リリース作業がコーヒートークの時間になった話
2022年11月08日 火曜日

CONTENTS
はじめまして
はじめまして、うちやまです。バックエンドのアプリケーション開発を主にしています。
みなさんはアプリケーションのリリース作業ってどう思われてますか?神経を使う?面倒?やることが多い?これ意味あると感じる?はたまたこの作業が一番怖いと感じたりしてますか?私たちのチームでは週一ペースでアプリケーションをリリースしているのですが、なぜかこのリリース時間がコーヒートークの時間になりました。よく仕事に関係ない雑談をしています。
まじめにやってよと言われたらその通りですが、システムが私たちの代わりに真剣にリリースしているので大丈夫です。要は自動化ですね。私たちはまじめにリリースするシステムを見守るだけで作業が終わります。
今回は顧客影響なくかつサービス停止時間がない、自動化されたリリースについて紹介したいと思います。
自動化したいけど
私たちのサービスはホスト上で複数のアプリケーションのDockerコンテナをDocker Compose上で動かしています。そのため、リリース作業は特定のバージョンのDockerイメージをプルして、Dockerコンテナたちを再起動させればいいだけです。これだけだと簡単に聞こえます。実際簡単です。しかし、顧客影響なしかつサービス停止せずにリリースしようとすると途端にいろいろ気になってきます。
- 1ホストずつアップデートしないと500エラーなどになって影響が出るよね
- Dockerイメージや Dockerボリュームがディスクを圧迫して、 Dockerイメージのプルに失敗することもあるよね
- Dockerコンテナが起動するまで時間がかかったりすると、起動前にユーザがアクセスして処理がうまく行われないこともあるよね
- Docker Composeでrestart alwaysなどを設定しても、そもそもDockerコンテナが起動に失敗してたら再起動を繰り返してダメだよね
- 冗長構成組んでいても、何かの設定ミスで通信できなかったら意味ないよね
- 冗長構成組んでいるけど、どの順番でデプロイしていいかわからないときがあるよね
- 冗長構成組んでいても、アプリケーションを落としたホストにルーティングされたら意味ないよね
- そもリリース物に不具合が残っていて本番環境で初めて露呈することもあるね(これはリリース関係ない話ですが)
- などなど…
そう、考えるだけで嫌になってきます。
これらを何とか解決し、リリース作業をコーヒートークの時間にしたという話です。
自動化の中身ってどうなってるの
自動化の中身は愚直かつ丁寧にいろいろしているだけです。
