BLIPというモデルについて調べてみた
2024年02月14日 水曜日

CONTENTS
最近Stable-Diffusionが流行っておりますが
久しぶりの投稿です。昨年まで師匠のsyucchinと一緒にGPT&RAGのお仕事をしてまして、しばらくの間燃え尽きて灰になっていました。
当面GPTはお腹いっぱいってことで、再びNarrowモデルに立ち戻って、現在2022年頃にやりこんでたWhisperの振り返りとか、その他ローカルLLMに関する調査を細々とやっていたりします。私は多分特化型モデルともいわれるNarrow Modelが好きなようでしてですね、久々にWhisperやらStable-Diffusion XLやら仕様を掘ってるとやっぱり楽しいようで、最近仕事と好奇心の区別がつかなくなりつつあります。
さて、今回はStable-Diffusionとは逆に、「画像をテキストに変換する」というモデルで、実はすでに昨年からStability-AIが公開してる「japanese-instructblip-alpha」というモデルに興味を持っておりまして。昨年登場してすぐに試す気満々だったのですが、思った以上にメモリ使用量が大きく、当時はまだHuggingfaceのTransformersもまだ対応できてなかったようでしてですね、量子化処理が行えなかったのです。しゃーないので、当面GPTのお仕事にのめりこんで、ようやく今新しいGPUもゲットできたという事でこのモデルに取り組むことができるようになりました。
なぜ逆方向に変換するのにこんなにメモリを食うのか?
実は私の頭が古いんでしょうかね、基本的にDeepLearningがやっていることって、ちょうど「変換器に似たようなもの」という印象を持ってたのですが、このjapanese-instructblip-alphaというモデルはものすごくメモリを消費するなぁと。Stable-Diffusionとか16bit化するだけで消費メモリが3GB程度に抑えられるというのに・・・いったいなぜか?と考えたときにモデルの構造もきちんと押さえておこうかと思いまして。そこでようやく「これ、実はマルチモーダルモデルだったんだ・・」ってことを頭の芯から理解することができました。
最初遊んでたモデルがjapanese-instructblip-alphaなのですが、実際にテキストに書き起こしてみたらこんな応答が返ってきましたですよ。
 実際に出た回答は日本語が先で、英文は昔から定評がある(?)翻訳モデルのmBART-Largeを使って英訳させてます。ちょっと認識のずれがちょろちょろっとあるにしても、おおむね面白い特徴が取り出されていました。ところで、この画像を読み取らせたら即こういう応答が返ってきたのか?というとそういうわけじゃないんですよね。実は画像を読み込ませた後色んな質問をしてるんです。その質問がこちら。
実際に出た回答は日本語が先で、英文は昔から定評がある(?)翻訳モデルのmBART-Largeを使って英訳させてます。ちょっと認識のずれがちょろちょろっとあるにしても、おおむね面白い特徴が取り出されていました。ところで、この画像を読み取らせたら即こういう応答が返ってきたのか?というとそういうわけじゃないんですよね。実は画像を読み込ませた後色んな質問をしてるんです。その質問がこちら。
 はい、このような質問を1つ1つ投げては回答を得て、それを一気に文章として1つにつなげ、さらにそれを要約させたのが上記画像に対する応答だったんですよね。このように、画像を一度読み込ませておいて、その情報を元にQuestion and Answerをさせる手法をVisual Question Answering(略してVQA)と呼ぶそうです。そう、単に画像をその特徴情報からテキストに変換する単純なモデルではなく、このモデルって実は裏側でLLMが動いてるんですね。マジびっくり。
