端末の文字幅問題の傾向と対策
2022年02月15日 火曜日

CONTENTS
端末の文字幅問題
CLI や TUI なアプリケーションを使っていると、端末の画面が崩れてしまうことがよくあります。
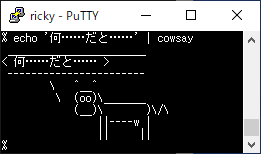
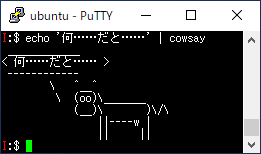
たとえば、こんな TUI が、
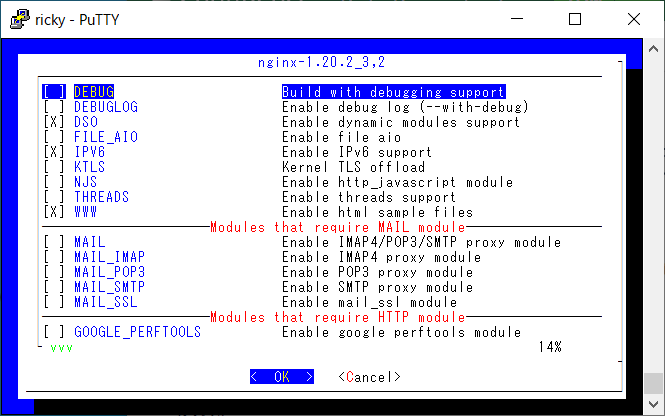
環境によってはこんな感じで崩れます。

スクロールなどをしながらしばらく使っているとさらにどんどん崩れていきます。
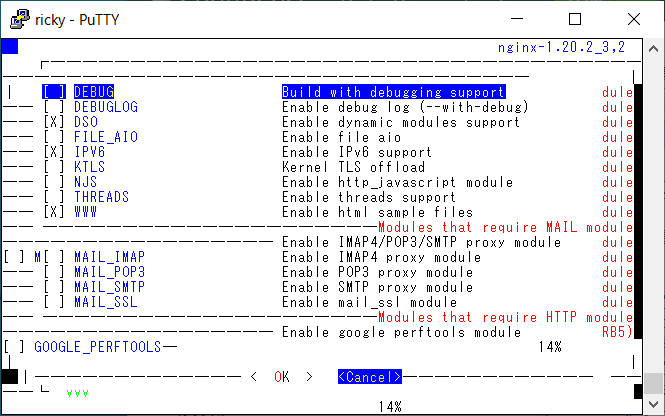
こうなってしまった場合、とりあえず Ctrl-l で画面を再描画することで、大抵はなんとか読める程度にリセットできますので、ことあるごとに Ctrl-l を連打することになります。
ですが、どうしようもないケースもままあります。
例えば、私の場合は以下のようなシチュエーションで困ります。
- w3m でテーブルなどを表示するとレンダリングが崩れる
- less でログの閲覧の際に表示されるべき文字が表示されず見落としが発生する
- Wanderlust (Emacs のメーラ) で spam などを表示すると画面の下の方の表示が崩れる
- Vim でカーソル位置が実際と表示とで食い違って編集困難になる
- Zsh や SQLite3 などで行編集する際にカーソル位置が実際と表示とで食い違って入力困難になる
- dialog4ports や nmtui の設定画面で画面が崩れてチェックボックスやフォームの入力や内容確認が困難になる
これは、画面を出力するアプリケーションが想定している文字幅と、それを表示する側の端末が想定している文字幅とが食い違っているために起こります。
例えば、ある文字を、アプリケーションは文字幅 1 のつもりで画面を構成して出力しようとして、
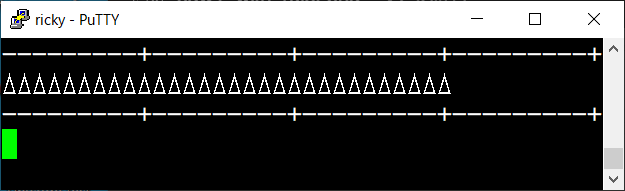
それを表示する端末側が文字幅 2 で表示しようとすると、
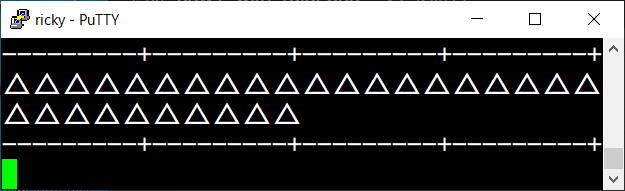
一行が想定以上に長くなり画面が崩れてしまいます。
さらに、 GNU screen や tmux などの端末マルチプレクサを使っていれば、
- TUI アプリケーション
- 端末マルチプレクサ
- 端末アプリケーション
の全てで文字幅が揃っている必要があり、そうしないと画面が崩れてしまうということになります。
東アジアの文字幅 (East Asian Width)
Unicode 以前、固定幅文字端末の文字幅は、ざっくり、
- 欧米
- 全部半角
- 東アジア (CJK)
- ASCII 文字は半角
- マルチバイト文字は全角
こんな感じで扱われていたと思います。
通常、複数の言語や文字集合が混在することは無かったため、文字幅の違いが問題になることはほとんどありませんでした。 (ISO-2022 に混在する仕組みはありましたが、あまり使われてなかったと思います)
しかしながら Unicode では、それらが混在し、既存の符号化方式の文字が同じコードポイントに割り当てられるということが起こり、そういった文字を端末で半角全角どちらで表示すべきなのかという問題が出てきました。
