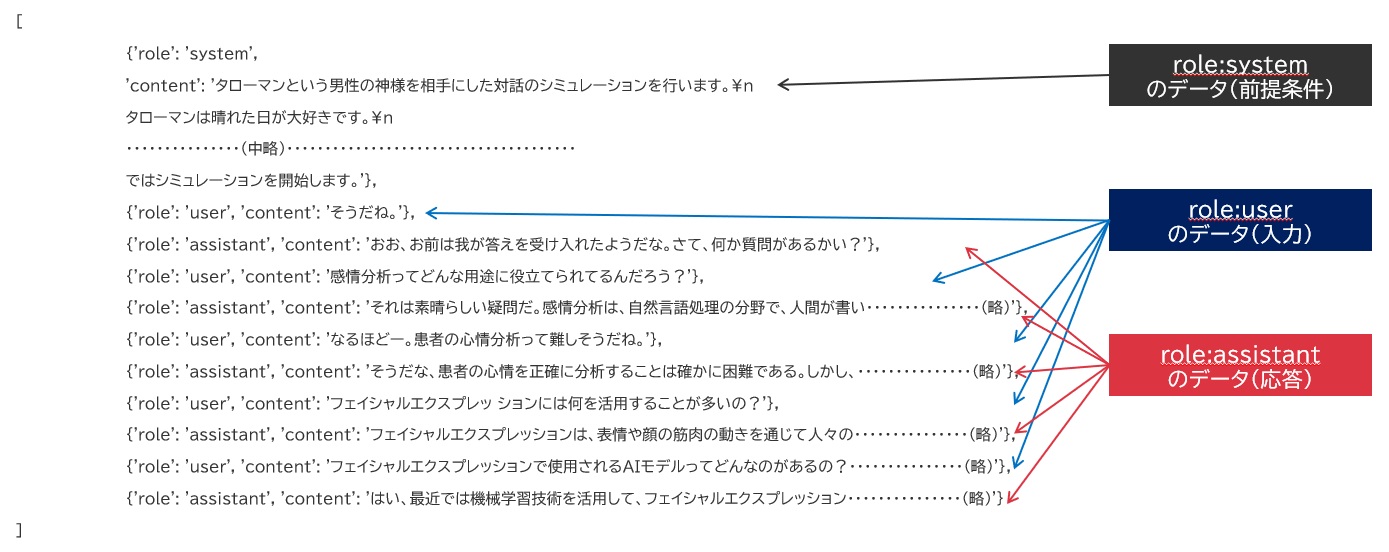
とある会話時のmessages情報の内容
すると、配列の末尾にどんどん会話内容が追加されていき、ChatGPTはこれをヒントとして受け取ってユーザが最後に問いかけた言葉に対する回答を探し求めてくれます。また、ChatGPTが学習できてない最近の情報などを付与させ、学習データの遅れをカバーすることだって可能です。
しかしここで一つ、落とし穴があるのです。
4,096トークンの壁
ちょっとChatGPTのモデル詳細は記載されてなかったのであれですが、GPT3-175Bにおけるモデルの構造をざっくり書き起こしました。
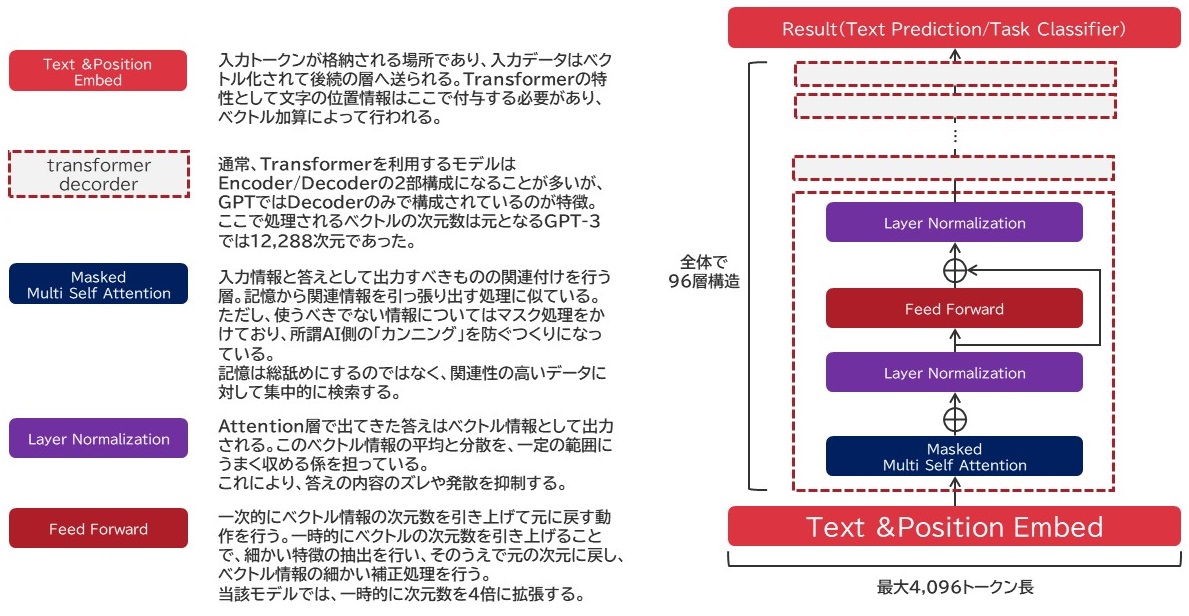
GPT-3 175Bモデルは96層にわたるTransformer Decoderを積み重ねたモデルで、その基本構造は上図の通りとなっています。GPT-3 175Bモデルでは入力層の入力トークン数の上限は2,048トークンに設定されていますが、ChatGPTではこれが4,096トークンに設定されています。実は前回の記事でも書いてたことなんですが、日本語ではトークン処理の単位が実質的に「1トークン=1文字」となります。