はい、このような質問を1つ1つ投げては回答を得て、それを一気に文章として1つにつなげ、さらにそれを要約させたのが上記画像に対する応答だったんですよね。このように、画像を一度読み込ませておいて、その情報を元にQuestion and Answerをさせる手法をVisual Question Answering(略してVQA)と呼ぶそうです。そう、単に画像をその特徴情報からテキストに変換する単純なモデルではなく、このモデルって実は裏側でLLMが動いてるんですね。マジびっくり。
メモリ消費量もFP16の処理で凡そ20GB強消費します。もしかしてこれってLLMがメモリを食いまくってんの?という事でびっくりしたのですよね。
BLIP:Bootstrap Language Image Pre Training
こういうモデルをひっくるめてBLIPと呼ぶそうで、その元となるモデルはSalesForce Rsearch社から2022年1月にリリースされたBLIP、そこから進化して2023年1月に登場したBLIP-2がベースになってるそうで、特に今回紹介したStability-AIのjapanese-instructblip-alphaモデルはBLIP-2がベースになっています。
当初BLIPは画像からCaptionを取り出すものとして開発されてたようなのですが、そこからさらに学習処理をより高速化させるために、既存のImageEncoder/LLMといったモデルを活用してより効率的なモデル構造を作り上げることで、VQAタスクとして処理させることが可能な形にもっていったようです。単純に画像とCaptionの対応付けを学習させるだけだと、ただひたすらその画像を見て感じたことをずるずるテキストにつづりまくってしまうわけですが(この辺りはGPT-2とか古いバージョンのGPTモデルは似たような動作をしてましたね。しゃべりだしたら止まらないみたいなー)、これにInstruct型の学習をさせることで、要はGPT-3などがChatGPTで使われるようなGPT-3.5的なアライメントを行うような効果を与え、ユーザが聞きたいことだけをきっちり答えてくれるBLIPモデルとして成長したわけですね。
SalesForce Research社がその後出したモデルの1つが instructblip-vicuna-7b(ビキューナ・ビクーナという動物の名前を元にしたモデル)です。このモデルは
- 入力画像をベクトルに変換するImage Encoder
- 最終的に答えを返すLLM Decoder
を両端に持っています。そして中間層にあるのが私もこのモデルを拝見してはじめて知ったのですが、「Q-Former」という層です。
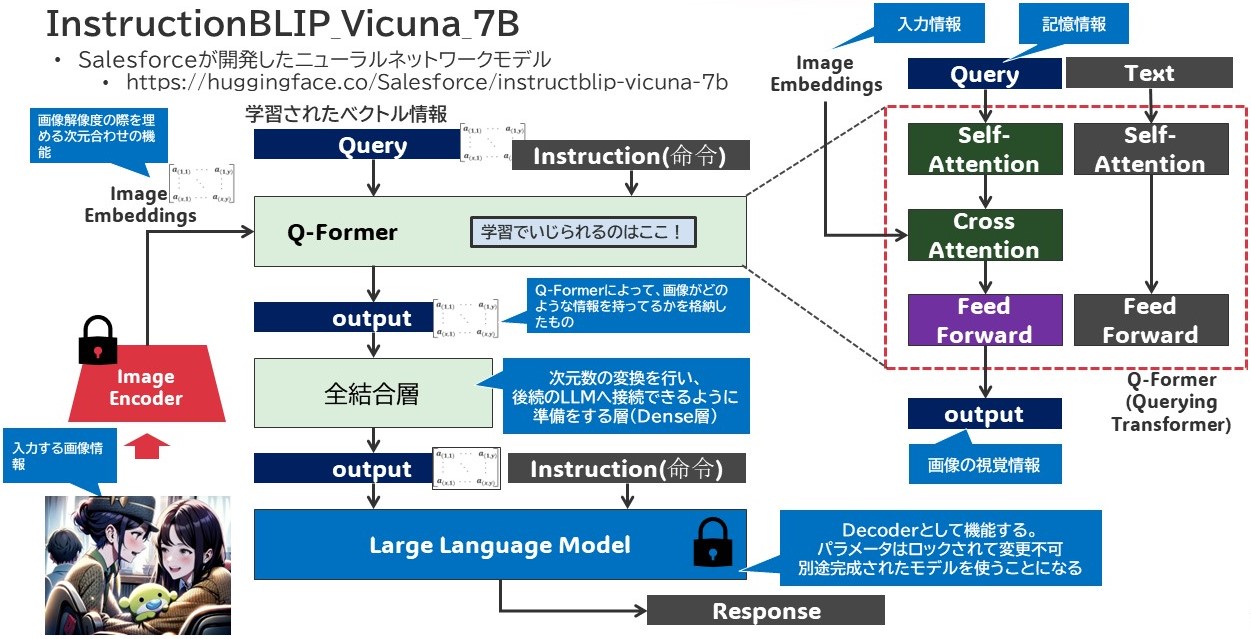 はい、Q-Formerと書かれてる部分がそうなんですが、この部分が「こんな質問が来たらこんな風に答えるとよいよ!」というような視覚情報がまとめられた場所になっており、それがDecoder的存在であるLLMに運ばれて、LLMにとってはまさに「カンペ」として機能します。必要に応じて、Q-Formerが出力した次元にあわせるためにDense層(全結合層)を用いて次元変換を行い、LLMに理解できるようまとめたベクトルをLLMに対して渡すと。
はい、Q-Formerと書かれてる部分がそうなんですが、この部分が「こんな質問が来たらこんな風に答えるとよいよ!」というような視覚情報がまとめられた場所になっており、それがDecoder的存在であるLLMに運ばれて、LLMにとってはまさに「カンペ」として機能します。必要に応じて、Q-Formerが出力した次元にあわせるためにDense層(全結合層)を用いて次元変換を行い、LLMに理解できるようまとめたベクトルをLLMに対して渡すと。
そして、そこにInstruction、つまりは質問なり前提事項などをプロンプト文として放り込むことによって、LLMが質問に答えてくれるんですね。