私たちのサービスは東西冗長構成で、リリース対象のホストは東西のデータセンターにそれぞれ複数ホストがあります。それぞれのホストで順番に下の操作をしています。
|
内容 |
効果 |
|
|---|---|---|
| 1 | ヘルスチェックを失敗させる | ルーティングから対象ホストを除外 |
| 2 | 特定のバージョンのDockerイメージ をプルする | デプロイ準備 |
| 3 | 起動しているDockerコンテナを落とす | デプロイ準備 |
| 4 | プロキシだけ起動して、DBなどの外部コンポーネントとの疎通性を確認する | 他コンポーネントとの疎通確認 |
| 5 | 各アプリケーションのDockerコンテナを立ち上げる | リリース物デプロイ完了? |
| 6 | APIテストを行う | 各アプリケーション間、コンポーネント間の連携テスト |
| 7 | ヘルスチェックを確認する | 最終確認 |
DBのマイグレーション処理などもありますが、それらを省いて主要なところだけ書き出しています。どこかの処理で失敗すると、起動しているDockerコンテナをすべて落として処理が止まります。(リリース失敗となり、私たちで確認します。)
途中の処理で失敗しリリースが止まっても、冗長構成を組んでいるため顧客影響なしでかつサービス停止も起きません。APIテストではほとんどすべてのAPIをたたいて動作を確認し、各アプリケーションやコンポーネント間の連携を確認しています。そのため、リリース終了後はすべての機能が問題なく使えている状態が保証されます。この作業をJenkinsで行えるようにしているため、リリース作業はJenkins上でボタンをポチポチするだけで終わります。
技術的な細かい話
ここからは技術的な話です。
リリース作業ではアプリケーションの再起動が必要になります。顧客影響なくかつサービスが停止しないようにするために
- リリース対象のホストへユーザがアクセスできない状況を作る
- アプリケーションをリリースする(ここでアプリケーションを再起動する)
- APIテストで最終確認を行う
- リリースしたホストへユーザがアクセスできるようにする
という流れで作業していきます。この手順をもう少し詳しくしたものが自動化の中身になってます。
さまざま細かいことはやっていますが、ヘルスチェックとAPIテストに絞って説明します。この2つが自動化実現のための大きな機能になっています。ヘルスチェックでルーティングを制御してホストへユーザがアクセスできない状況を作ります。APIテストでアプリケーションやコンポーネント間の連携、動作確認をします。ヘルスチェックとAPIテストを説明しながら、自動化内容の流れを追っていきます。
インフラ構成
その前に、インフラの構成について知らないとわけがわからないですね。
