HTTPキャッシュを使いこなして、Webアプリを快適に(1)
2023年05月25日 木曜日

CONTENTS
cats_dogs開発者のヒラマツです。
HTTPキャッシュをうまく使う技術、HTTPキャッシュ制御を解説します。
HTTPキャッシュは、WebアプリなどのWebサービスの通信を最適化する技術です。
HTTPのCache-Controlヘッダーの使い方の話でもあります。
HTTPキャッシュ制御と言っても、Cache-Controlヘッダーの設定だけなので、簡単そうに思えます。
しかし、正しく設定しようとすると、案外、複雑で苦労します。 また、理解なしに使うと、情報漏えいの問題を起こす可能性もあり、適当に設定するのは危険です。
ぜひ、この文章を読んで、理解した上で、Catch-Controlを設定してください。
cats_dogsの仕様を書くときに、Cache-Controlヘッダーの使い方まで書こうとすると、短い文章に収まらないことに気がつきました。
そこで、(プログラマではない、HTTPなんて知りたくない)普通のWebアプリ利用者に、HTTPキャッシュ制御を解説する必要性に気がついたのが、この文章を書き始めた切っ掛けです。
というわけで、この文章は、以下の知識ぐらいを前提にしています。
- 簡単なHTMLファイルぐらいは作れる。
- HTTPヘッダーの存在を知っている。
- Webサーバ(nginxなど)で、HTTPヘッダーを設定できる。
- HTTPプロキシを使ったことがある。
- ブラウザによって動きが違うことを知っている。
絵を多めに、出来るだけかみ砕いて書いてます。 その代わり、かなり長くなりましたが、ぜひ、頑張って読んでください。
HTTPキャッシュ制御の難しさ
Cache-Controlヘッダーを設定するぐらい簡単だと思ってる人もいると思います。
私も始めは、HTTPの仕様にしたがって設定するだけぐらいに思ってました。
しかし、以下の事実には、びっくりしました。
Cache-Control: no-cacheを設定しても、キャッシュは禁止されない。
これだけで、すでにヤバそうな気配がします。そして、調べると実際ヤバかった。
こんなことになっているのは、過去の実装やブラウザ間の互換性のために、Cache-Controlヘッダーの定義自体が、とても難解になっているからです。
用語のおさらい
説明の前に、HTTPキャッシュ関連のシステムの名称を紹介したいので、 HTTP関連システムの関係を図にしてみます。
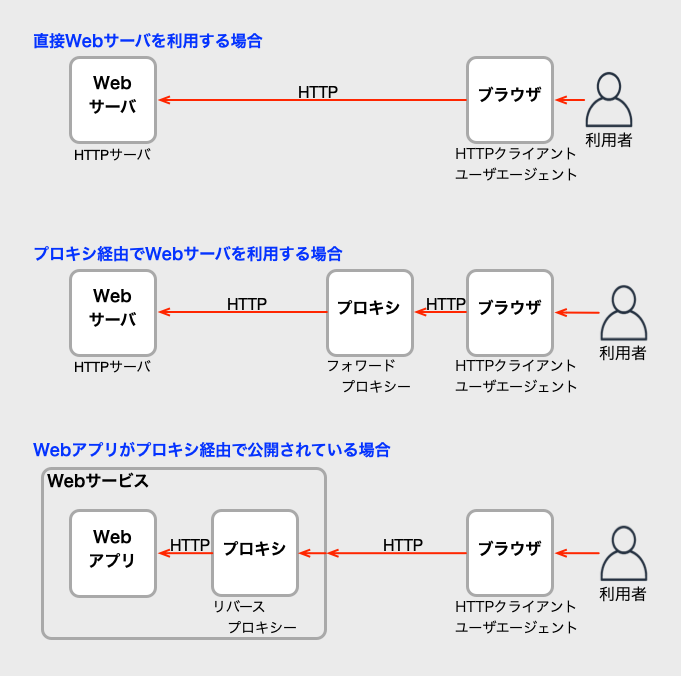
この図に登場したシステム名を簡単に説明すると、以下の通りです。
- ブラウザ(browser)/ウェブブラウザ(Web browser)
- 利用者がChrome、Firefox、Safari、EdgeなどWebサイトを閲覧するプログラムの総称です。
- Webサーバ(Web server)