そこで Unicode では、文字幅をどう扱うべきかをまとめた附則文書「UAX #11: East Asian Width」 (参考: Wikipedia 「東アジアの文字幅」) が用意されています。 (ちなみに、この編集者はオライリー『日本語情報処理』『CJKV』の Ken Lunde です)
この附則では Unicode の各文字に以下のいずれかの属性が割り当てられることになっています。
- 常に半角 (N, Na, H)
- 常に全角 (W, F)
- 文脈によって文字幅が異なる (曖昧 (Ambiguous)) (A)
- 非 CJK では半角
- CJK (日本語、中国語、韓国語) では全角
具体的な割り当ては、 EastAsianWidth.txt というファイルに記述されています。
# EastAsianWidth.txt より抜粋 0041..005A;Na # Lu [26] LATIN CAPITAL LETTER A..LATIN CAPITAL LETTER Z 007F;N # Cc <control-007F> 00AE;A # So REGISTERED SIGN 3400..4DBF;W # Lo [6592] CJK UNIFIED IDEOGRAPH-3400..CJK UNIFIED IDEOGRAPH-4DBF FF01..FF03;F # Po [3] FULLWIDTH EXCLAMATION MARK..FULLWIDTH NUMBER SIGN FF64..FF65;H # Po [2] HALFWIDTH IDEOGRAPHIC COMMA..HALFWIDTH KATAKANA MIDDLE DOT
曖昧な文字には、ギリシャ文字やキリル文字、アクセントなど記号のついたラテン文字、記号や役物などが含まれます。
曖昧な文字は文脈によって文字幅が変わるため、ユーザはあらかじめ
- 非 CJK
- CJK
のどちらを採るかを決めておきます。必ずしも日本語だから CJK というわけではなく、日本語話者で非 CJK を選択する方もいます。
そして、どちらか決めたら、それを全てのアプリケーションで統一して設定します。そうすることで、文字幅の食い違いが起こらなくなります。
理屈の上では。
文字幅の設定方法
各アプリケーション毎の具体的な設定方法については、
上記サイトをはじめ、様々な方が公開されていますので、ググってみていただければと思いますが、こちらに載っていないもので私が良く使うアプリケーションの設定方法をいくつかご紹介します。
ちなみに、私が CJK 派のため、全て CJK に設定する方法になります。宗教上の理由により端末は Windows に偏っています。
PuTTYrv, iceiv+putty
- 「ウィンドウ」→「変換」→「文字セット変換」→「リモートの文字セット」
- 「UTF-8 (Non-CJK)」: East Asian Width の Non CJK の文字幅
- 「UTF-8 (CJK)」: East Asian Width の CJK の文字幅
- 「CJK 用の文字幅を使用する」という設定項目は PuTTYjp 派生では意味がないらしい?
