【AI】進化的マージモデルを手軽に作れる「mergekit」というツール
2024年05月23日 木曜日
CONTENTS
進化的マージモデルとは?
これは、Sakana.aiさんが2024年3月21日発表した、「進化的アルゴリズムによる基盤モデルの構築」で述べられた手法を用いて作られたLLMを指しています。
引用すると、「多様な能力を持つ幅広いオープンソースモデルを融合して、新たな基盤モデルを構築するための方法を、進化的アルゴリズムを用いて発見する手法」であるとのことで、その中でも生成されたLLMの一つである EvoLLM-JP は融合元に指定したモデルはベンチマーク成績があまり芳しくないにもかかわらず、融合後のモデルはGPT-3.5に迫る性能を叩き出しました。
Sakana.aiさんでは、その後言語画像モデルとしてEvoVLM-JPを、日本語画像生成モデルとしてEvoSDXL-JPをリリースしています。
今日の人工知能を形作る「モデル」には、モデルを構成する要素に紐付く「重みパラメータ・バイアスパラメータ」と呼ばれるものと、モデルの構造そのものである「モデルデータフロー」というものがあり、この論文の中で、前者をマージすることをPS(Parameter Space)、後者をマージすることをDFS(Data Flow Space)と呼んでおり、PS・DFS・両方併用の3パターンで融合モデルを作り、最も精度(accuracy)の高いモデルを採用するという行為を繰り返しながら世代交代させることで、自律的にモデルを進化させることを目指した内容となっています。
どのパラメータをどう弄ればいいか?その探索はCMA-ES(共分散行列適応進化戦略)という最適化手法を用いて行われているそうです。
mergekit というツール
そして、LLM界隈で知られたツールが別途ありまして、Arcee AIという企業がリリースしている mergekit というツールがあります。
実は2024年4月23日にこの mergekit に進化的モデルマージ機能が追加実装されました。で、同社のブログでその実行手順等が公開されました。
その後の有識者たちによるモデルマージの実験スピードは半端なく、次々に色んな Self-evolution of LLM が誕生しておりまして、ゴールデンウィークの前半三連休(4/27-29)はかなりの盛り上がりを見せていました。
このツールに実装されたことの最大の効果というのは、進化型モデルマージの観点から言えば、「複数のモデルを組み合わせることで、それらモデルではとても達成できなさそうな高品質の応答を可能とするモデルが作れるようになった」ということ。mergekit 側の観点から言えば、「モデルをマージする中で、試行錯誤してた部分を自動化することが出来る一手法が見つかった」という事を示しています。
mergekitのインストール
試したい場合は、mergekitをインストールすることで可能になります。
既にmergekitの中に進化的モデルマージの機能は組み込まれていますので、これがインストールできればOKです。
まず、FlashAttention等実行できる環境を作るため、CUDA/cuDNNをインストールしていきます。
sudo add-apt-repository ppa:graphics-drivers/ppa sudo apt-get install g++ freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libglu1-mesa libglu1-mesa-dev wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600 sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/3bf863cc.pub sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/ /" sudo apt-get update sudo apt-get -y install cuda sudo apt-get install libcudnn8 libcudnn8-dev sudo shutdown -r now
次に、Python環境を作っていきます。
conda create -n merge python=3.11 conda activate merge pip install packaging mkdir workspace cd workspace
mergekitをインストールしていきます。