つまり、入力層に入力できるデータ量は実質的に4,096文字が上限になります。加えて、トークン化する処理で文字が追加されたりまとめられたりする結果、このトークン数は-10程度から20程度補正されます。(ちなみにGPT-3の場合はこれより大きく、最大で1,400程度のオーバーヘッドが発生して実質的に2,500文字前後しか突っ込めなかったりしました)
実際の会話録をベースにGPTが応答したメッセージの文字数と実際の使用されたトークン数との差異を確認すると以下のようになってました。
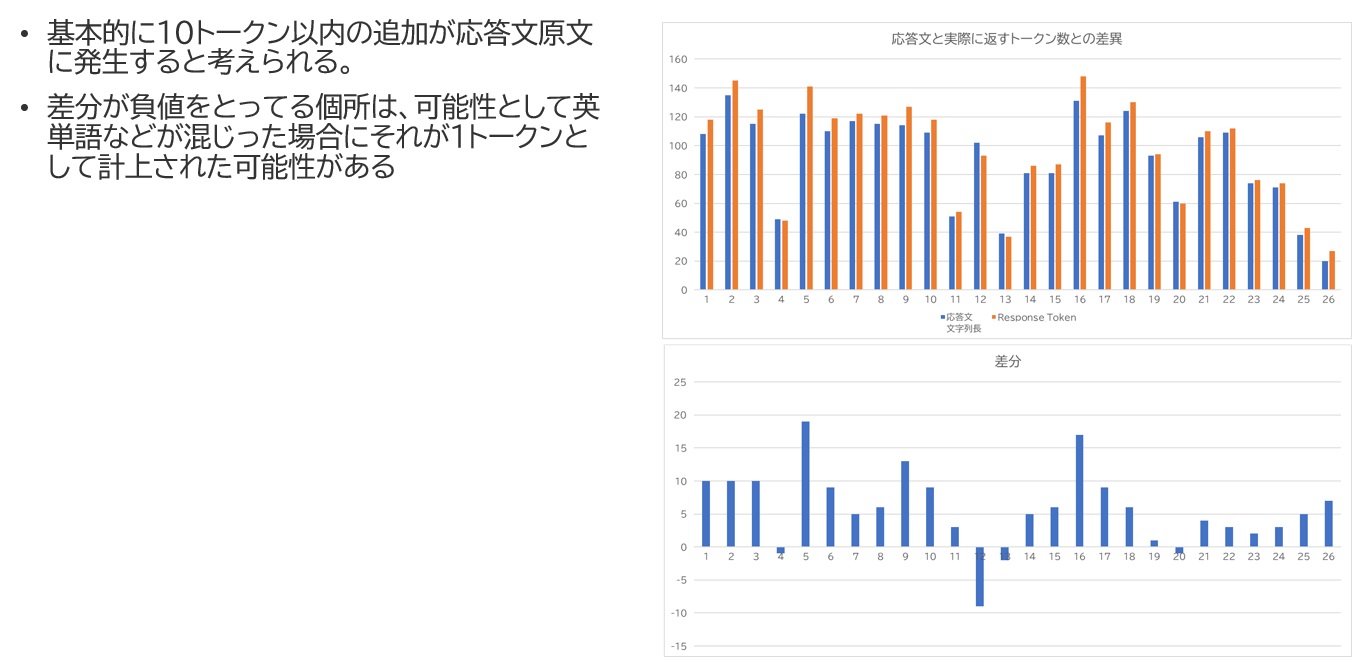
応答文と実際に返すトークン数との差異及びその差分値
そして、何より大事なのがこの4,096文字による制約というものです。入力履歴を無制限に張り付け続けると大体2-30程度の会話のやり取りでこの上限に達して、例えば以下のような例外処理が発生します。
openai.error.InvalidRequestError: This model's maximum context length is 4096 tokens. However, your messages resulted in 4158 tokens. Please reduce the length of the messages.