エンコーダとデコーダはすでにPre-Trainモデルとして呼び出され、あらかじめパラメータはフルロックされます。これにより、学習をしようとするとそのパラメータが操作される部分はQ-Former内に絞られてきて、実際の学習処理に対する負荷はそこにしか及ばない、つまりはそこのニューラルネットワークの構造がシンプルであれば処理負荷も高くなく、処理時間も難しくないじゃんね!っていう作りになってます。
Q-Formerの中身はみてみると一般的なTransformerによく似た構造をとっていて、その横に並行する形でテキストを処理するためのSelfAttention層とFFNで構成されています。この両者間のSelfAttention層同士は互いにメモリ情報を共有できるようにしていて、その学習用途に応じてAttention-Maskがかかるようになっています。
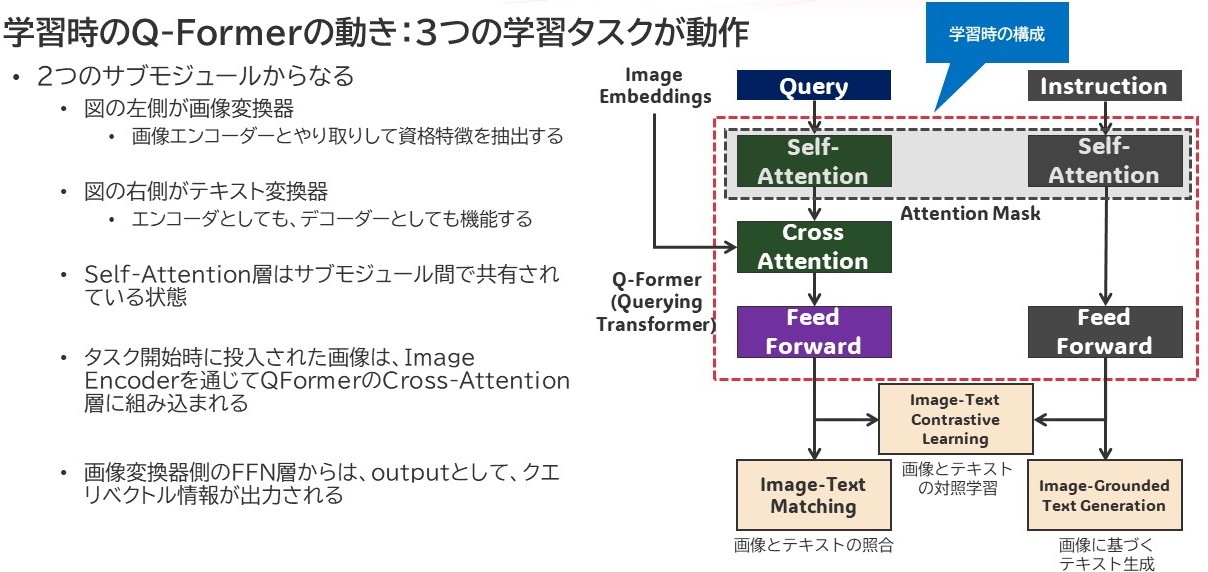 ここからが非常に理解することに苦しむ部分になるんですけど、学習のバリエーションはBLIP-2モデルでは3つありまして、
ここからが非常に理解することに苦しむ部分になるんですけど、学習のバリエーションはBLIP-2モデルでは3つありまして、
- ITC(画像表現とテキスト表現の整合性を学習するタスク)
- ITG(Q-Formerが画像入力を条件として、テキストを生成するように訓練するタスク)
- ITM(画像とテキスト表現間のアライメントを学習するための分類タスク)
を行うことで、学習を進めることになるようです。この辺りの学習のさせ方が、実はQ-Formerってかなり難しいようで、ここに踏み込んだ情報ってなかなか見つかっておりません。基本は頑張ってQ-Formerをゼロから作るというよりは、Pre-TrainされたQ-Formerをうまく活用してLLMがきちんと質問に答えられるように、適切なプロンプトを構築していくこと・・に注力したほうが良いのかもしれないです。
なお、Stability-AIが開発したjapanese-instructblip-alphaというモデルは、そのLLM DecoderにStablity-AI自身が開発したLLM(stabilityai/japanese-stablelm-instruct-alpha-7b)を用いています。そのうえで、Q-Formerに対して日本語テキストを用いた画像学習を行わせていたようです。トークナイザもLLMにあわせたものを使っていて、それ故に単純にvicuna-7bを使うよりは複雑な使い方が求められます。それにしてもどうやって学習させたんだろうね・・・・これ・・。
全体の流れを軽くまとめてみる
今回、最終的にはStable-Diffusion XLを使って画像生成を行う簡易的なWebツールとして以前チャットのキャラクターにもなってもらってた「天照」のバナーをリニューアルさせつつ、このツールにプロンプトを渡す簡易ツールを作成してみたのですが、その際の処理の流れだけざっくり掲載しておきます。
 ちょうど昨年の10月、夫婦で一緒に熊本県八代市にあるくまモンの像が大量に立ってる公園がありまして、そこに行ってきたんですが、その際のワタシの写真をベースに全体の処理構造を追いかけてみました。上記の例では、画像を取り込ませた後にユーザプロンプトとして9つの質問をぶつけています。vicuna-7bモデルは箇条書きを好む癖があり、文章を連結する際にこれが邪魔になるので、極力箇条書きと化しないように○○トークン以内で答えなさいという形でプロンプトに補足をしています。また、分からなければ回答しないようにするよう調整もしています。
ちょうど昨年の10月、夫婦で一緒に熊本県八代市にあるくまモンの像が大量に立ってる公園がありまして、そこに行ってきたんですが、その際のワタシの写真をベースに全体の処理構造を追いかけてみました。上記の例では、画像を取り込ませた後にユーザプロンプトとして9つの質問をぶつけています。vicuna-7bモデルは箇条書きを好む癖があり、文章を連結する際にこれが邪魔になるので、極力箇条書きと化しないように○○トークン以内で答えなさいという形でプロンプトに補足をしています。また、分からなければ回答しないようにするよう調整もしています。
