後編:Elasticsearchの機械学習分析による類似ドメイン検知
2022年09月12日 月曜日

CONTENTS
今回は前編の続きです。 前編では、Elasticsearchの紹介や教師データの作成を行いました。
この後編では、作成した教師データを使って、実際にElasticsearchの機械学習機能を使った分析を行っていきます。
Elasticsearchの準備
パッケージのインストール
まずは Elasticsearchと WebUIの Kibanaをインストールします。以下のサイトから最新版のパッケージをダウンロードしてください。
今回使用しているOSは Debianですが、パッケージはあえて DEB版を使わず Linux x86_64版を利用しています。こちらの方が構成がわかりやすいのでおすすめです。
インストールは、任意のディレクトリでファイルを展開するだけです。今回はバージョン 8.3.2を使用しています。
Elasticsearch
$ tar -xvzf ~/download/elasticsearch-8.3.2-linux-x86_64.tar.gz
Kibana
$ tar -xvzf ~/download/kibana-8.3.2-linux-x86_64.tar.gz
設定ファイルの修正
Elasticsearch と kibana の設定ファイルはそれぞれ以下です。
Elasticsearch
elasticsearch-8.3.2/config/elasticsearch.yml
Kibana
kibana-8.3.2/config/kibana.yml
エラーが出る場合は、メッセージに従って設定ファイルを修正してください。
今回はそれぞれ以下の行を追加しています。
elasticsearch.yml
network.host: 0.0.0.0 discovery.seed_hosts: ["10.0.0.1"] cluster.initial_master_nodes: ["10.0.0.1"] xpack.security.enabled: false
kibana.yml
elasticsearch.hosts: ["http://10.0.0.1:9200"] server.host: "0.0.0.0" i18n.locale: "ja-JP"
プログラムの起動
Elasticsearch と Kibana の起動はプログラムを実行するだけです。順番としては、先にElasticserchを起動してください。
Elasticsearch
bin/elasticsearch
Kibana
bin/kibana
どちらもエラーで終了しなければOKです。
接続確認
