素人がトピックモデルを試してみた (第2回)
2018年09月10日 月曜日

CONTENTS
前回はトピックモデルの概要と前処理を紹介し、実際のテキストデータでトピックモデルを試してみました。
IIR 英語版という非常に分野の偏ったテキストにシンプルな前処理を施して潜在的ディリクレ配分法(LDA)を適用しただけでしたが、そうして得られたトピック分布をヒートマップで図示すると、その狭い分野のテキストが(期待を超えて)それなりに細分化されていそうに見えました。
今回は当初の目的のひとつ、記事のグループ分けを実際に行って、その結果をより詳細に見ていきたいと思います。
グループ分けを考える
LDA は文書ごとにトピックの分布を計算してくれましたが、逆にいえば LDA がやってくれるのはここまでで、このトピック分布をもとに元の文書をグループ分けをするための手法は別途選ぶ必要があります。 機械学習の分野を探してみると、これまた用途に応じて特性の異なる様々なアルゴリズムがあります。
しかしここでは、あくまでユルく、もっと単純な方法を試してみることにしましょう。 LDA で文書ごとのトピックの分布を計算したので、最も高い確率を示したトピック番号にその文書を所属させるという方法です。
| 文書 | 序文 | 1.1 | 1.2 | 1.3 | 1.3.1 | 1.3.2 | 1.3.3 | 1.4 | 1.4.1 | 1.4.2 | 1.4.3 | 1.4.4 | 1.5 | 著者 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IIR03 | – | 3 | 16 | 12 | 0 | 10 | 0 | 15 | 11 | 7 | 17 | – | 11 | 4 |
| IIR04 | – | 4 | 1 | 12 | 14 | 10 | 0 | 15 | 5 | 6 | 11 | – | 8 | 4 |
| IIR05 | 14 | 4 | 1 | 12 | 14 | 10 | 0 | 15 | 14 | 1 | 4 | – | 4 | 4 |
| IIR06 | 18 | 4 | 1 | 12 | 14 | 10 | 0 | 15 | 7 | 1 | 15 | – | 15 | 4 |
| IIR07 | 9 | 4 | 9 | 12 | 14 | 10 | 0 | 15 | 6 | 9 | 6 | – | 8 | 4 |
| IIR08 | 7 | 4 | 9 | 12 | 14 | 10 | 0 | 15 | 12 | 2 | 19 | – | 8 | 4 |
| IIR09 | 7 | 3 | 1 | 12 | 14 | 10 | 0 | 15 | 5 | 11 | 15 | – | 8 | 3 |
| IIR10 | 16 | 3 | 1 | 12 | 14 | 10 | 0 | 12 | 0 | 11 | 5 | 5 | 8 | 3 |
| IIR11 | 12 | 4 | 1 | 12 | 2 | 10 | 0 | 12 | 6 | 5 | 1 | – | 17 | 4 |
| IIR12 | 0 | 3 | 9 | 12 | 14 | 7 | 0 | 15 | 18 | 1 | – | – | 8 | 4 |
前回ヒートマップでいくつか見たように、定期の観測記事 1.3.1 節 ~ 1.3.3 節は概ねそれぞれのグループに分類されています。 例えばグループ 0 は、1.3.3 節(SQL インジェクション攻撃の定期観測記事)を中心として構成されています。 ただ、このグループは他の節を 3つ含んでいます。 これらを詳しく見ていきましょう。
特定のトピックに分類された文書を詳しく読んでみる
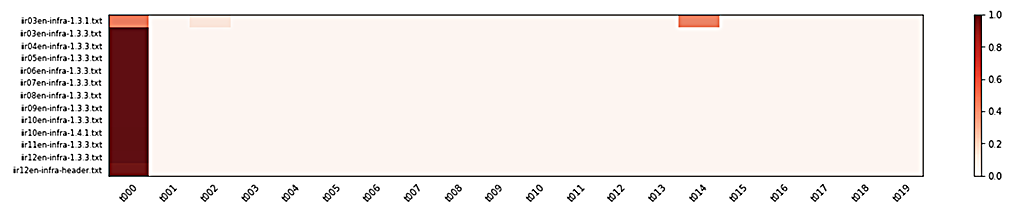
Vol.3 の 1.3.1 節は DDoS 攻撃の定期観測記事ですが、ヒートマップ上は他の号の 1.3.1 節とよく似たトピック分布を示しています。 たまたまトピック番号 0 が他のトピック番号よりも高い値になったのでしょう。 最も高い確率を示したトピック番号で分類先を決めた、今回の分類法の限界と言えるでしょう。
Vol.10 の 1.4.1 節は 2010年9月に発生した大規模 DDoS 攻撃を解説しています。 気になるのは、このフォーカスリサーチ記事の内容が 1.3.3 節 SQL インジェクション攻撃の内容と共通点が多いとは考えにくいことです。 仮に 1.3.1 節 DDoS 攻撃の定期観測と共通のグループに分類されていたのなら納得できるのですが。
Vol.12 の1章冒頭タイトルと概略文もグループ 0 に分類されています。 ヒートマップを見ても 1.3.3 節と見分けのつかない分布が得られています。 しかし、文章を読んでみると SQL インジェクションとの共通性があるようには思えません。 3〜4行程度の文章なので、その短さでは判別しにくいということでしょうか。
他のグループについても元文書にあたって読んでみましたが、ここでは省略します。
特集記事はどのように分類されたのか?
次に、ある程度の長さがあって著者も内容も毎号違っている、一般的な文書と最も近いと思われるフォーカスリサーチ(1.4.1節 ~ 1.4.4節)について、それぞれがどのように分類されたかを調べてみます。
![]()
Vol.4 の 1.4.3 節と Vol.9 の 1.4.2 節はクラウド・セキュリティを解説した記事ですが、この 2本は同じグループ 11 として分類され、納得の結果となっています。