結果的に上記ケースでは9問中5問回答出来ておりまして、これを単純につなげたやたら長い文章を今度は、その画像を知ってる前提で指定トークン数まで要約させます。そうして出てきた要約文をStable-DiffusionXLに流した結果が右下の図です。今回の場合、熊さんに対するイメージが開発者たちとだいぶ違ってしまったのか、ものすごく怖い熊の巨大な像が登場してしまいましたが、当たらずとも大枠としては遠からず・・・な画像ができたんじゃないかな?という気がしないでもないです。
こうしたことから、例えばブログの挿絵とかで、自分が撮影した写真をそのまま貼ると映り込んだ人に迷惑がかかるんじゃないか・・・?とか、自分のプライバシーが・・・とか気になる人には、題材によってはいい具合にデフォルメ出来て、気軽に使える画像に変換できるんじゃないか?ということで、その変化の程度がどの程度のものか・・という所を現在は見極めをしているところです。
もう1つ例を挙げてみよう
例えば以前作った「AI発掘調査隊の画像」なんかを使ってみましょうか。当該ページの画像とはちょいと違いますが、ちょうどあの画像を作成中に候補に残った画像の1つです。(穴がないからということで選考落ちした気がする。)
 こんな感じの画像がもう少し別にあったので、それをベースにBLIPモデルでCaptionをとり、SDXLに通して画像生成させたものがこちらです。この時はjapanese-instruct-blip-alphaも併用してましたので、vicuna-7bと合わせてその結果を載せてみました。
こんな感じの画像がもう少し別にあったので、それをベースにBLIPモデルでCaptionをとり、SDXLに通して画像生成させたものがこちらです。この時はjapanese-instruct-blip-alphaも併用してましたので、vicuna-7bと合わせてその結果を載せてみました。
 いかがでしょう?もう少しはっきりした画像になり、ちょっとアニメ調に寄った見やすい画像になった・・・・そんな気がします。
いかがでしょう?もう少しはっきりした画像になり、ちょっとアニメ調に寄った見やすい画像になった・・・・そんな気がします。
Stable-Diffusion側も細工が必要だった
さて、こうしてBLIPでCaptionをうまいこと取り出すことで、画像の特徴をいい具合に引き出し、なおかつStable-Diffusionにもっていくことで表現の幅が広がりそうな感じになってまいりました。ただ、忘れてはならないのがStable-Diffusionのトークン制限です。実はStable-DiffusionはトークナイザとしてOpenAIが開発したCLIPやその後OSS化されたOpenCLIPを使用しており、その最大長はわずか77トークンと言われています。Stable-Diffusion旧世代からの制限で、これはトークナイザを根本から変えない限りはそのままではうまく取り込んでもらえません。
そこで、Stable-Diffusionにも細工が必要となりました。
私は、Compelというライブラリを使用して、事前にトークナイザ処理とテキストエンコーダを行わせています。Compelには、Conjunctionという機能があり、長いトークンが来た場合に77トークン単位でぶつ切りしてそれぞれをベクトル化し、それを足しこんですべての特徴を取り込もうとする機能があるんです。そして、すでにEmbeddingデータとして成立するベクトルデータを、Stable-Diffusionモデルに突っ込むことで、こちらの書いたプロンプト文をすべて取り込んだ特徴を持つ画像生成を可能としてくれます。