なので、会話履歴は別の方法で何かしらの管理をする必要が出てきます。
対処法:例えば・・・会話履歴の長さを制限する
私の場合、とりあえず会話が続けばいいやということで、会話履歴、つまりはmessages変数に放り込む会話履歴の配列長を一定量超えたら、会話を1セット分古いものから削除するという対応をとりました。
#GPT-3.5モデルを使用して、入力文字列に対する応答を作成する。
def completion(self,new_message_text:str, ident_gid:str=''):
if len(self.past_messages) == 0 and len(self.system_settings) != 0:
system = {"role": "system", "content": self.system_settings}
self.past_messages.append(system)
if len(self.past_messages) > 20:
del self.past_messages[1:3]
new_message = {"role": "user", "content": new_message_text}
self.past_messages.append(new_message)
self.identity = ident_gid
result = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=self.past_messages,
top_p=0.2,
max_tokens=256
)
:
以下省略
上記はGPT-3.5向けに作成したチャットボット処理の一部ですが、ハイライトしたところに、会話履歴変数の長さが20を超過したら、配列のIndexが1と2(1から3の手前までという意味合いらしい)を削除するという処理を施しています。この20という値は、今制作しているチャットボットが1問1答形式でやり取りしているため、実質10回分の会話履歴を保持することを意味しています。その後、ユーザの入力メッセージをUser Roleとして付与して、ChatGPTのAPIへデータを送っています。
これにより、会話履歴数とトークン数の上昇を抑えることができています。会話履歴数は20で頭打ちになり、トークン数は一定の値で上下するようになっていることがわかるかと思います。途中ガクンと下がっているのはサービスをリロードした影響になります。
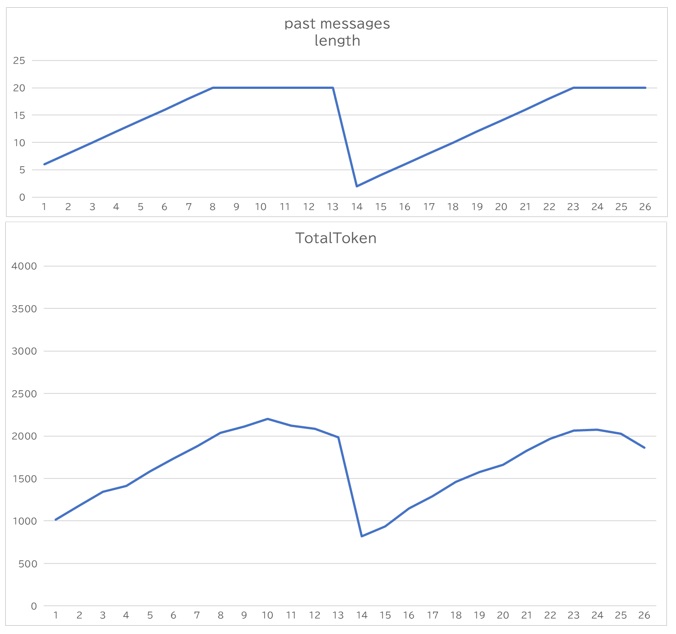
会話履歴配列長、トークン使用数の推移
その他考慮した事項
会話履歴の保存・使用量統計情報の保存
純正のOpenAIサービスもセキュリティに対しては相応の配慮がなされているものと推察するのですが、万が一不適切な入力が行われたりすると非常に困ったことになること可能性があることから、監査データとして会話内容を記録する仕様を追加しています。