私たちのサービスではマイクロサービス化されていて、マイクロサービス化されたアプリケーションをDocker Compose上で立ち上げています。ホスト間はEnvoy Proxyを通じて通信されるようになっています。図にするとこんな形です。
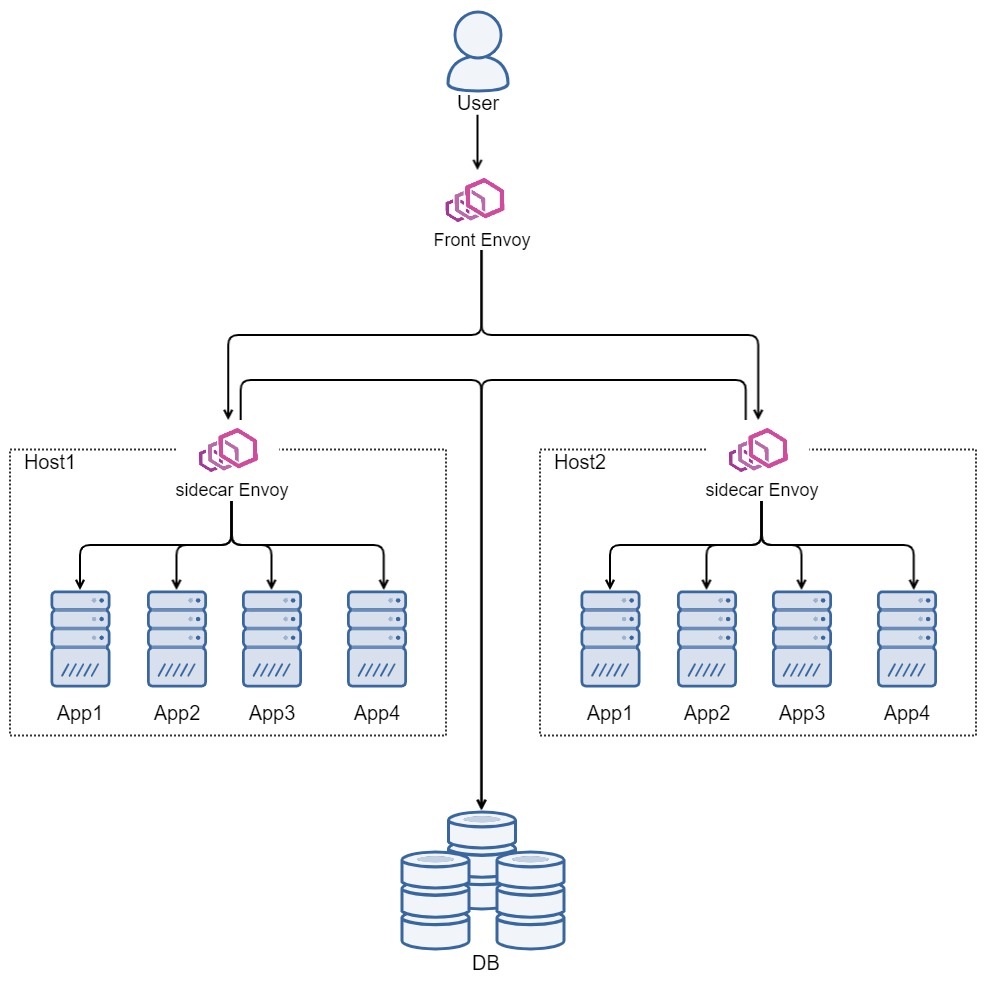
ユーザアクセスを最初に受けるEnvoy Proxy(Front Envoy)があり、そこからアプリケーションのあるホスト(Host1、Host2)へルーティングしています。Host1、Host2にはアプリケーション(App1~App4)とEnvoy Proxy(sidecar Envoy)があり、すべてDocker Compose上で動いています。Envoy Proxyがsidecarのように働いていて、このsidecar Envoyを経由してアプリケーションへ通信が流れます。また、アプリケーションからDBなどの他コンポーネントへ通信する場合もsidecar Envoyを経由して通信します。
重要なのは、アプリケーションは直接どこかのコンポーネントに通信しているのでなく、Envoy Proxyを経由している点です。
リリース作業ではHost1、2のアプリケーション(App1~App4)をリリースします。Host1についてリリースすることを例に、技術的な話をしていきます。
ヘルスチェックによるルーティング制御
ヘルスチェックでユーザがリリース中のホストへアクセスできないようにして、アプリケーションをリリースできる状況にしています。Envoy Proxyはヘルスチェックに失敗した通信先にはルーティングしない機能と、ヘルスチェックでエラーレスポンスを返すようにするAPIがあります。これらの機能を使ってこの状況を作ります。
自動化内容の1番「ヘルスチェックを失敗させる」では、sidecar Envoyにヘルスチェックでエラーレスポンスを返すようにするAPIをたたき、リリース対象ホストへユーザからの通信が流れないようにしています。要はこんなイメージです。
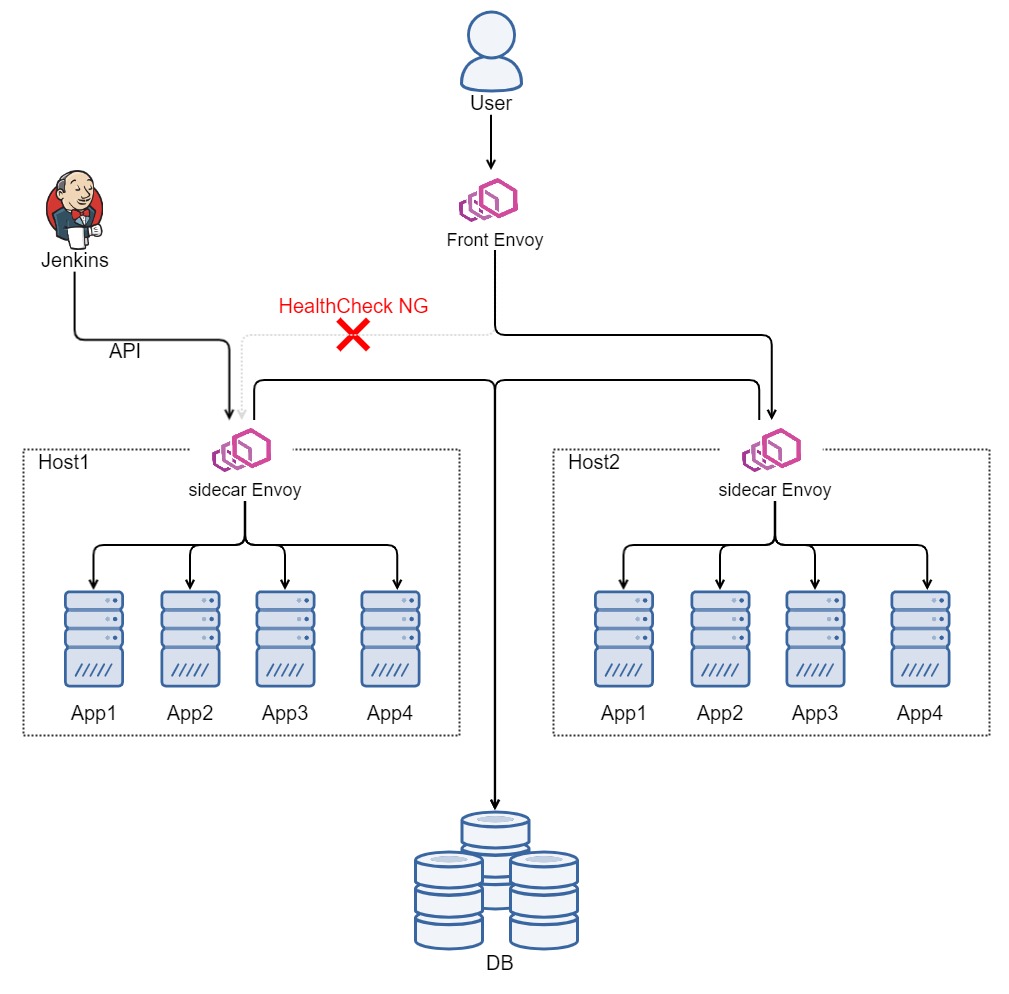
これによってHost1へルーティングされなくなり、Host2しか使用されなくなります。
次に、自動化内容の2番「特定のバージョンのDockerイメージ をプルする」、3番「起動しているDockerコンテナを落とす」を行い、Host1のアプリケーションをバージョンアップします。
自動化内容の4番「プロキシだけ起動して、DBなどの外部コンポーネントとの疎通性を確認する」ですが、このプロキシはsidecar Envoyのことを言っています。sidecar Envoyを先に起動してDBなどへの疎通確認し、アプリケーション立ち上げたあとすぐに、サービスが利用できるような状態にしています。このときの図はこのようになります。
