Network Automation powered by CI/CD
2023年12月21日 木曜日
CONTENTS
Overview
As networks grow in complexity, the challenge to maintain and scale them intensifies. Network engineers are embracing automation for improved efficiency. By integrating these advancements, network tasks become more efficient, accurate, and scalable. We’ll show how these advancements can make network operations more efficient.
The following sections will cover key tools and techniques for automating network engineering tasks.
Tools
The transition to automated network management is significantly easier by a suite of powerful tools that borrow from best practices of software development. These tools are user-friendly and seamlessly integrate into existing network engineering workflows.
Docker
Docker is a platform that enables you to create, deploy, and run applications using containers. Containers allow you to package up an application with all the parts it needs, such as libraries and other dependencies, and ship it all out as one package. Pre-packaged software guarantees a consistent application experience and increases portability. Containers are also very lightweight, having only the essentials to run the application. Unlike virtual machines, which run a full operating system and software not relevant to the application we want.
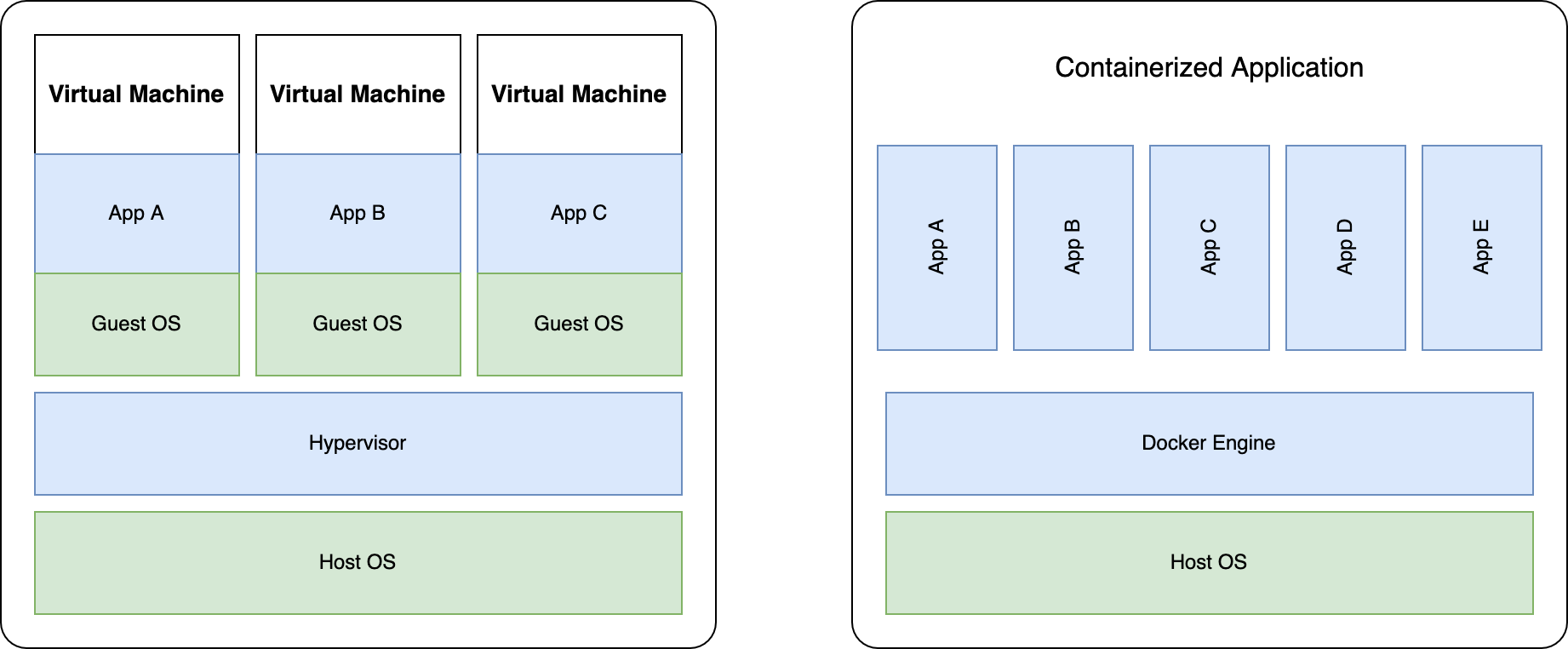
Comparing Virtual Machines and Containers
Using Docker commands for running single containers is great, but scalability quickly becomes an issue. With Docker Compose, you can manage multiple containers as a single service. Docker compose is a plugin for Docker that simplifies this process with YAML. This is especially helpful in deploying multiple network services or applications that depend on one another. You can have a web server, a database, and a DNS service running in separate containers, but working together as a scalable system. Now, instead of running a set of commands, you can spin all your services in a single command.