RLogin
- Server の設定の「スクリーン」→「制御コード」→「エスケープシーケンス」の「Aタイプを半角で表示 | Aタイプを全角で表示」のチェックを外す
Tera Term
Tera Term のバージョンアップと公式サイト移転に伴い記載内容を修正しました(2023/11/21)
- Tera Term 4 までの内部処理は MBCS のため、東アジアの文字幅が適切に扱えない
- Tera Term 5 からは東アジアの文字幅に対応しています
- 参考: Additional settings / “coding” タブ ([Setup] メニュー)
- 「設定」→「その他の設定」→「coding」タブで「Ambiguous Characters width」を「2 Cell」にセット
mintty
- ロケールとフォントに依存
メニューの「Options」→「Text」で「ja_JP」「UTF-8」- (2022/10/24 修正) メニューの「Options」→「Text」で「ja_JP」「UTF-8@cjkwide」
- 最近のバージョンで設定方法が変更になりました (参考: Cygwinで変更になった一部全角幅文字の扱いを元に戻す – Qiita)
- 「MSゴシック」など適当なフォントを設定
gnome-terminal
- プロファイルの設定で「互換性」の「曖昧幅の文字」を「全角」
- 古いバージョンの場合は環境変数に VTE_CJK_WIDTH=1 をセット
jless
罫線を ASCII 文字で表示する
環境によって罫線文字の幅が問題になることがあり、その場合には罫線を ASCII で表示することで解消します。
- dialog4ports (FreeBSD ports の設定用コマンド)
- 環境変数 D4PASCIILINES=Y をセット
- portconfig (FreeBSD ports の設定用コマンド)
- (2022/11/14 修正) 環境変数 DIALOGOPTS=
--ascii-lines をセット
- (2022/11/14 修正) 環境変数 DIALOGOPTS=
- Newt (TUI ライブラリ), whiptail (Newt 同梱コマンド)
- nmtui, ntsysv, raspi-config など
- 環境変数 WCWIDTH_CJK_LEGACY=yes をセット
何もしなくてもよしなにやってくれる
- Neo-cowsay
- mattn/go-runewidth を使用
- 環境変数の locale 設定を参照して文字幅を判断
- mattn/go-runewidth を使用
- Reline
- 後述
アプリケーション内での文字幅の取り扱い方
アプリケーション内での文字幅の取り扱い方 (文字幅の取得方法) の実装方式には主に 2 通りあります。
- wcwidth(3)
- locale で定義された文字幅を参照して、引数で与えられた文字の文字幅を返す
- 自前で文字幅テーブルを持つ
- East Asian Width のデータを元に生成したテーブルを自前で持っている
- このテーブルを参照する関数・メソッドを独自実装して、それを利用して文字幅を得る
- wcwidth() を、 locale を参照せず自前テーブルを参照するものに置き換えるケースもある
- wcwidth() を独自実装して、そちらを使う
- LD_PRELOAD で wcwidth() をすりかえたりするなんてものも
そして、前述の文字幅の設定 (非 CJK / CJK) に応じて文字幅テーブルを引いて、得られた文字幅にもとづいて画面を描画します。
本来であれば、これで正しく画面をレンダリングできるはずなのですが、しかしながら、実際には、下記のような問題があったりして、なかなかそううまくはいきません。