git clone https://github.com/arcee-ai/mergekit.git cd mergekit pip install -e .[evolve,vllm] ※flash-attn==2.5.6 とし、最新版インストールはやめておく pip install flash-attn==2.5.6
これでmergekit のインストールは完了するんですが、一部連動して動作するテストパッケージの lm-eval について、今改善してるかどうかは分からないのですが、lm-eval0.4.2において、一部ソースのつくりが合わない部分がありましたので、それをGithubの最新版に差し替えています。
修正前:/home/<username>/miniconda3/envs/merge/lib/python3.11/site-packages/lm_eval/api/model.py
def _encode_pair(self, context, continuation):
n_spaces = len(context) - len(context.rstrip())
if n_spaces > 0:
continuation = context[-n_spaces:] + continuation
context = context[:-n_spaces]
if self.AUTO_MODEL_CLASS == transformers.AutoModelForCausalLM:
whole_enc = self.tok_encode(context + continuation)
context_enc = self.tok_encode(context)
context_enc_len = len(context_enc)
continuation_enc = whole_enc[context_enc_len:]
elif self.AUTO_MODEL_CLASS == transformers.AutoModelForSeq2SeqLM:
context_enc = self.tok_encode(context)
continuation_enc = self.tok_encode(continuation)
return context_enc, continuation_enc
修正後:/home/<username>/miniconda3/envs/merge/lib/python3.11/site-packages/lm_eval/api/model.py
def _encode_pair(self, context, continuation):
n_spaces = len(context) - len(context.rstrip())
if n_spaces > 0:
continuation = context[-n_spaces:] + continuation
context = context[:-n_spaces]
model_class = getattr(self, "AUTO_MODEL_CLASS", None)
if model_class == transformers.AutoModelForSeq2SeqLM:
context_enc = self.tok_encode(context)
continuation_enc = self.tok_encode(continuation, add_special_tokens=False)
else:
whole_enc = self.tok_encode(context + continuation)
context_enc = self.tok_encode(context)
context_enc_len = len(context_enc)
continuation_enc = whole_enc[context_enc_len:]
return context_enc, continuation_enc
恐らくこの記事が公開されるころには修正されてる気がしますけれど、もし遭遇したらご参考まで。
関連ファイルを作成する
このmergekitというのは、マージ設定ファイルとトレーニングタスクというものを作り、その内容に基づいてモデルのマージ処理を行うように作られています。
トレーニングタスクでは、そのトレーニングに関する対応形式、降ろしてくるデータのチョイスなどを行う部分が主に記載されており、詳細の処理はプリプロセッサファイル上の関数を指定することで、スクリプトを実行させることが可能です。