- Webのコンテンツ(ページ)を提供するサーバです。
- プロキシ(proxy)/プロキシサーバ(proxy server)/HTTPプロキシ(HTTP proxy)
- HTTP通信を中継し、代理でHTTPの通信を行なうサーバです。
- 代理でHTTPへの通信を行なうので、HTTPクライアント(ユーザエージェント)としての機能も持っています。プロキシを複数組み合わせて多段にもできます。
- プロキシの種類には、大きくわけて、フォワードプロキシと、リバースプロキシがあります。
関連資料を読むときに役に立つので、派生の用語も説明します。
- HTTPサーバ(HTTP server)
- HTTPのサービスを提供するサーバです。HTTPプロトコルを使っていることを明言していることが「Webサーバ」と主な違いです。
- 今、普及しているWebサーバはHTTPサーバなので、現実的にはWebサーバと同義です、将来HTTPを使ってないWebサーバが普及するかもしれませんが…。
- HTTPクライアント(HTTP client)/ユーザエージェント(user agent)
- Webサーバにアクセスするプログラムの総称です。ブラウザのユーザエージェントの1つです。HTTPは閲覧以外にも利用できるので、ブラウザ以外のプログラムも含まれます。
- 例えば、Webページの表示機能の無い、curlやwgetなどのHTTPを使うダウンロードツールなども、HTTPクライアント(ユーザエージェント)に含まれます。
- フォワードプロキシ(forward proxy)
- HTTPクライアント(ユーザエージェント)の代理をするプロキシです。
- HTTPプロトコルの使われ方が変わるので、プロキシが代理をする対象が、HTTPサーバなのか、HTTPクライアント(ユーザエージェント)なのかを区別したいときに使います。
- リバースプロキシ(reverse proxy)
- HTTPサーバの代理をするプロキシです。
- HTTPプロトコルの使われ方が変わるので、プロキシが代理をする対象が、HTTPサーバなのか、HTTPクライアント(ユーザエージェント)なのかを区別したいときに使います。
派生の用語を説明しましたが、使い分けても難しくなるだけなので、この文章では、以降、極力「ブラウザ」、「Webサーバ」、「プロキシ」を使います。
キャッシュとは
キャッシュの説明のために、Webサーバにブラウザがアクセスする処理の流れを図にします。
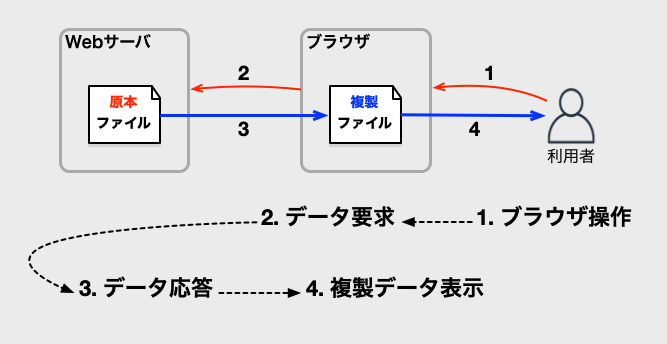
ブラウザは閲覧するファイルをダウンロードして、一時的に複製を保存し、その複製を使って表示しています。
ファイルのやり取りだけを取り出すと、以下の図になります。
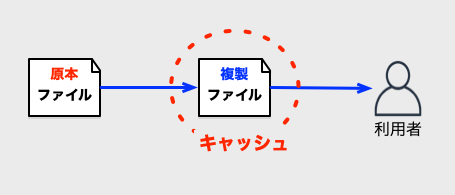
この図に出てくる、処理の為に作られる一時的な複製が、要は「キャッシュ」です。 ブラウザはディスクに保存したキャッシュだけを、都合上キャッシュと読んでいたりしますが、メモリ上にあっても、即時捨てていても、構造上は「キャッシュ」です。