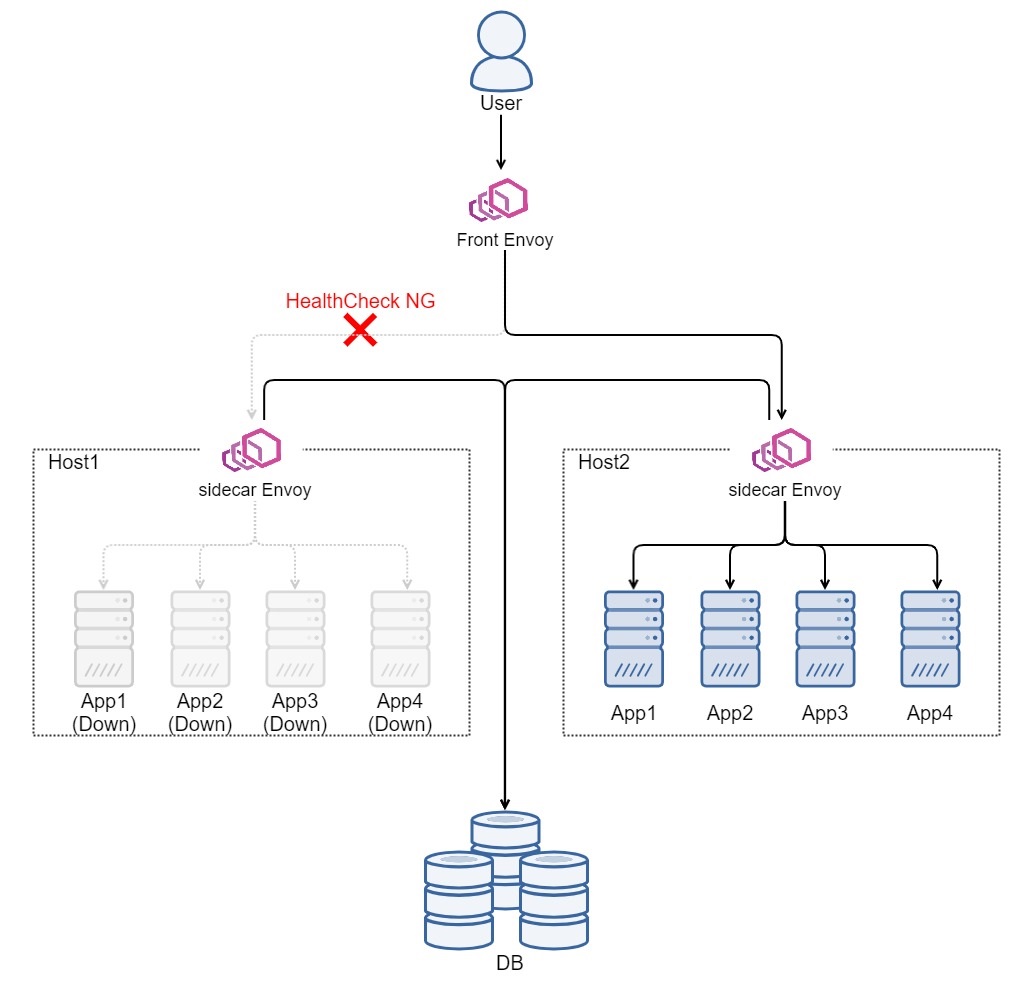
この図をよく見ると、Front Envoyからside Envoyへのヘルスチェックが通ってしまうように見えます。なぜなら、sidecar Envoyは立ち上がっていて、Front Envoyからのヘルスチェックに応答できるためです。もしそうなら顧客影響が出てダメですね…
実際はsidecar Envoyをうまく設定してsidecar Envoyだけを立ち上げてもFront Envoyのヘルスチェックの応答にエラーを返すようにしています。具体的にいうと、Front Envoyからsidecar Envoyへのヘルスチェックはアプリケーションまで貫通して対応しています。そのため、Host1のsidecar Envoyだけ立ち上げてもHost1へはルーティングされません。
APIテスト
APIテストではアプリケーションへAPIをたたき、レスポンス内容やエラーコードを確認しています。これをすることで、アプリケーション、他コンポーネント間の通信確認、API単位での最終的な動作確認を行っています。ほとんどすべてのAPIをたたくことでサービスが持つ通信経路のほとんどすべてを確認し、リリース後に不具合などがでないようにしています。APIテスト用の契約を用意していて、ユーザのデータを触らないようにしています。
自動化内容の5番「各アプリケーションのDockerコンテナを立ち上げる」をした後、6番「APIテストを行う」でAPIテストをしています。ここで不具合がない、使えなくなる機能がないことを最終確認し、胸を張ってリリースを完了!っとなります。
さて、すこし話は逸れますが、APIテストツールについて話します。
私たちのサービスはgRPCを利用しています。スクリプト上でgRPCを実際にたたき、レスポンス内容やエラーコードをテストしています。実はこのツールは私たちで作り、運用しています。ツールの利用は簡単で、yamlファイルを書くだけです。例えば、こんなprotoがあるとします。
syntax = "proto3";
package hello.v1;
option go_package = "***";
import "google/protobuf/timestamp.proto";
service HelloService {
rpc SayHello(SayHelloRequest) returns(SayHelloResponse);
}
message SayHelloRequest {
string name = 1;