以下は、多肢選択式の設問を作成する処理です。
task: spartqa_train
dataset_path: metaeval/spartqa-mchoice
output_type: multiple_choice
training_split: train
validation_split: train
test_split: train
doc_to_text: !function preprocess_spartqa.doc_to_text
doc_to_choice: [ 'A', 'B', 'C', 'D' ]
doc_to_target: "{{answer}}"
metric_list:
- metric: acc
aggregation: mean
higher_is_better: true
metadata:
version: 1.0
プリプロセッサファイルはPythonスクリプトとして拡張子に「.py」がつくようにして作成します。
def doc_to_text(doc) -> str:
answer_chunks = []
for idx, answer in enumerate(doc["candidate_answers"]):
letter = "ABCD"[idx]
answer_chunks.append(f"{letter}. {answer}")
answers = "\n".join(answer_chunks)
return f"Context:\n{doc['story']}\n\nQuestion: {doc['question']}\n{answers}\nAnswer:"
次に、トレーニングタスクとしてalpacaプロンプトフォーマットにしっかり従うようにさせるものを作ります。
task: alpaca_prompt_format
dataset_path: vicgalle/alpaca-gpt4
output_type: multiple_choice
training_split: train
validation_split: train
test_split: train
doc_to_text: "### Instruction:\n{instruction}\n### Response:\n{output}"
doc_to_choice:
- "</s>" # replace with your model's EOS token if it is different
# and now some incorrect options
- "<|im_end|>"
- "<|im_start|>"
- "### Instruction:"
- "USER:"
doc_to_target: 0
metric_list:
- metric: acc
aggregation: mean
higher_is_better: true
metadata:
version: 1.0
これらをまとめる設定ファイルを作成します。
genome:
models:
- NousResearch/Hermes-2-Pro-Mistral-7B
- PocketDoc/Dans-AdventurousWinds-Mk2-7b
- HuggingFaceH4/zephyr-7b-beta
merge_method: task_arithmetic
base_model: mistralai/Mistral-7B-v0.1
layer_granularity: 8 # sane default
allow_negative_weights: true # useful with task_arithmetic
tasks:
- name: alpaca_prompt_format
weight: 0.4
- name: spartqa_train
weight: 0.6
ここで、先頭にあるgenomeセクションが、どんなモデルをマージするのか、マージする際のメソッドに何を選択するのか、何レイヤー単位でマージするのかなどと言ったことを設定していきます。ここで、genomeセクションで「models」として指定されたモデルを「ゲノムモデル」と本記事で呼ぶことにします。また、「base_model」として指定されたモデルをベースモデルと呼ぶことにします。
上記設定はMistralAI社が提供している70億パラメータサイズのDenseモデルである Mistral-7B-v0.1 をベースに、3種類の同量パラメータサイズ、同一アーキテクチャのモデルがゲノムモデルとして選択されています。