- locale が CJK の文字幅に対応してない
- OS 標準の locale はたいてい非 CJK なので、 CJK 対応の locale 定義は別途用意する必要ある
- Linux の CJK ロケールを公開してるひとがいるのでそれを使うと良い
- FreeBSD のは見当たらないので自前で用意する必要がありそう
- 私も以前自作していたが、最近形式が変わって、追従するのが面倒なのでまだやってない……
- OS 標準の locale はたいてい非 CJK なので、 CJK 対応の locale 定義は別途用意する必要ある
- Unicode バージョンによって文字幅の定義が異なる
- エラッタの修正
- 定義が変更になる
- Unicode 9.0.0 で絵文字が半角から全角に変更
- emoji-data.txt で「Emoji_Presentation」のもの (地域指示記号を除く) は全角扱いすると明記された
- Unicode 9.0.0 で絵文字が半角から全角に変更
- 新たに文字が追加
- Unicode 12.1.0 で令和の合字 (全角) が追加
- 文字幅テーブル定義が正しくない
- 文字幅テーブル生成スクリプトがバグっているなど
- 文字幅が変化してしまうような余計な文字変換が行われてしまう
- GNU screen
- DEC 罫線 (半角) を勝手に Unicode 罫線素片 (曖昧) に変換してしまう
- ので CJK では画面が崩れてしまう
- この記事の冒頭に挙げた例の画像を参照
- 設定で変換抑制などもできない
- アプリ側で罫線を ASCII で描画するように設定するしかなさそう
- DEC 罫線 (半角) を勝手に Unicode 罫線素片 (曖昧) に変換してしまう
- GNU screen
- UAX #11 に準拠しているが非 CJK にしか対応していない
- utf8proc (どうも CJK には塩対応っぽい……) など
- FreeBSD の locale の UTF-8 の文字幅は utf8proc ベース
- utf8proc (どうも CJK には塩対応っぽい……) など
- 絵文字の扱い
- EastAsianWidth.txt では全ての絵文字が全角というわけではない
- EastAsianWidth.txt で半角扱いのものも含め、その他の絵文字も全角として扱っている実装がある
- 例
- hamano/locale-eaw は U+2600-U+27FF および U+1F000-U+1FFFF が全角
- Tera Term unicode_buf ブランチは U+1F000 以上は全角、それ以外の絵文字は曖昧
- そもそも東アジアの文字幅に対応してない
- 文字幅が全部半角
- 欧米の方の作ったアプリケーションに多い
- 文字幅がバイト長
- EUC-JP (SS2, SS3 を除く) 、 Shift_JIS などでは問題が起こりにくいが、
- UTF-8 では日本語の多くが 3 バイト以上となるので問題となる
- East Asian Width 以前に作られたアプリケーション
- lv
- 文字集合毎に表示幅が決まっているとのこと
- CJK なら問題が起きにくい
- lv
- 文字幅が全部半角
cowsay
cowsay はディストリビューションや環境によって文字幅の扱いが異なります。
オリジナルの Perl の cowsay は文字幅を length() で求めているため、メッセージ文字列が UTF-8 だとふきだしが崩れます。
一文字あたりの表示幅が 2 なのに対してバイト数は 3 なので、ふきだしの幅がその分だけ余計に大きくなります。