}
message SayHelloResponse {
string msg = 1;
google.protobuf.Timestamp date = 2;
}
このprotoを実装しているサーバに対してテストする場合、こんなyamlファイルを書きます。
- testName: HelloTest
proto: ./service.proto
serviceName: HelloService
cases:
- name: SayHello
methodName: SayHello
detail:
requests:
- name: hoge
responses:
- msg: "Hello hoge!"
サーバに「name: hoge」というリクエストのSayHelloメソッドをなげ、レスポンスのmsgフィールドが「Hello hoge!」かどうかをテストします。
詳しく説明すると、protoファイル、サービス名、メソッド名、リクエスト内容を指定すればunary、streamを判断してgRPCを投げてくれます。レスポンスもパースされテストされます。yamlファイルをよくみるとレスポンスにdateフィールドがありませんが、書いてないフィールドについてはテストされません。つまり、dateにどんな値が入ってようがmsgフィールドが「Hello hoge!」ならテストが通るようになっています。stream APIでもテストでき、エラーコードやエラーメッセージもテストすることができます。私たちはほとんどすべてのgRPCのテストケースを書いていて、リリース前にもAPIテストをして不具合を少なくしています。
さいごに
私たちのサービスはリリース作業が簡単な方かもしれませんが、それでも考慮すべきことはたくさんあって、それを一つ一つケアしながら自動化を作り上げてます。インフラの構成についても、デプロイのしやすさや自動化のしやすさも考えながら構築、整備しています。だからこそ自動化しやすかったという面もあります。
ここでは書かなかった考慮事項もあると思います。例えばstream APIなどが途中で途切れることがないのか?リリース中にDB側で障害が起きたら大丈夫なのか?などなど。API処理が終わってからアプリケーションが落ちる、DBを冗長化していて障害が起きてもDB側で切り倒れるようになっているため、アプリケーション側で影響がないようにしているなど、ここには書いていませんがいろいろ対処されていて自動化が成り立っています。
個人的な所感ですが、自動化と聞くと華やか?ですが、その実情はかなり大変で泥臭い作業の連続です。成功しても主に私たちが喜ぶだけで、失敗したらいろんな方面から怒られます。
それでも、自動化しておいしいコーヒー飲んでみませんか?