試行錯誤して内容がはっきりしないところもありますが、こんな条件があるようです。
- 同じパラメータ同士のモデルであること
- 同じアーキテクチャ同士のモデルであること
- ベースモデルはゲノムモデルと被ってもよい
- ベースモデルは所謂「狭義のベースモデル(例えばMistral-7B-0.1とか)」でなくても良い
- ベースモデルのvocab_sizeはゲノムモデルのvocab_sizeと等しいあるいは小さくなければならない
- コンテキストサイズはベースモデルとゲノムモデルで異なってもよい
- よって、コンテキスト長が長いモデルをベースモデルに据えると、そのコンテキスト長を引き継げるっぽい
tasksセクション配下においては、何のタスクを実行させるのか、その比率はどの程度かを設定します。
この時、タスクの設定はあくまでタスクに指定した「名前:name」であり、タスクファイルを指定するのではないという事に注意してください。
これらがそろうとモデルマージができるんですが、ここでLLMはHugging Faceサイトから調達することになるのですが、Mistral-7B-0.1に関してはユーザ側の同意が必要になってきますので、Hugging Faceサイトでユーザ同意を行った上で、以下コマンドによりアカウントログインを行ってください。これができないとリポジトリから拒否されてしまいます。
huggingface-cli login
モデルマージ処理の実行
以下コマンドを実行することでモデルマージ処理が開始されます。
mergekit-evolve ./evol_merge_config.yml \
--storage-path /home/bdadmin/workspace/evol_merge_storage \
--task-search-path /home/bdadmin/workspace/eval_tasks \
--max-fevals 2 \
--vllm \
--in-memory \
--merge-cuda \
--no-wandb
wandbというのは、Weight &Biasという会社が提供するクラウドサービスで、処理の経過状況をモニタリングすることが可能になっています。きれいにデータがまとめられたりするので非常に便利ですが、デフォルトではこれへ接続することが前提になっています。
API情報等がない場合は、アカウントを作るか、APIキーを入力するか、アップロードしないかを求められ、その点非常に面倒になってきますので、アカウントを作る場合はきちんと別途作成の上、APIキーを取得してそれをはめ込む方式にしたほうがよいでしょう。
max-fevalsというのは、実行ステップ数の上限を指しています。
1ステップというのは、1つのモデルを1回評価することを指しています。この処理は、通常の学習処理とは異なる概念で動いています。これには、進化的モデルマージの全体的な動きを把握する必要があります。
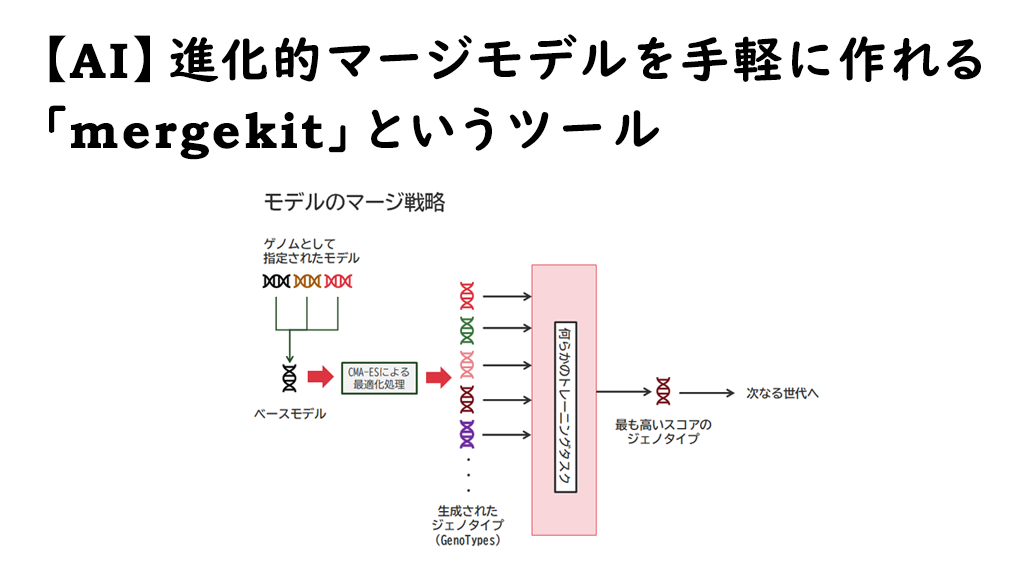
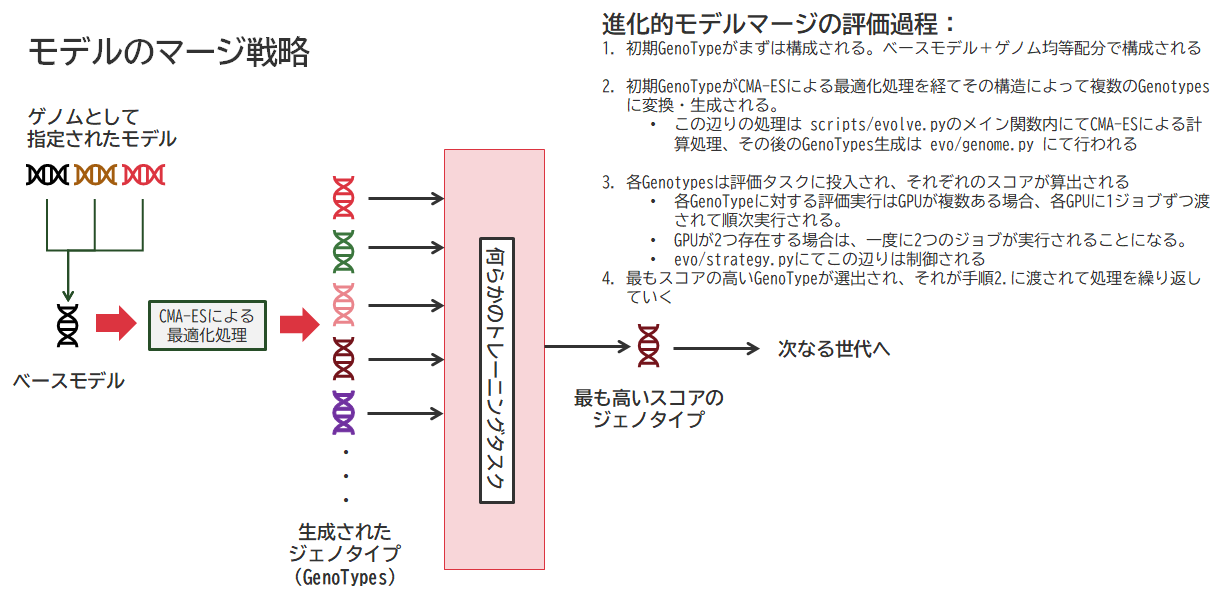
進化的モデルマージ処理の流れ(mergekitの場合)
まず、処理が開始されるとそのアーキテクチャやパラメータ構成、更新層数から、1世代に構築されるマージモデルの数を決定します。これをプログラムメッセージの内容から「GenoType(ジェノタイプ)」と呼んでるようです。初期のGenoTypeはベースモデルに対して、各ゲノムモデルが均等な比率でマージされた状態からスタートします。そこから、CMA-ESアルゴリズムによって割出されたマージ戦略に基づき、複数のGenoTypeが生成されます。
これら各GenoTypeに対してGPUが処理を進めていきます。今回のケースでは13個のGenoTypeが生成されています。
 ※偉そうに書いてるんですけど、もし中身が間違ってたらごめんなさい・・・・・
※偉そうに書いてるんですけど、もし中身が間違ってたらごめんなさい・・・・・
これらGenoTypeへの処理形態に関する判断はmergekitの evo/strategy.py で定義されており、複数GPUが搭載されている場合は分担して処理してくれています。例のように13個のGenoTypeが存在する場合は、13Stepの実行を経てようやく全部のGenoTypeに対する評価結果が出そろいます。
出そろった評価結果の中から、得点の最も高いGenoTypeが勝者となり、その世代のGenoTypeとして採用されます。
つまり、ステップ数は最初に定義されたGenoTypeの数分実行しないと意味がないのです。