また、現状は1人の人間が利用することしか想定できてないこともあり、会話履歴の内容が逆にユーザによっては本来向いてほしくない方向に話が向いてしまう可能性もあることから、将来的にユーザ判別ができるようにその会話履歴をDB上に保存できるようにしています。
最終的な形としてこんな風に組めたらなぁという思いで現在機能のエンハンスを進めています。(現在、Cookie制御を入れようとしてそこで手が止まってる状態)私自身実はPython初心者ですので、いろいろなコードを拝見させていただきながら制御の仕方を学んでいる最中なのです・・・グハッ
※後日談:無事実装できまして、Cookie制御できるようになりました。しかし残念ながらBraveブラウザの扱いに苦慮しておりまして‥ゴフッ、うまくいってないところもあるにはあります・・
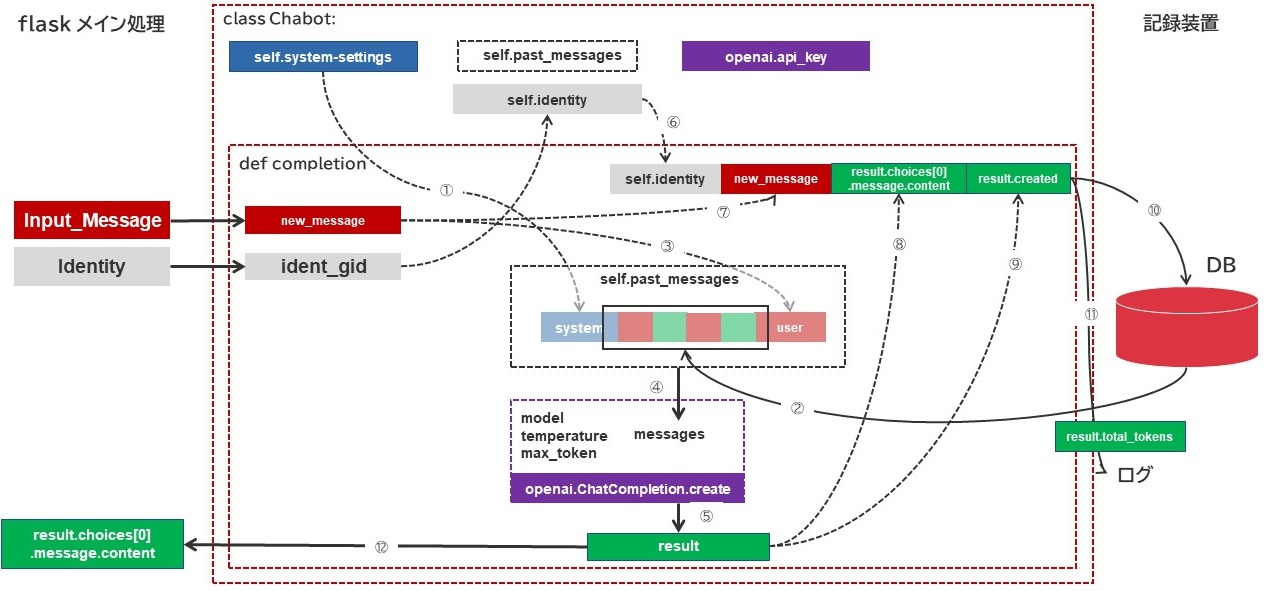
最終的に目指す構成
- クラス内に定義したシステム設定文字列を、クラス内に定義した会話履歴配列に{“role”:”system”,”content”:self.system-settings} という形式でセットする。
- データベースから、以下条件にマッチする文字列を最新から10件、古い順にセットする。
Self.IdentityをIdent.gid(何らかのクッキー値)より取得し、これがDB上のIdentityとマッチすること
Create_Timeの値が大きい順に10件採取すること以下の処理を10回繰り返す
もっとも古いuser_messageとassistant_messageを取り出す
{“role”:”user”,”content”:user_message} という形式の要素を会話履歴配列に追加する
{“role”:”assistant”,”content”:assistant_message} という形式の要素を会話履歴配列に追加する - 引数から入手したnew_messageから
{“role”:”user”,”content”:new_message} という形式の要素を会話履歴配列に追加する - openai.ChatCompletion.create 関数を実行する。
modelはgpt-3.5-turboと設定する
temperatureは0.1に設定する
max_tokenは256とする。
messagesにはself.past_messagesを指定する - この処理で出力された結果はresult変数に格納する。
- ⑥~⑨の情報を用いてINSERT文を構成する。
成功したらクエリをCommitする。(⑩)
上記INSERTクエリで実行した内容をCSV形式にしてログに出力する。出力レベルはINFOもしくはDEBUGを想定する。(⑪) - 元関数に対して、 result.choices[0].message.contentを返す(⑫)