Ansible
Ansible is an open-source automation tool that simplifies complex configuration tasks and repetitive jobs. What sets Ansible apart from other tools is its simplicity and ease of use. It uses playbooks (also in YAML format) to describe automation jobs, and an inventory file to define the systems to automate. Ansible has support for a wide variety of machines as it connects over SSH and is agentless. This means that it does not require agents to be installed on target machines and makes it easy to add new target machines.
Git
At its core, Git is about keeping a history of changes and helping collaboration. We can commit each set of changes with messages, creating a clear audit trail of who did what and when. Network engineers can keep track of every change made to network configurations, scripts, or documentation. This ensures accountability, makes it easier to catch problems early on and allows you to revert errors caught.
The plain text nature of the YAML format used for Docker Compose and Ansible means that they are perfect to keep track of in Git. This makes it easy to keep track of incremental changes to your network and allows you to ‘version-control’ your network. With Git, multiple engineers can work on different aspects or parts of the network or infrastructure. They can then propose their changes for other members to review and merge the changes or resolve conflicts when they arise.
With our core tools in hand, we will now go over how we combine these to create a workflow that benefits network automation.
Continuous Integration and Continuous Deployment (CI/CD)
CI/CD is crucial in modern software development and can greatly benefit network automation. By using CI/CD, developers and network engineers can integrate changes more often and reliably. CI/CD does this by enforcing automation of build, test, and deployment processes facilitated by these practices.

Example CICD pipeline that builds, tests and deploys a web app
Continuous Integration (CI)
CI is a practice where engineers integrate their changes into a shared repository. Each proposed integration must pass a series of automated tests before being integrated. With the complexity of networks, it might not always be a good idea to automate accepting changes, even if they pass all the tests. The best practice is to have someone else review the changes before applying them. The goal of this approach is to avoid integration issues when deploying network configurations.
Continuous Deployment (CD)
CD ensures further automation by pushing changes to the production environment after the build and test stages. This means that the changes made are not just tested, but also deployed continuously. With CI/CD, infrastructure changes can roll out continuously with minimal downtime.
Creating CI/CD Pipeline
CI/CD pipelines allow for a lot of freedom in how you want to build, test, or deploy. For more information you can read this IIJ Engineering blog that goes into more detail on how to use GitHub actions to build and deploy a Go Web app. We illustrate their pipeline above to get an idea of how a typical pipeline looks like.
Each step of the pipeline runs within a docker container, and you can even host or build docker containers within docker containers. If you are interested in learning more, here is another IIJ blog describing how to do this with Kaniko.
As we mentioned, containers are extremely portable, and self-contained. This means that if you have 20 different jobs to run in your pipeline, they could run on 20 different machines. If you use the default CI/CD pipelines on GitHub and GitLab, your jobs could run on 20 different networks. For most applications, this is not a problem, as the point of containers is to have the self-contained applications. But the goal of our pipeline is not to test the application, but to use the application to test our network. Running our pipeline will not pass if it isn’t ever in the same network that we are testing.
To ensure that we are testing within our network, we need to host our own runners (the application that “runs” our tests). If you use GitLab, they provide a docker container for their runner, making it extremely easy to set up and experiment with pipelines. Having multiple self-hosted runners also provides load balancing and redundancy. This creates a robust CI/CD pipeline without a single point of failure.