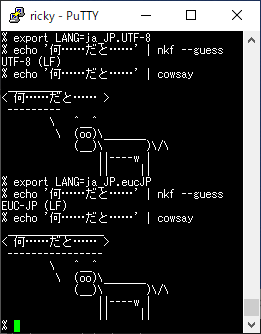
Debian, Ubuntu の cowsay にはマルチ対応パッチが当たっており、文字幅を wcwidth() で取得するため、マルチバイト文字でもふきだしの幅が正しくなります。ただし、ロケールを正しく設定しないと曖昧幅の文字 (「…」 (三点リーダ)) でふきだしが崩れます。
FreeBSD ports/package の games/cowsay (Red Hat 系の yum/dnf の cowsay も同様) も文字幅はオリジナルと同じく length() で取得していますが、 locale が UTF-8 だと utf8 によって length() が文字単位になるため、こんどは逆にふきだしの幅が小さくなります。
メッセージ文字列が EUC-JP で文字幅もバイト幅も 2 だと、ふきだしの幅が正しくなります。
# この表示例では途中から GNU screen の encoding コマンドで文字コードの設定を変えています。
Perl で東アジアの文字幅を扱うには Text::VisualWidth::PP というモジュールがあるので、これを使うと良さそうです。
# Text::VisualWidth::PP の現在のバージョン 0.05 は曖昧幅の文字の扱いに問題があるようです。また、内部で使用している Unicode::EastAsianWidth (作者はオードリー・タンです) は現在のバージョン 12.0 は Unicode 12.0.0 ベースなので令和の合字などには未対応です。
また、 Unicode::EastAsianWidth::Detect というモジュールを組み合わせることで、環境変数のロケールから CJK / 非 CJK の設定が取得できます。
14a15,18
> use Unicode::EastAsianWidth::Detect qw(is_cjk_lang);
> use Text::VisualWidth::PP qw(vwidth vtrim);
> $Text::VisualWidth::PP::EastAsian = is_cjk_lang;
>
113c117
< $l = length $i;
---
> $l = vwidth($i);
122c126,127
< my $format = "%s %-${max}s %s\n";
---
> my $pad = " " x $max;
> my $format = "%s %s %s\n";
140c145
< sprintf($format, $border[0], $message[0], $border[1]),
---
> sprintf($format, $border[0], vtrim($message[0].$pad, $max), $border[1]),
142c147
< map { sprintf($format, $border[4], $_, $border[5]) }
---
> map { sprintf($format, $border[4], vtrim($_.$pad, $max), $border[5]) }
145c150
< sprintf($format, $border[2], $message[$#message], $border[3])),
---
> sprintf($format, $border[2], vtrim($message[$#message].$pad, $max), $border[3])),
こんな風に修正してみると、
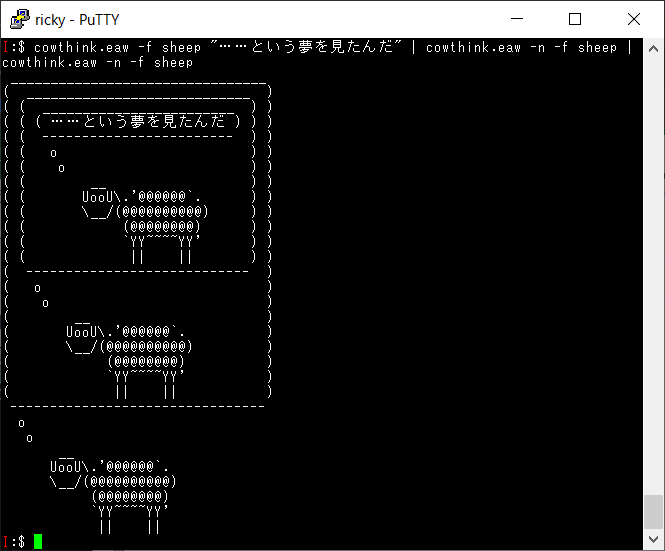
良さそうです。