なので、Max-fevalsの値を低くしても2で停止することはなく、一旦1世代目のマージ処理が完了するまでは終わりません。上記実行コマンドを投入した場合は、13Stepまで進んだところで処理が終了します。
処理が終了すると、その世代の勝者であるGenoTypeのマージ設定が出力されます。(前段の設定に沿った出力結果を載せたかったんですが、Weight値があまりいい内容ではなかったので、別の出力から引用しました)
base_model: /home/bdadmin/workspace/evol_merge_storage/input_models/Mistral-7B-v0.1_8133861
dtype: bfloat16
merge_method: task_arithmetic
parameters:
int8_mask: 1.0
normalize: 0.0
slices:
- sources:
- layer_range: [0, 8]
model: /home/bdadmin/workspace/evol_merge_storage/input_models/ELYZA-japanese-CodeLlama-7b-instruct_2748934992
parameters:
weight: 0.3667706066742279
- layer_range: [0, 8]
model: /home/bdadmin/workspace/evol_merge_storage/input_models/Llama-3-8B-Instruct-Ja_2703622211
parameters:
weight: 0.3077709683735149
- layer_range: [0, 8]
model: /home/bdadmin/workspace/evol_merge_storage/input_models/Mistral-7B-v0.1_8133861
- sources:
- layer_range: [8, 16]
model: /home/bdadmin/workspace/evol_merge_storage/input_models/ELYZA-japanese-CodeLlama-7b-instruct_2748934992
parameters:
weight: 0.6060307095024151
- layer_range: [8, 16]
model: /home/bdadmin/workspace/evol_merge_storage/input_models/Llama-3-8B-Instruct-Ja_2703622211
parameters:
weight: 0.4604024262442268
- layer_range: [8, 16]
model: /home/bdadmin/workspace/evol_merge_storage/input_models/Mistral-7B-v0.1_8133861
:
:
そして、max-fevalsの値を超過したうえで、世代的にキリの良いステップを進んだところで処理が終了し、最終的なベストスコアを記録した世代の勝者となったGenoTypeがベストコンフィグとしてコマンドで設定したストレージ領域上にYAMLファイルで配置されます。
面白いのが、最終世代までいかずともEarlyStopをかけることが可能な点です。
もうスコアの更新はなさそうだと判断したとき、Ctrl+Cの押下で処理を中断すると、ちゃんと終了処理が実行されて結果がまとめられます。
この点は極限までGPUリソースを酷使するそのコストの大きさがあるが故の実装ですね。
マージモデルの作成
マージモデルの設定が出来上がったら、mergekitの機能を使用して実際のモデルを作成します。
$ mergekit-yaml ~/workspace/evol_merge_storage/best_config.yaml --cuda ~/workspace/final_merge モデルマージ処理自体は1分もかからなかったと思う。 Warmup loader cache: 100%|????????????????????????????????????????????????????????????????????????????????????????????????????????????| 4/4 [00:00<00:00, 4742.01it/s] WARNING:root:Using submatrix of /home/bdadmin/workspace/evol_merge_storage/input_models/Hermes-2-Pro-Mistral-7B_2793206805:model.embed_tokens.weight Executing graph: 100%|????????????????????????????????????????????????????????????????????????????????????????????????????????????| 2039/2039 [00:31<00:00, 64.49it/s] $