一方で、Gumblar 攻撃についての記事、その発生から変種、模倣マルウェアの登場など、状況の推移を次々と解説した Vol.4 1.4.2 節、Vol.6 1.4.1 節、Vol.7 1.4.1 節を見てみると、今回の分類法では 3本のうち Vol.6 の記事だけが別グループに分類されました。 これらの文書はひとつのグループに分類されていてほしいものです。 ヒートマップでトピック分布を確認すると、それぞれの記事はトピック番号 6 だけに強く反応、番号 7 だけに強く反応、3, 6, 7 に反応していることがわかります。 もっと賢い分類アルゴリズムを使って、この3本を同じグループに分類できるでしょうか? トピック番号 6 と 7 それぞれに強く反応の出る 2 つの文書を一つのグループに入れるとなると、分類基準が相当に緩くなってしまい大きなグループが数個だけできるという状況も考えられます。 分類アルゴリズムだけでなく、分類の元となる LDA の計算結果がより良くなる(= 筆者たちの感覚に合う)ように、前処理部分の工夫も検討すべきかもしれません。

グループ 5 に分類された記事を見てみましょう。Vol.4 1.4.1 節、Vol.9 1.4.1 節、Vol.10 1.4.3 節、同 1.4.4 節、Vol.11 1.4.2 節の5本が該当します。 これらの記事の共通点は何でしょうか? それぞれの記事を実際に読んでみても、よくわかりません。 強いて想像すれば、他のグループに入れられなかった記事が集まった「その他」グループという可能性を思い付きます。 より細かく分割されることを期待して、トピック数や分類先グループの数を増やすべきでしょうか? ただ、細かい分割を目指すことは、先ほど述べた「Gumblar 攻撃を継続的に扱った 3本の記事を同じグループに分類したい」という希望と反対の方向に働くおそれもありそうです。 また、他のグループにも目を向けると、グループ 13 は中身が空になっていることに気づきます。トピック数やグループ数を増やしたところで空のグループが増えるだけにならないか、気になるところです。
グループ分けはできたのか?
今回は、LDA で求めたトピック分布の値をもとに「極めて単純な方法で」記事の分類を試みました。
定期的な観測記事は号ごとの共通部分が比較的多く、これらは概ね一つのグループとして分類されているようでした。
一方で、感覚的な期待とは異なるグループに入ってしまった記事も見うけられました。 それらを観察すると、今回選択した単純な分類手法が原因ではなく、それ以前のトピック分布を求める段階までの手法に改良が必要と思われるものもありました。
このことから、よりよい結果を求めて精度を上げていくとしたら分類アルゴリズムを良いものにするだけでは不十分で、トピック分布を求める段階から手を入れるべきだと考えられます。
つづく
今回、トピックモデルについて調査したのですが、その範囲では「どういう結果だったら改良のために何をすべきか?」といったマニュアルのようなものは見つかりませんでした。 トピックモデルを使っている事例では経験則、試行の繰り返しからパラメータ調整やアルゴリズム選択をしているようでした。
トピック分布を求めるまでの段階を改良するために考えられる方法には以下のようなものがあります。
- 元となる文書数を増やす
- LDA は推定値を求めるアルゴリズムなので、よりよい推定(収束)のために
- LDA 適用前の前処理を工夫する
- 目的にとって役に立ちそうもない単語の除去と、閾値の組み合わせ
- 単語の品詞
- 単語の出現率で高頻度のものと低頻度のもの、それぞれの閾値
- 目的にとって役に立ちそうもない単語の除去と、閾値の組み合わせ
- LDA 計算時に指定したトピック数やその他のパラメータ調整
また、今回は「最も高い確率を示したトピック番号」を採用するという単純な手法でグループを分けてみました。
LDA では文書ごとにトピック分布という形で複数トピックの混ざり具合を計算してくれているのに、最大値をとるトピック番号だけに着目した今回の分類手法はトピック分布を求めるメリットをまったく活かしていません。 トピック分布をベクトルと見て、ベクトル間の類似度(感覚的には「近さ」)を測る指標を使って記事間の類似度とすることができそうです。 また、トピック分布は確率分布の形をしているので、確率分布間の類似度を評価する指標を利用することも考えられます。 これらの類似度を使い、近い記事を同じグループに入れるようなクラスタリング手法を使うやりかたの方がよい結果が得られるかもしれません。
何をもって「よい結果」とするかを定めることも大きな課題の一つです。 学術研究では、LDA で作成したモデル自体の良し悪しの評価に perplexity や coherence といった指標が提案されています。 これらのものはモデルの性質を表す指標であることは確かですが、よい指標を持つモデルを適用して得られた結果が、実際に人がよいと感じるものになっているかについてはさまざまな議論があるようです。
次回は、上に挙げたトピック数の変更などを実際に適用して、分類結果がどう変化するかを観察します。