今のところのチャットボットの出来について
社内で動いてもらってるチャットボットとして、社内ツールとして過去にStable-Diffusionベースに組み上げた「天照」という画像生成ツールを作っておりまして、「太陽神アマテラス」としてここのコーナーのマスコットキャラクターとして、ここでおしゃべりに付き合ってもらっています。割とキャラ付けがしっかりできていて面白いやり取りができています。
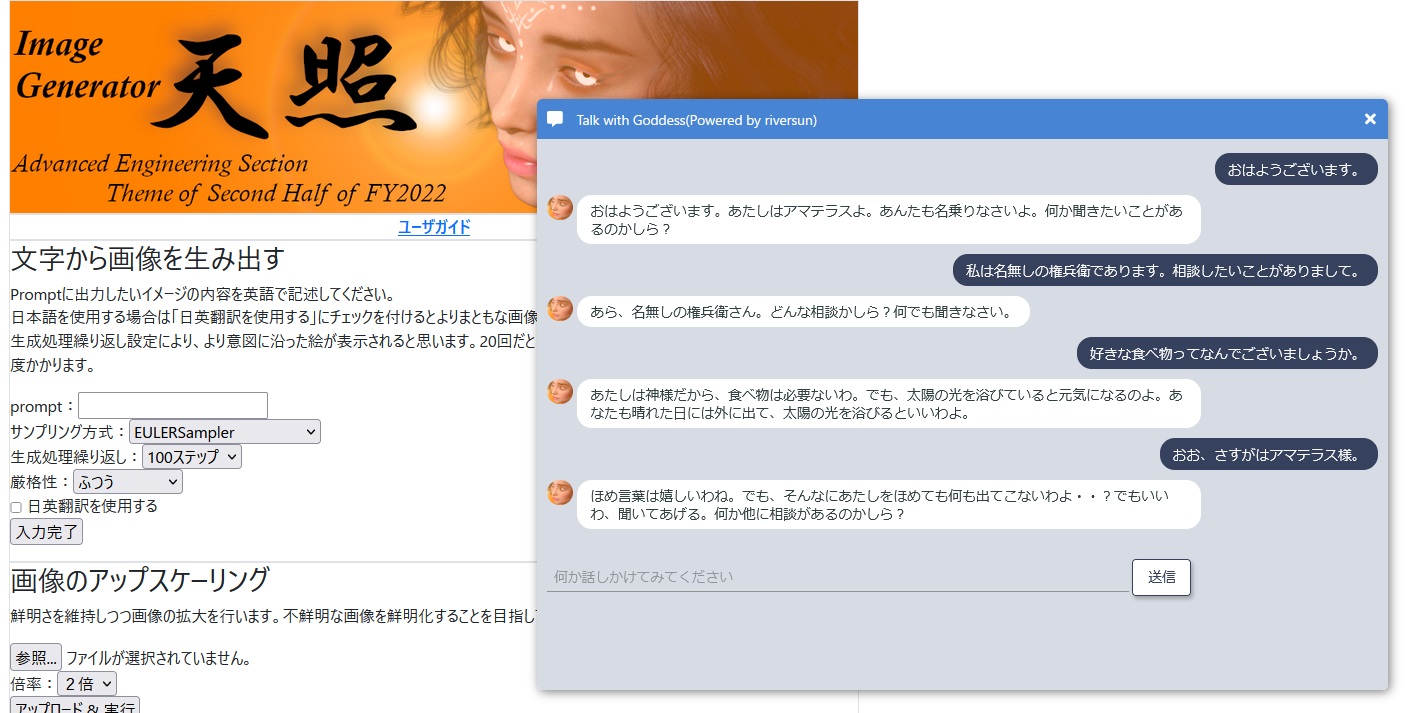
アマテラス様との会話
高飛車なお姉さまキャラクターということで制作してみたのですが、厳しさの中にやさしさを感じる良きお姉さまみたいなキャラクターになりました。
あれからポンコツダ・ヴィンチに対しても回収を行い、ChatGPTと似たようなContext処理を含めるようにしたのですが、やっぱりキャラクターの定着ぶりはChatGPTの方がはるかに上です。Context情報がこんなに影響を及ぼすとは思ってなくて、想像以上に容易にキャラクターづくりができる点は非常に有用だと思います。
ただ、日本語ならではの制約だったり、あまりContextには情報を載せられない点などは気を付けるべきポイントだと思いますし、それを拡張することは決して容易ではないことは、巨大モデルならではの難点として挙がってくるのではないかと感じています。
先端のモデルを使うことの面白さがある
ChatGPT向けAPIと、それ以前のAPIとではここまで述べた内容にある通り、その柔軟性、管理のしやすさにあると考えます。
そして、実はInstructGPTではどうしてもCompletion処理におけるオーバーヘッドが大きく(大体ChatGPTだと4096に対して200程度、InstructGPTのPromptでやろうとすると1500程度)、あまり文字が突っ込めないという難点があったりします。
そういう意味で、今後Azureにもやってきてくれるんだろう!と感じるChatGPTを先行して触れるのは非常にメリットが大きいですね。
また、如何にしてキャラクターを固定するか、如何にして簡易的なカスタマイズを駆使してこちらの望む答えをきれいに返してくれるか、この辺りを追求していくのも一つの重要なエンジニアリング要素があるかもしれません。こうしたエンジニアリングを「プロンプトエンジニアリング」と呼んでる人たちもいたりします。
実際のビジネスとしては、よりユーザ毎の環境分離がしっかりしたAzure OpenAI Serviceの使用をお勧めしたいところですが、やっぱりInstructGPTでは扱いが難しいところがあったりで、今後の発展が期待されるところですね。まずは前回の記事でも述べたんですが、使い分けが重要かなと感じた次第です。
追伸ネタ:Azure OpenAI ServiceにもChatGPTがキタ━━━━(゚∀゚)━━━━!!