この処理にはそんなに時間がかかりません。1分~2分程度で処理は完了していました。すると、末尾で設定したfinal_merge ディレクトリに以下のようなファイルが配置されます。
合計 14146340 drwxrwxr-x 2 bdadmin bdadmin 4096 4月 25 11:28 . drwxrwxr-x 6 bdadmin bdadmin 4096 4月 25 11:28 .. -rw-rw-r-- 1 bdadmin bdadmin 3714 4月 25 11:28 README.md -rw-rw-r-- 1 bdadmin bdadmin 696 4月 25 11:28 config.json -rw-rw-r-- 1 bdadmin bdadmin 2842 4月 25 11:28 mergekit_config.yml -rw-rw-r-- 1 bdadmin bdadmin 9919903816 4月 25 11:28 model-00001-of-00002.safetensors -rw-rw-r-- 1 bdadmin bdadmin 4563594216 4月 25 11:28 model-00002-of-00002.safetensors -rw-rw-r-- 1 bdadmin bdadmin 22798 4月 25 11:28 model.safetensors.index.json -rw-rw-r-- 1 bdadmin bdadmin 414 4月 25 11:28 special_tokens_map.json -rw-rw-r-- 1 bdadmin bdadmin 1795331 4月 25 11:28 tokenizer.json -rw-rw-r-- 1 bdadmin bdadmin 493443 4月 25 11:28 tokenizer.model -rw-rw-r-- 1 bdadmin bdadmin 967 4月 25 11:28 tokenizer_config.json
LLMとして動作するための必要なファイルセットですね。このディレクトリを丸々LLMモデルととらえて推論処理を実行させると、ちゃんとLLMとして機能することになります。今回、Mistral-7B-0.1系のLLMは、およそ14GBぐらいのサイズになってました。
様々な応用があった!・・・・けど。
これだけ自動化できる機能が登場したら、まぁそりゃぁ皆張り切りますよね・・・・(私も張り切りました)。色んな方が色んな応用を試みていました。一例として挙げておきます(中にはその仕組みを頂戴しつつモデルを進化させてみたりしています)
- Mergekit-Evolve登場!進化的アルゴリズムで手元のLLMを最強進化させよう!
https://soysoftware.sakura.ne.jp/archives/3872 - mergekit-evolve-elyzatask100
https://github.com/Hajime-Y/mergekit-evolve-elyzatask100
お二人とも評価機にELYZA-tasks-100を使用してモデルづくりを試行されてました。うみゆきさんはllama.cppを使用した内部評価の仕組みを、Hajime-YさんはGoogleのGemini-Pro 1.0を使用されてました。
これら、その後1つ目の記事を執筆なさってたうみゆきさんが気づいていらっしゃったことなのですが、llama系モデルやGemini等主要AI大手ベンダーが構築したモデルは「その結果をもって他のモデルを強化することに使ってはならない」という規約が存在することが分かり、生成されたモデルそれ自体が商用利用不可という扱いなのかもしれない・・・という意見がX.com界隈に流れてました。
You may not use the Services to develop machine learning models or related technology.