起動できたらブラウザでKibanaに接続してみます。Kibanaのデフォルトポートは 5601/tcp です。
以下のような画面がでれば、成功です!
機械学習機能の有効化
左上の3本線を押すとメニューがでてくるので、「Analytics」の「機械学習」を選択してください。機械学習機能を使うために、「トライアルの開始」から30日のトライアルライセンスを有効化しましょう。
これでElasticsearchの準備はOKです。
機械学習分析の実施
教師データの取り込み
前回作成した教師データを Elasticsearchのドキュメントとして取り込みます。ファイルはCSV形式ですので、そのままKibana上でドラック&ドロップで取り込むことができます。
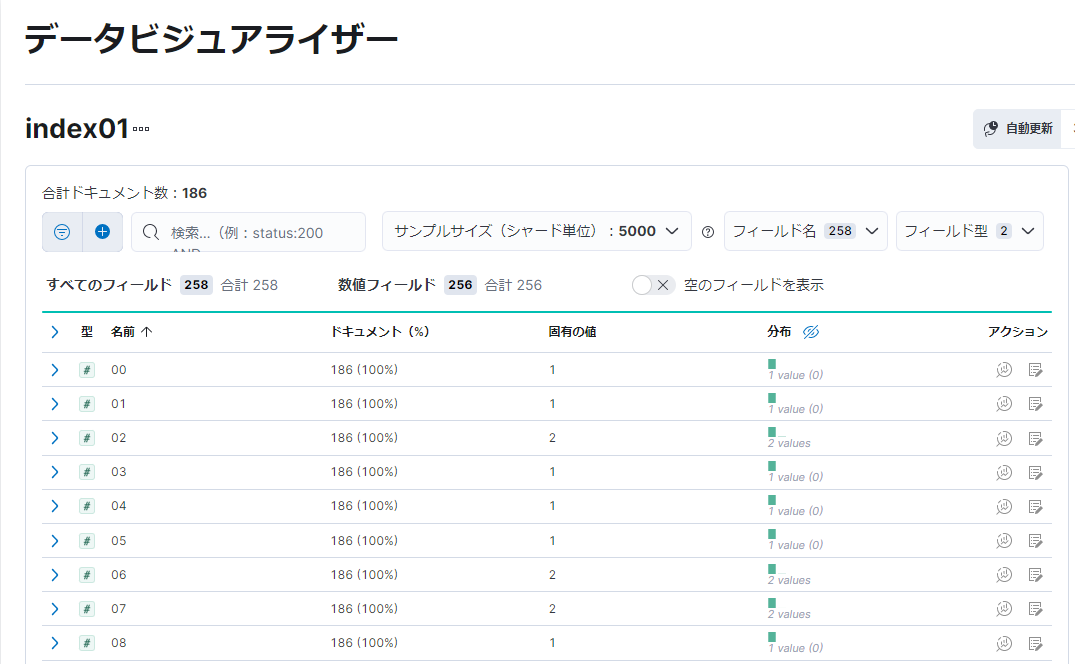
3本線メニューから「機械学習」→「データビジュアライザー」の下の「ファイル」メニューを選択してください。あとはこの中にドラッグすればOKです。エラーで取り込めなかった場合は、データに問題がありますのでエラーの内容を確認してください。
左下のインポートを押すと、インデックス名を聞いてくるので適当に入力し、再度インポートするとデータが Elasticsearchに取り込まれます。画面下の「データビジュアライザーで開く」で取り込まれたデータを確認してみましょう。
機械学習ジョブの作成と分析
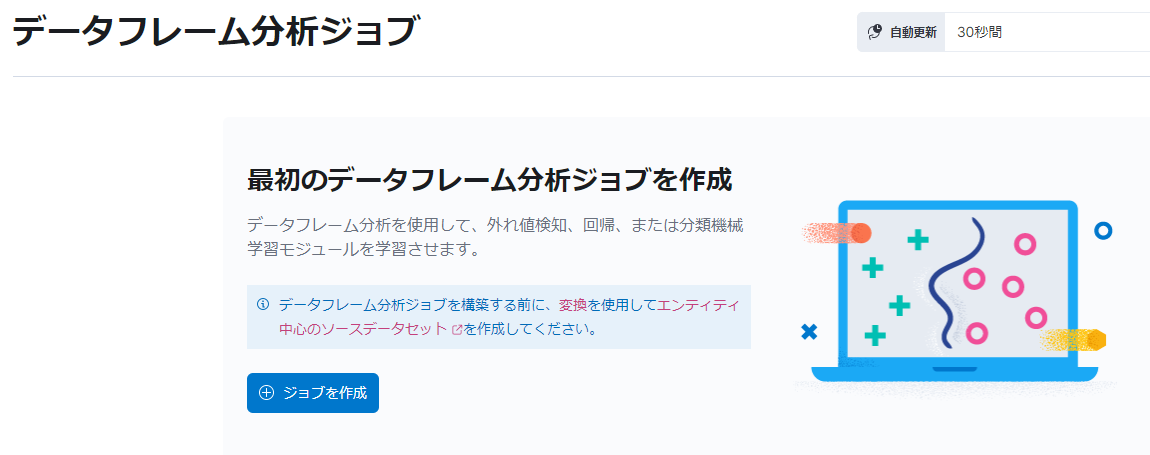
Elasticsearchにデータが取り込まれたら、いよいよ機械学習分析を行います。まず機械学習ジョブというものを作成します。
3本線メニューから「機械学習」→「データフレーム分析」の下の「ジョブ」から「ジョブの作成」をクリックしてください。
インデックスの選択画面になるので、先程作成したインデックスを選択します。
「ジョブを作成」というページでいよいよジョブを作成します。まず「外れ値検出」「回帰」「分類」の「分類」を選択してください。
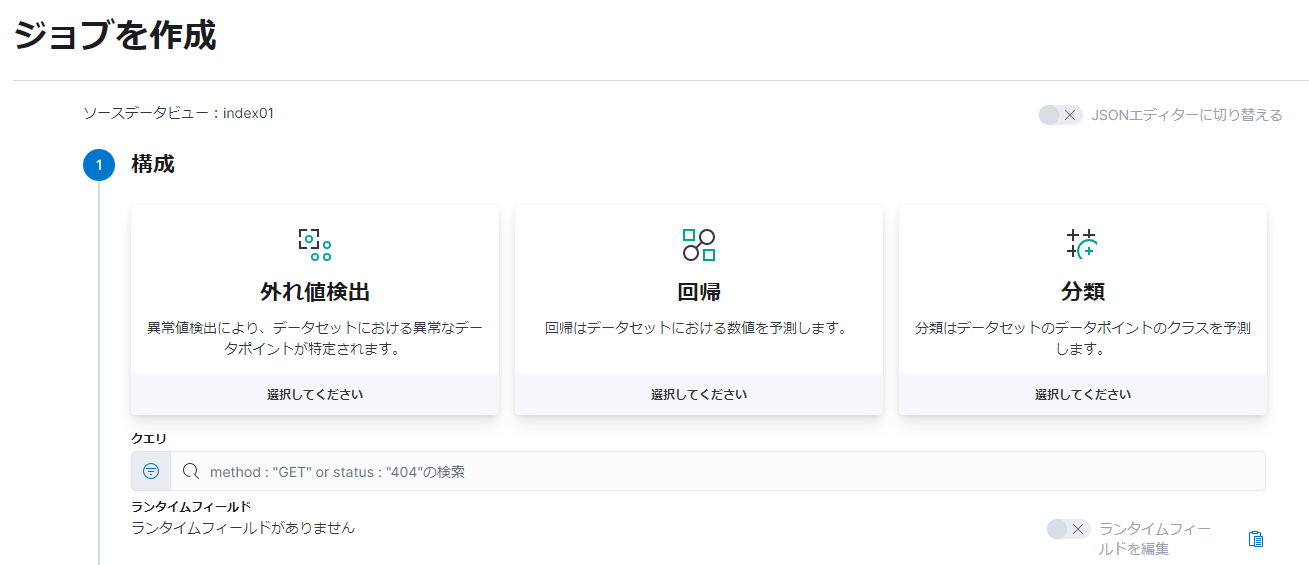
次の「従属変数」には flag といれます。また、その下の「含まれるフィールド」の横のチェックを入れて一旦全部選択した後に、検索フィールドに domain と入れて domain のチェックを外します。これにより分析対象から domainを外しています。
その後「続行」を2回押して、ジョブの詳細のジョブIDを適当に入力します。「続行」を続けて押すと、「作成」というボタンが出てきますので押してください。あっという間にフェーズが進み、分析が完了します。これで機械学習の学習と分析、そして実はモデルの作成も完了したことになります。