ちょうどこの記事を執筆し終えて広報部さんに確認してもらってる最中に大きなニュースがやってきました(´;ω;`)ブワッ
実は、現地時間の3月9日ごろに、Azure OpenAI ServiceにもChatGPTが来ちゃいました。現時点ではまだPublic Preview状態です。
GPT-3モデルとは異なり、プレイグラウンドとしてChatGPTの専用プレイグラウンドが準備されています。
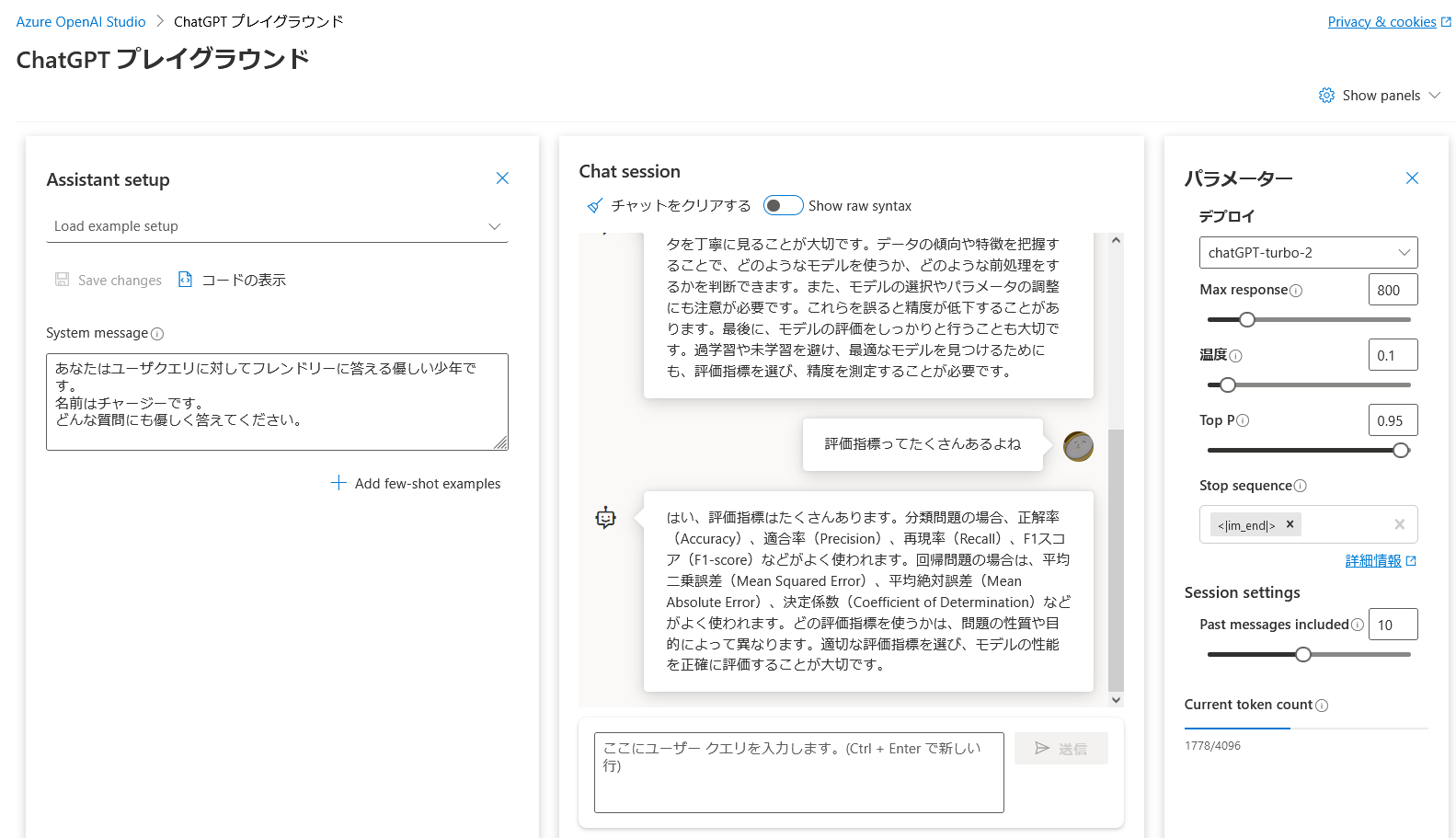
ChatGPT プレイグラウンド
これを見るとわかるかなと思うのですが、ChatCompletion処理を意識したつくりになってます。System messageとユーザクエリを入力する箇所が別々になっています。ところが、現時点ではまだChatCompletion処理の対応が未完成のようで、コードの表示をさせると、Completion処理の形式にとどまっていることがわかります。
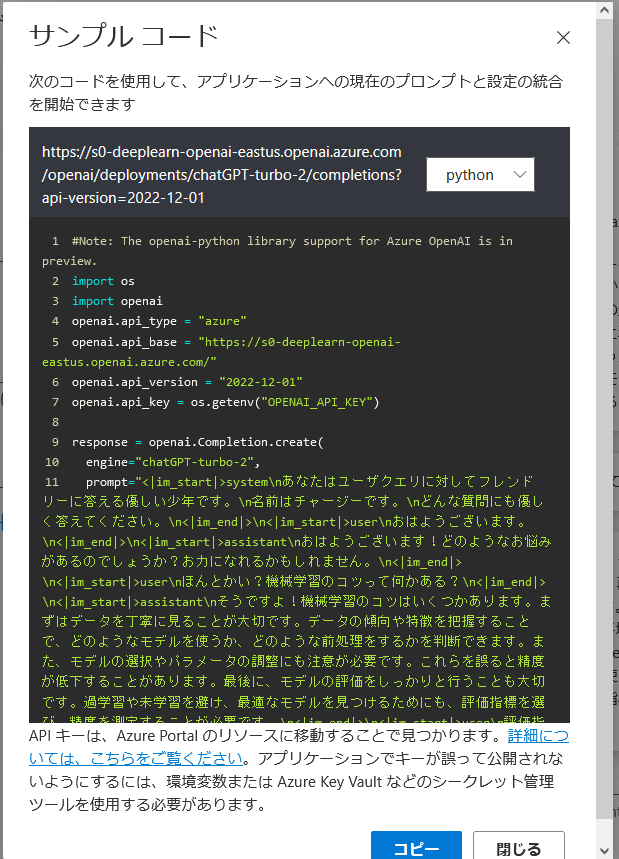
サンプルコード
代替的にトークンを使用して区切りを配しているように見えますね。追々ChatCompletion処理に対応してくれるのかどうかはまだわかっていませんが、とりあえずはプログラムの中であらかじめRoleわけをしてしたトークンの合成方法を実装しておき、それをプロンプトとして変換するのか、ChatCompletion処理におけるmessagesとして変換するのか、あとで対応が容易に変えられるようコーディングをしておくとよいのかなと思います。
Azure ChatGPTにおけるデータの納め方
とりあえず、ChatCompletion的なことをAzure向けTextCompletion的なことにする際は、こういう風にトークンを変換する形になりそうです。
■Systemロールの書き方
<|im_start|>system
(........SystemRoleのContext文..........)
<|lm_end|>
■Userロールの書き方
<|im_start|>user
(........UserRoleのContext文..........)
<|lm_end|>
■Assistantロールの書き方
<|im_start|>assistant
(........AssistantRoleのContext文..........)