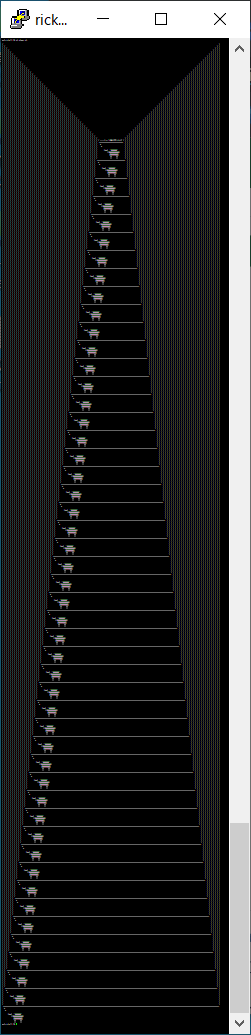
Reline
Ruby の REPL の irb は、行編集に Readline や libedit といったライブラリを利用していましたが、 Ruby 2.7 からは外部のライブラリへの依存を無くすためか Reline という pure Ruby なライブラリが同梱され、 irb もこれを使うようになりました。
この Reline は East Asian Width のテーブルを自前で持つことで文字幅をよしなに扱ってくれるのですが、曖昧文字幅については起動時に端末から自動的に取得してくれるようになっていて、ユーザが明示的に CJK / 非 CJK の設定をする必要がありません。
で、その取得の方式が面白そうだったので御紹介します。
曖昧文字幅を取得する処理は reline.rb の Reline::Core にあり、こんな感じ:
private def may_req_ambiguous_char_width
@ambiguous_width = 2 if Reline::IOGate == Reline::GeneralIO or STDOUT.is_a?(File)
return if defined? @ambiguous_width
Reline::IOGate.move_cursor_column(0)
begin
output.write "\u{25bd}"
rescue Encoding::UndefinedConversionError
# LANG=C
@ambiguous_width = 1
else
@ambiguous_width = Reline::IOGate.cursor_pos.x
end
Reline::IOGate.move_cursor_column(0)
Reline::IOGate.erase_after_cursor
end
つまり、
- カーソルを行頭に移動
- 「▽」 (U+25BD) を表示 (「▽」の文字幅は曖昧)
- 表示後のカーソル位置を端末から取得
- 再度カーソルを行頭に移動
- 当該行に書き出した文字列を消す
のような感じで、起動時に一瞬だけ試しに曖昧幅の文字を端末に書き出してみて、実際に動いた幅を取得しているというわけです。
試しに、
% script typescript.irb irb Script started, output file is typescript.irb irb(main):001:0> Script done, output file is typescript.irb % cat -v typescript.irb | head -3 | tail -1 ^[[1G▽^[[6n^[[1G^[[K^[[6n^[[1Girb(main):001:0> ^[[K^[[18G^[[1G^[[1G^M %
こんな感じで、 irb のプロンプトを出力する直前までに出力された内容を見てみると、
\e[1G- カーソルを行頭に移動
▽- 「▽」を表示
\e[6n- 端末からカーソル位置を取得
\e[1G- カーソルを行頭に移動
\e[K- 現在のカーソル位置 (行頭) から行末までクリア
となっており、確かに「▽」を出力している様子がうかがえます。
実際、環境に依っては irb 起動時に一瞬「▽」が見えることがありますが、それは気のせいではありません。
ちなみに、この文字幅判定方法は元々 Vim にあったものだそうで、このあたりの話は Reline 作者のプレゼンに書かれています。
このプレゼン資料も結構面白いです。
ケーススタディ (?)
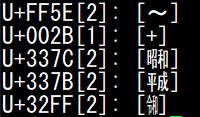