 SDXLの場合、SD1.x/2.xよりも複雑な構造をしてるので、一概にポンとベクトルのサイズは答えづらいところがあるんですが、基本は77×768サイズのベクトルがベースとなってますんで、最終的にこのサイズにさえ収まってしまえば、その後の処理はうまくいくんですね。(工程によっては77×1024)
SDXLの場合、SD1.x/2.xよりも複雑な構造をしてるので、一概にポンとベクトルのサイズは答えづらいところがあるんですが、基本は77×768サイズのベクトルがベースとなってますんで、最終的にこのサイズにさえ収まってしまえば、その後の処理はうまくいくんですね。(工程によっては77×1024)
それを可能とするために77トークン単位で切り出してベクトルの方向性が詰まったデータ同士を足し算し、際立出せるべき特徴は値が大きくなり、打ち消しあう内容が同じ文面にある場合はお互い反対方向の数値を持ってるために数値が惹かれて特徴は小さくなるというわけですね。また、AUTOMATIC1111やFooocusといったWebインタフェースでよく用いられるプロンプトの単語に対するWeight付与がこのツールを通じて行えるようになります。
こうして画像変換ネタをいくつか実行させてみるとも少し良い具合に特徴が拾われるようになりました。こちらはvicuna-7bモデルで変換させています。
 そこそこ良い感じの画像になってきたような気がしますね。
そこそこ良い感じの画像になってきたような気がしますね。
Compelの説明を読んで気づいた人はいると思うんですが、実はこんな回りくどいことをしなくても、もっと簡単に写真の特徴を反映する方法はあります。
Stable-Diffusionを実行するメソッドの引数にEmbeddingデータをそのまま突っ込めるように作られていて、画像データをそのまま所定のサイズを持つベクトルに変換してそれをEmbeddingデータとして入れちゃったらそちらの方がより正確に特徴をとらえて処理してくれるんですよね。
今回はあくまでBLIPモデルを理解することを目的に、Stable-Diffusion XLと少し回りくどいやり方で連携させた次第です。
とは言え、このように動物をきちんと反映させられたり(コーギーちゃんやないけど・・)、ひまわりの花をきちんと描かせたりといったことができるという事は、BLIPはきちんと内容をとらえることを可能としている1つのエビデンスとしてもよいのではないかなと思います。
まとめ
今回、私自身としても初めてマルチモデル構成のAIを取り扱いました。そして、課題もある程度見えてきまして。
とにかく時間がかかるんです。実はBLIPからの回答を得るまでに1分弱の時間がかかるのです。使用したGPUはNVIDIA L4というエントリークラスのGPUなのですが、それでもAda Lovelace世代のチップなので結構な速度が出るはずではあるのですが、何ていうかEncoderやLLM側の性能に引っ張られて質問・回答のサイクルが積み重なれば積み重なるほど時間を要する結果になり。SDXLの処理は凡そ2サイクル回す仕様にしてたこともあり、1分半程度かかってしまいます。
こうしたのって、精緻化するアクションが増えれば増えるほど時間がどんどん増えてしまうので、如何に複雑さを回避して高性能な動かし方をさせるのかについて模索する必要があるのかなと感じました。また、やっぱりベクトルの入力がどんな風なもので、それが内部でどう処理されて外にどういう形で出力されるのか、そうしたものは一定の理解ができてないと、いざAPIが反応しなくなって自力でモデルチューンを必要としたときなど、ある程度の知識がないときついんじゃないかな?という印象も受けています。
今や、DeepLearningで作られるモデルは以前のように単純なパターンマッチング的なものから、複雑に複数のモデルを重ね合わせて動かすとってもインテリジェンスで高機能な代物だらけになってしまいました。なかなか追いつかない世界ですが、鈍足でも堅実に着実にノウハウを積み重ねていきたいと思っています。