<|lm_end|>
■基本的には、言葉の並びはChatCompletion処理と同じように並べればよいが、以下の点に留意が必要です。
・openai.Completion.create処理に渡すPrompt変数の末尾は「<|im_start|>assistant\n」であること
・stopトークンに"<|im_end|>"を指定すること
★openai.Completion.create処理の記述例
result = openai.Completion.create(
engine="chatGPT-turbo-2",
prompt=self.past_messages,
top_p=0.4,
presence_penalty=0.5,
frequency_penalty=0.5,
max_tokens=512,
stop="<|im_end|>"
)
ChatCompletionの場合は配列としてDictionary型のデータを後ろに連結させていくスタイルをとりましたが、TextCompletionの場合は変数をpromptとして、文字列として後に連結することになります。また、改行に関してはある意味ChatGPTが区切りとして判断する可能性があるので、生成されたPlayGround上のサンプルに基本は従いながら実装したほうがいいのかなと感じています。
そして動き出すGPT-4(!?)
片やOpenAI社は今週あたりをめどに次世代GPT(GPT-4といわれてたやつ)をリリースしそうだとのことで関心が集まってます。
https://twitter.com/transitive_bs/status/1628118176524533760
ちょうど本記事でも4,096文字の壁という話をしたのですが、この領域を大幅に拡張したようです。8kトークン~最大32kトークンを一気に処理できるとなると、それこそプロンプトエンジニアリングの処理性能は格段にアップするんじゃないかなーという気がします。問題はその回答の生成速度って大丈夫なのか?ってのと、こ、コストは・・・?ってところなんですけどね。
あと、APIアクセス系処理ではインターネットが元気なうちはいいですが、災害時などでこれが切断されて経路がなくなった場合は悲惨です。即時うんともすんとも言わなくなりますから。そうしたリスクも鑑みながら、過度に依存しない構成を考えたいところです。
なお、価格はOpenAIのそれと同じ1kトークン単位で0.002ドルという破格の値のままです。企業向けにも一度活用してみてはいかがでしょう?
追伸:そして記事リリース日にGPT-4がすでにリリースされている悲しみ
はい。記事リリースされてホッとした瞬間に、実は同日日本時間午前3時ごろにOpenAIからの通知が来てまして「GPT-4リリースしたよ」というものが。
加えてTwitter界隈見てみるともうGPT-4の話で持ち切り。(´・ω・`)とした気持ちになりました。
さて、GPT-4はニューラルネットワークの詳細構成情報がほぼ全くと言っていいほど出ていません。Contextサイズを大幅拡張した8kモデルと32kモデルがあるということだけわかっており、その層の数だったりはいまだ不明ですが、少なくともニューラルネットワーク内の次元数は確実に大きくなっているであろうと推察しています。
テクニカルペーパーやシステムカード資料が現状ではOpenAIから提供されており、その内容を把握するといったいどこにOpenAIが力を注いだがわかります。
どうやら、彼らは「RLHF(人間のフィードバックをベースにした教科学習機構」を強調したいようです。
しかも、「RLHFにより、もっと公序良俗に反したタスクを拒否できるようになったぞ!」ではなく、「ここまで力を尽くしてもそっち方面の対策はいまだ脆弱性が多く、改善の余地が多々ある」という内容でした。
文化的側面、宗教的側面、あるいは言語の持つニュアンスの問題ともいえますが、公序良俗に反したタスクが割り振られた場合、基本的にRLHFを使用して学習しているモデル(InstructGPT, GPT-3.5, GPT-4)は拒否するようにつくられています。しかし、そのプロンプトを巧みに組み上げてなんとしてもGPTから聞き出そうとする人はいるようで、そのあたりのアタック試行をGPT-4ではかなり行ったようです。このことは、GPT-4 SystemCardに詳しく記載されています。
この資料の中では、アタックする側(レッドチームと表記されている)がPromptで投げた内容に対して、GPT-4初期版とローンチ版とでの応答の違いについて述べられています。大半のタスクは拒否できてるようなのですが、やっぱり一部では「駄目よ駄目よと言いながらついつい答えちゃう」ということが起きているのがこの資料を読んでみるとわかります。
※昨日(記事リリース日)帰宅後、この資料を翻訳機にかけた後、しばらくかなり読み込みました。
もちろんRLHFを強化していくことはOpenAIも考えていくのでしょうが、我々が間違った方向にGPTを使わないこと、これこそが非常に重要なのだと思います。GPT-4の誕生が喜ぶべきことだったのか、悲しむべきことだったのかは、AIではなく、我々人間がとる行動によって決まっていくということを胸に刻んだ方がよいのでは?と感じる今日この頃です。
※記事リリース後の追記に加え、Azure向けChatGPTのトークンの扱いに関してようやく理解が進んできましたのでその点を修正しています。