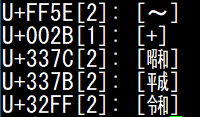
PuTTY (Unicode バージョンが古い)
PuTTY は 0.74 まで文字幅テーブルが Unicode 9.0.0 ベースだったため、例えば 12.1.0 で入った令和の合字が半角で表示されていました。
そこで、 13.0.0 対応パッチを送って対応してもらい、現在では全角表示できるようになっています。
| before | after |
 |
 |
ただ、 PuTTY は開発体制が closed らしく、修正要望やパッチを送っても受理されたかどうかのステータスがわかりくく (実は 2 回送って 1 回目はスルーされてました……) 、修正版がリリースされるまで結構やきもきしました。謝辞とかも何にもなし……。
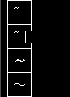
w3m (文字幅テーブルがバグっている)
w3m では、 EastAsianWidth.txt の文字幅テーブルを AWK で変換して持つようになっているのですが、これがバグっていたため、一部の文字幅が誤って表示されていました。
で、このことを 2ch (現 5ch) の w3m スレでつぶやいていたのですが、それからほどなくして本家の方で修正が入っていました。
# レスしたのが影響したかどうかは不明です……。
| before | after |
 |
 |
ただ、これでもまだ「Á」「©」などの一部の曖昧幅の文字が CJK で半角で表示されてしまうようです (理由が良く分かっていません) 。
余談ですが、 5ch のレスは著作権が 5ch のものになってしまうそうで、コードやパッチをレスすると本家へのマージでライセンスの問題が発生してしまうため、注意が必要です。パッチやコードは gist など他サイトに上げて、レスにはそのリンクを貼るか、そもそもはじめから本家に Issue や PR を投げるのが良さそうです。
dialog4ports (罫線文字の問題)
FreeBSD の ports (公式パッケージシステム) で設定変更するのに使われる dialog4ports は、デフォルトでは DEC 罫線で描画するため、 CJK を設定した GNU screen 内だと画面が崩れてしまいます。
これを避けるために環境変数で罫線を ASCII で描画できるようになっています。
ただ、一部の画面パーツだけ ASCII 対応が漏れていました。
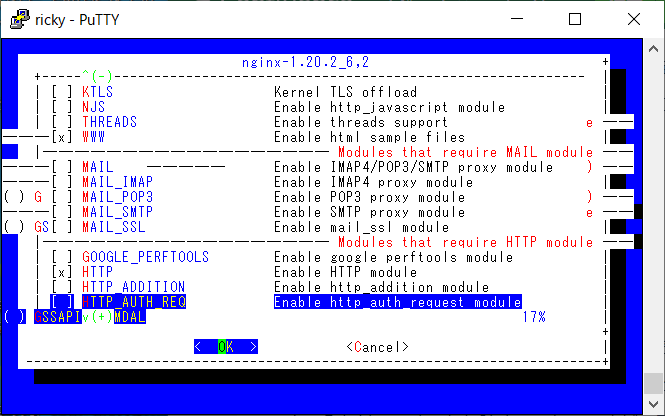
というわけで、修正パッチを本家に送ったところ、作者の方から「I will merge it soon.」との返信を得たため、反映されるのを待っていました。
が、いつまでたっても修正が反映されず。それどころか、いつの間にかリポジトリごと消滅してしまいました。詰んだ……。
というわけで、すっかり諦めていたのですが、最近になって久々に状況を確認してみたところ、どうやら dialog4ports はライセンスの問題でディスコンになるそうで、「portconfig」という代替コマンドが開発中のようです。
こちらは ASCII 対応もバッチリのようです。 (先述の設定が必要)
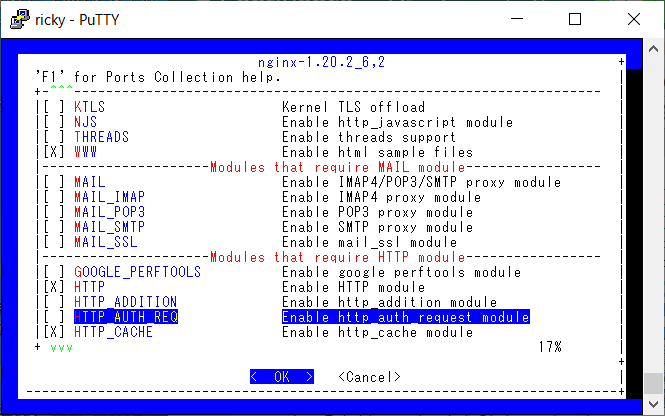
まだ (2022-02 現在) 置き換えられてはいないようですが、先取りして portconfig を使ってみたい場合は、 ports-mgmt/portconfig をインストールして /etc/make.conf に DIALOG4PORTS=${LOCALBASE}/bin/portconfig と設定すればいけます。
というわけで、一件落着。 (?)