このように分析自体は非常に簡単で、慣れればデータの取り込みから分析完了まで10分もかからないぐらいです。
学習・分析結果の確認
最後に「結果を表示」を押すと、以下のような分析結果が表示されます。
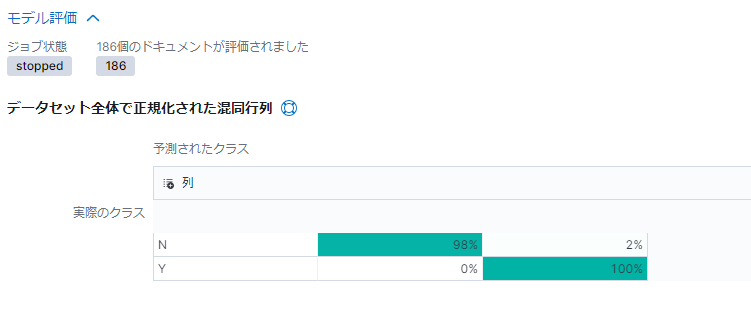
いろいろ出てますが、一番上の「データセット全体で正規化された混合行列」がわかりやすいです。
2×2マトリクスの見方は以下です。
左上:実際のクラスがN、つまり類似ドメインではないものが、類似ドメインではないと正しく判定された割合
左下:実際のクラスがY、つまり類似ドメインが、類似ドメインではないと誤って判定された割合
右上:実際のクラスがN、類似ドメインではないものが、類似ドメインであると誤って判定された割合
右下:実際のクラスがY、つまり類似ドメインが、類似ドメインであると正しく判定された割合
ですので上の例ではそれぞれ高い確率で検知できたことになります。
なお、学習に使用されるデータは全体の80%がランダムで使用されるので、同じ教師データでも分析結果は変わる場合があります。
いずれにしても元になる教師データをどう作成するかが重要となりますので、色々試してみるとよいでしょう。
作成した機械学習モデルの活用
最後に機械学習モデルの活用に関してです。学習と分析を行うと機械学習モデルが作成されますが、このモデルを Inference Processor という機能でログ取り込み時に使うことができます。これが Elasticsearch の機械学習機能を使う大きなメリットです。
つまり、リアルタイムもしくはバッチで取り込まれるログの特定のフィールドを機械学習で分類し、結果をドキュメントに付与することができるのです。さらにその結果でアラートを発砲することも可能です。
例えば、ある会社がプロキシのアクセスログを Elasticsearchに取り込み、リアルタイム保存しているケースを考えてみます。
アクセスログから接続先のドメイン部分を取り出し、今回作成した類似ドメイン検知モデルにかけることで、社内の端末が類似ドメインにアクセスしようとしている、といったことを検知できるようになります。
おわりに
このように機械学習分析といっても特に難しいことはなく、基本となる考え方やツールの使い方さえわかれば簡単に分析が可能です。
また最近、Stable DiffusionのようなAIで画像を生成するツールが話題になるなど、いよいよ機械学習を誰でも使いこなす時代が来たなと感じます。
今後は、データ分析にかぎらず、サイバーセキュリティやインフラ、ネットワーク運用、アプリケーション開発など様々な分野でAIや機械学習が使われるでしょうし、エンジニアであればそれらを使えて当たり前となるでしょう。ぜひ皆さんも色々とチャレンジしてみてください。