Creating a pipeline to take backups
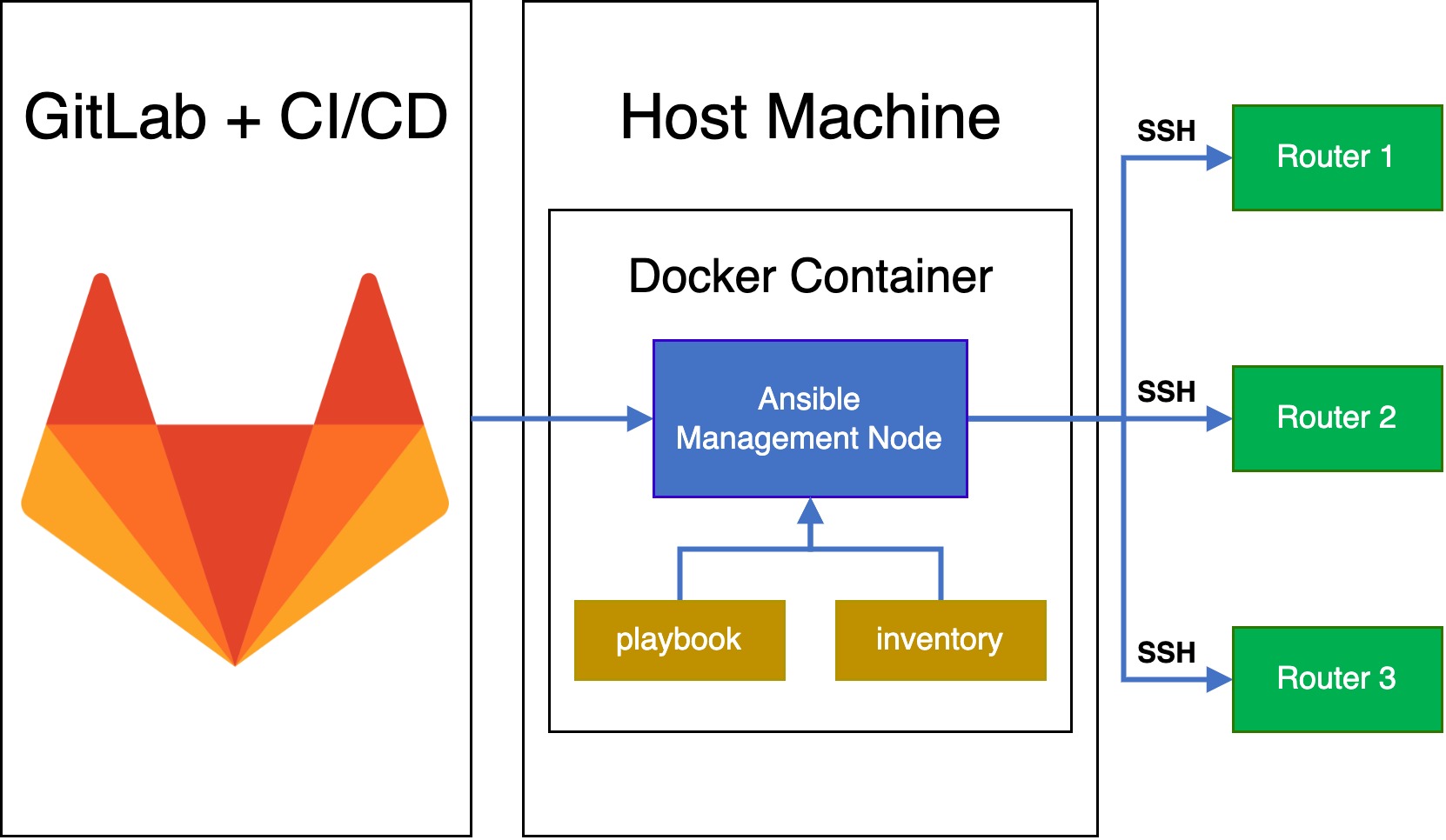
There are endless pipelines that you can write to use within your environment. But one thing that is universal is the need for backups. To show how all our tools work together, we have an example of a simple pipeline to back up some routers.
Inventory File:
[routers] r01.demo.the-net.work ansible_host=r01.demo.the-net.work r02.demo.the-net.work ansible_host=r02.demo.the-net.work r03.demo.the-net.work ansible_host=r03.demo.the-net.work [routers:vars] ansible_user=cvisser ansible_connection=ansible.netcommon.network_cli ansible_network_os=vyos.vyos.vyos
Ansible playbook:
--
- hosts: routers
gather_facts: no
tasks:
- name: Login to each router and take the backup
vyos.vyos.vyos_config:
backup: yes
backup_options:
filename: "{{ inventory_hostname }}.cfg"
CI/CD pipeline:
stages:
- Backup
vyos_take_backup:
image: registry.gitlab.com/vmastar/demo-router-backup/ansible:latest
stage: Backup
script:
- echo "$SSH_PRIVATE_KEY" > /root/.ssh/id_rsa
- cd /root/demo-router-backup
- git pull
- ansible-playbook -i inventory backup.yml
- git add backup && git commit -m "Changes in router config" && git push
- exit
only:
- web
- schedules
If you are new to CI/CD pipelines or Ansible, it is easiest to read the code blocks in reverse, as the CI/CD pipeline is doing the tasks we define in the other blocks. Starting from the top of the CI/CD pipeline:
-
The example pipeline has only one stage, Backup, which will run in the ‘ansible’ container that I have built in the past.
-
Using GitLab’s artifacts, we provide our container a ssh key that it can use to access the machines in our network.
-
Ensure our local git repository is up to date.
-
Run the Ansible playbook “backup.yml”, using our “inventory” file.
-
Ansible will login to each router within the routers group and take a backup of their current configurations.