Unicode の文字の合成
最近個人的に難物だと感じているのが Unicode の文字の合成です。
Unicode では複数の部品を組み合わせて文字を作ることができます。
例を挙げると、
- ラテン文字の記号
- 「A」+「̊」→「Å」 (オングストロームの上リング)
- 「a」+「̈」→「ä」 (ドイツ語のウムラウト)
- 「c」+「̧」→「ç」 (フランス語のセディーユ)
- 「o」+「̄」→「ō」 (日本語のローマ字の長音のマクロン)
- 「c」+「̂」→「ĉ」 (エスペラントのサーカムフレックス)
- 「a」+「̌」→「ǎ」 (中国語の拼音の声調記号)
- 濁点半濁点
- 「か」+「゙」→「が」
- 「カ」+「゙」→「ガ」
- ハングル
- 「ᄒ」+「ᅡ」+「ᆫ」→「한」
- 異体字セレクタ
- 「禰」+ U+E0100 →「禰󠄀」
- 国旗
- 「🇯」+「🇵」→「🇯🇵」 (← 環境に依りますが、日本の国旗が表示されます)
- 地域指示記号で ISO-3166-1 の 2 文字の国コードに対応する国旗になる
- 音符
 (
(さらに、絵文字ではこんなこともできます。
- ゼロ幅接合子 (ZWJ (U+200D)) による連結
- 「👩」+ZWJ+「💻」→「👩💻」
- 「👨」+ZWJ+「👩」+ZWJ+「👧」+ZWJ+「👦」→「👨👩👧👦」
これらを端末で正しく扱うには、どこまでを一文字と見做すか (書記素クラスタ (Grapheme Cluster)) を把握したうえで、各書記素の文字幅を求める必要があります。
ですが、巷のアプリケーションでそこまでできているものはほとんど無いように思います。
私の知る限りで、このあたりをサポートしていそうなのは、
- mlterm
- RLogin
- Reline
くらいしかありません。他にもあれば教えてください。
私の普段使っている環境だと、そもそも PuTTY が対応していないので絶望的です。
| RLogin | 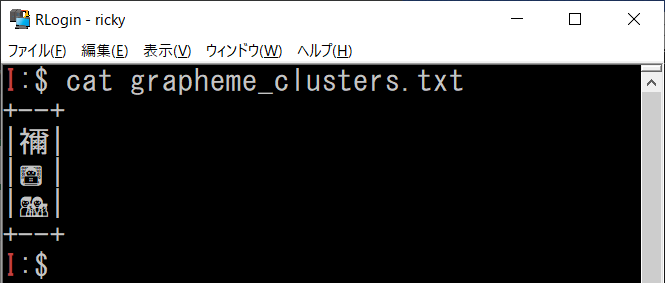 |
| PuTTY | 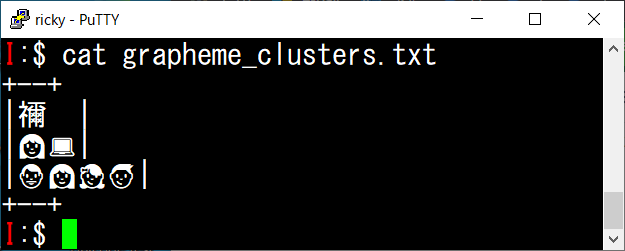 |
あと、端末マルチプレクサは GNU screen も tmux も対応できていません。
また、さらに悪いことには、表示するソフトウェアが結合したグリフに対応してなければ、フォールバックして分離した状態で表示することになっているようです。
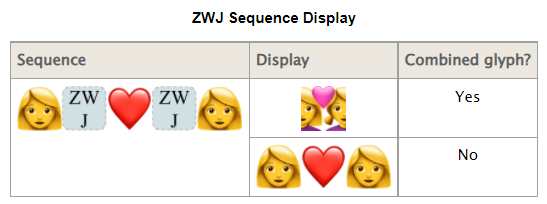
だとすると、画面出力するアプリケーション側が表示する端末側の文字幅を知るような仕組みが無いことには、そもそも文字幅を合わせることはできないということになります。
というわけで、これは完全に詰んでますね……。
まとめ
Ctrl-l はともだち。