※Google 生成AI追加利用規約:https://policies.google.com/terms/generative-aiv. You will not use the Llama Materials or any output or results of the Llama Materials to improve any other large language model (excluding Meta Llama 3 or derivative works thereof).
※META LLAMA 3 COMMUNITY LICENSE AGREEMENT : https://github.com/meta-llama/llama3?tab=License-1-ov-file#readme
1. License Rights and Redistribution. -> b. Redistribution and Use 内にて記載
ただ、その中でも今のところはMistralAI社のMistral/Mixtral系モデルはその制約を受けないようです。(具体的にどこでそれが判断できるかどうかまでは追い切れていませんが・・・)
ちなみにOpenAIもアウトでした。OpenAI社のTerm of Use(https://openai.com/policies/terms-of-use/)の中で明示的に述べられていました。そもそもLLaMaの初期版が商用利用禁止という扱いになってしまったのは、そういえばGPT-3の出力結果を蒸留したもので学習したからでしたね・・たっはっは・・。ただ、こうした禁止ポリシーは過去に学習時のデータを蒸留して作成してモデル品質を向上させるという事を契機に生まれたものであり、LLMの自動評価の仕組み(5段階のスコア評価結果)を使うだけの状況がこれに抵触するというのは、少し可能性を狭める一面があるようでちょっとなぁ・・・という気は個人的にしてます。
というわけで、ELYZA-tasks-100をそのまま自動評価に使うには同系列のLLMを用いた評価機を必要とするわけなんですけど、そうしたこともあってか、一旦そのテンションも下がったように見受けられるのですが、それでもこういう効率化の事例というのは今後必要に応じて発展していきそうな気がしています。継続事前学習と言われる、追加学習として事前学習相当の学習処理を実行させる(単語を覚えさせるなど。RAGでやることをファインチューニングで行うようなもの)のはこうした処理の自動化が必要だったり思案すので、規約に抵触しないうまい使い方が見つかればいいなぁ・・・と感じる今日この頃です。
私もせっかく作ったモデルがその後の検証などに使えなくなってしまったことからだいぶ凹みました(ELYZA-tasks-100自体のスコアはそこまで高くなかったけど、日本語能力はめちゃくちゃ高まって凄く扱いやすかったのですけど・・・)が、とりあえず書ける内容だけ書いていくという感じでこの記事を再執筆した次第です。でも、やっぱしですね・・・・、各社モデルの規約についてはやっぱりちゃんと読まないとダメですね。私自身もそんなところの見落としにただただ反省です。
日本語モデルの評価って難しいのです
このモデルを完成品かつ商用利用可能な状態に持っていくにはそれなりの苦労が伴う所があり、例えばこのmergekit-evolveでは、評価機として連動可能なlm_evalのつくりを考慮する必要があるのかな?と思います。lm_evalは多種多様なベンチマークをお手軽に実行可能な検査フレームワークのようなソフトウェアですが、基本的にこれは英語しか考慮ができてないように見えます。多肢選択式タスクであればある程度の対応がとれそうですが、日本語同士を照合するようなタスクである場合は、恐らく分かち書きをしたうえで評価をするようなロジックを組む必要が出てくるかなと思われます。
そのために、形態素解析エンジンに何を使うか・・とか、どういう形式で値を引き渡す必要があるか・・とか、そうした部分の修正が必要になってくるのかな?と思います。lm-evalを実装した日本語フレームワークも存在するんですが、lm-evalはembedded的に独自のforkして実装してるケースが多く、この辺りはそうした連携の取り方についてPythonで組み合わせる技術に長けた人だと、すんなりいけるのかな?しかしながら、私にはそこまでの実力がなく・・・己の実力不足を痛感した瞬間でもありました(^-^;
実際の処理を探索してみる
さて、話は変わりましてこの進化型マージの処理、実際にディープなアルゴリズム部分を動かしてる個所はどこなのでしょうか?CMA-ESというやつですね。それはまさかのメイン関数です。
mergekit/scripts/evolve.py に処理が記述されています。
def main(
genome_config_path: str,
max_fevals: int,