-
-
Commit the router changes into git and push the changes back to our git repository and exit
-
Finally, this job will only run as scheduled or if we trigger this pipeline via a REST API.
With that, we can now take scheduled backups of all our routers without human intervention. Unlike trying to distribute a traditional cron job, we only need to write our schedule once. As long as there are runners available for our pipeline to use, our routers will receive regular backups.
Our final workflow ends up looking as follows:
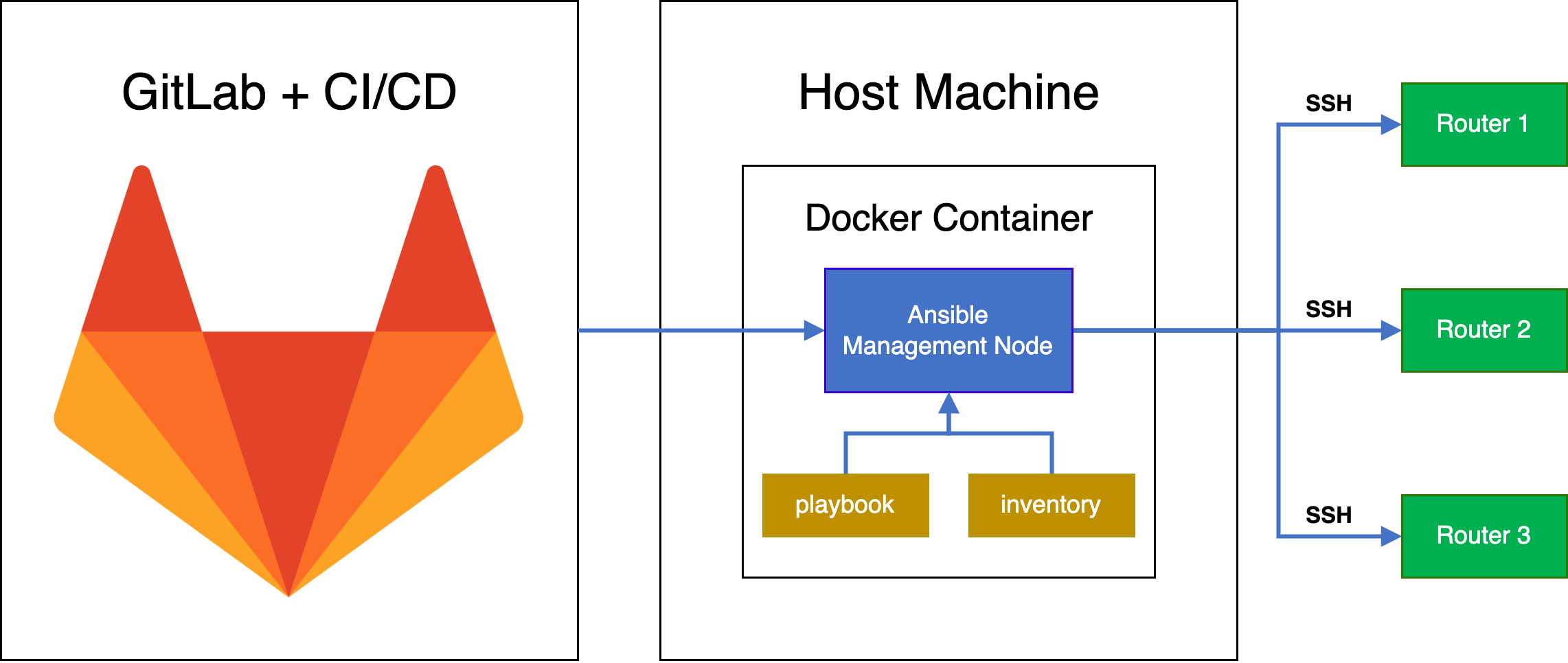
Summary
This article is a condensed version of the Network Automation tutorial that we hosted at APNIC 56 in Kyoto this year. The resources of this tutorial are available here, which contain a lot of slides and documentation for the lab exercises. For a shorter self-contained tutorial that you can do yourself, you can follow the instructions here. This tutorial has an accompanying talk as part of IIJ Lab’s TechTrend Talk series, that summarizes the workflow we described in this article.
Embracing automation is essential for managing the complexities of modern network environments. Tools like Docker and Ansible streamline the deployment and management of network configurations. While CI/CD pipelines facilitate consistent and error-free operations. These practices help network engineers prioritize innovation and improve productivity and network reliability.
There are countless ways of introducing more automation into your workflow. This can quickly become overwhelming, especially if you are new to any of these tools. The best approach is to start small, e.g. take backups, and build your skills from there.