vllm: bool,
strategy: str,
in_memory: bool,
storage_path: Optional[str],
num_gpus: Optional[int],
merge_cuda: bool,
trust_remote_code: bool,
allow_crimes: bool,
random_seed: int,
batch_size: Optional[int],
sigma0: float,
use_wandb: bool,
wandb_project: Optional[str],
wandb_entity: Optional[str],
task_search_path: List[str],
allow_benchmark_tasks: bool,
save_final_model: bool,
reshard: bool,
):
config = EvolMergeConfiguration.model_validate(
yaml.safe_load(open(genome_config_path, "r", encoding="utf-8"))
)
check_for_naughty_config(config, allow=allow_benchmark_tasks)
if use_wandb:
if not wandb:
raise RuntimeError("wandb is not installed")
run = wandb.init(
project=wandb_project or "mergekit-evolve",
entity=wandb_entity,
config=config.model_dump(mode="json"),
)
else:
run = None
:
:
:
try:
xbest, es = cma.fmin2(
None,
parallel_objective=parallel_evaluate,
x0=x0,
sigma0=sigma0,
options={"maxfevals": max_fevals},
callback=progress_callback,
)
xbest_cost = es.result.fbest
except KeyboardInterrupt:
ray.shutdown()
:
:
if save_final_model:
print("Saving final model...")
run_merge(best_config, os.path.join(storage_path, "final_model"), merge_options)
ここで、cma.fmin2というメソッドが動いていますが、この部分でCMA-ESに基づく計算処理が実行されています。
CMA-ESの実際の計算内容は、PyPIに収録されているcmaライブラリが用いられているため、詳細まで把握することはできませんが、コア部分がこうしてmain処理で実装され、その他の行列操作に関わる補佐的な機能が /mergekit/evo ディレクトリ配下のスクリプトに収納されている感じでした。
そして、ソースを読んだりトライアンドエラーを繰り返していくとなんとなくわかると思うのですが、Sakana.aiさんが提唱した方法の中で「Parameter Space」までの実装しか行われていませんで、Data Flow Spaceマージの仕組みまでは取り込まれていません。
Data Flow Spaceマージまで取り込まれてくると、異なるタイプのニューラルネットワークを結合させることもあるいは可能になるのだろうと予想されますが、それにはParameterマージよりももっと複雑な処理形態が必要になってくるだろうと考えられます。Sakana.aiさんが論文で記述してる内容を見る限り、パラメータ数規模が7Bから10Bに進化したモデルもあり、それらがDFSを使ってると書いてる以上、Sakana.aiさんの実装した仕組みの中にはこうしたDFSを可能とする仕組みがあるんだろうとは思いますけど、mergekitのそれだと完全ではないという事なのかなと思われます。
とは言え、実際に進化型モデルマージを実行することにより、その一方式だけ扱えるとしても十分な効果が出そうだという事が見えてきてますし、それぞれ得意とする推論パターンのつくりに応じて、同型でさえあれば機能の付与を一定量行えること、何よりこれ自体がちゃんとその界隈では有名になってる開発元で実装されていることは非常に大きいのかなぁと感じています。技術的な閾値を下げたという意味でもものすごく大きなものがあると思います。
それにしてもたった数日でこれだけのムーブメントになったことは本当にすごいと感じました。
なかなかこのスピードについて行くのは大変で、現時点でもよろよろしっぱなしなんですが、その他またついてけそうなネタがあったら駆け寄ってみたいと思います。