キャッシュの再利用
一度作った複製である「キャッシュ」は、通信コストを考慮すると、再利用するとお得です。
再利用出来れば、以下の図のように、ブラウザはWebサーバと通信せずにデータが表示できるので、処理が軽くなります。
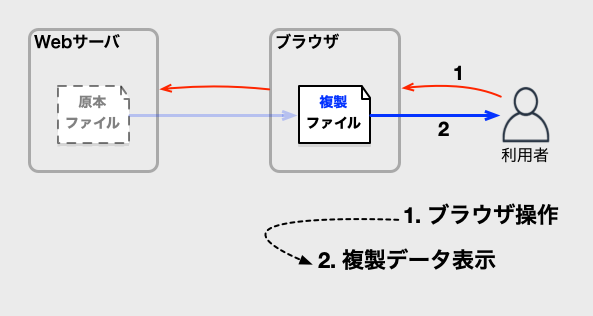
無駄に通信をするのはもったいないですし、最近の主要なブラウザは、キャッシュを再利用する機能を持っています。
キャッシュのメリット
このキャッシュ再利用のメリットを分類すると、以下の2種類に分けられます。
- 同じデータの重複ダウンロードを減らす。
- 通信時間を減らす。
それぞれについて、もう少し説明します。
メリット1: 同じデータの重複ダウンロードを減らす
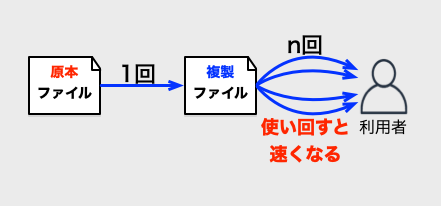
同じファイル(画像やアイコンなど)を、同時に複数回使っているときに、通信回数が減り通信コストも下がります。 同じデータを何度もダウンロードすることが回避できるので、無駄に回線を埋めるみたいなことが減らせます。 キャッシュの複製データを短時間で捨てても、メリットは発生します。
メリット2:通信時間を減らす

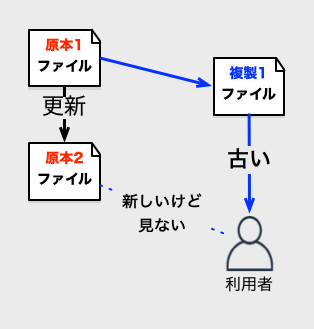
キャッシュを再利用すると、通信が遅い場合、使えば使うほど、通信時間が大きく節約できます。
しかし、長い間利用し続けると、古いデータを再利用することになります。これが、HTTPキャッシュの主な問題で、キャッシュ制御が必要となる主な理由でもあります。
更新反映が予想外に遅延する
キャッシュ制御が必要な理由である、そのキャッシュの問題をもう少し説明していきます。
当たり前のことですが、キャッシュが再利用されることで、想定より古いデータが表示されると、大抵は問題になります。
キャッシュを再利用する時間が長くなるほど、より古いデータを表示する可能性が上がります。 この問題を軽減する為、Webサーバ側から、再利用期間を指定します。これがキャッシュ期間です。(キャッシュ期間内の古くなってない状況を、HTTPキャッシュ用語で「新鮮(fresh)」と言います。例えば「新鮮なデータ」とか「新鮮な応答」と書けます。食べ物じゃないんだけども…。)
ただ、このキャッシュ期間、実は、利用して欲しくない期限より、かなり短く設定する必要があります。 それは、そのキャッシュ期間よりも古いデータが再利用されてしまうからです。 例えば、キャッシュ期間を1日に設定しても、場合によっては、2日近く古いデータが表示されたりします。
以下の図は、その状況を解りやすく図にしたものです。更新が1日間隔、キャッシュ期間も1日、タイミングが悪いことで、2日近く古いデータが再利用される状況の図です。
時間順の処理内容の説明も並記しておくので、図と共に読んでください。
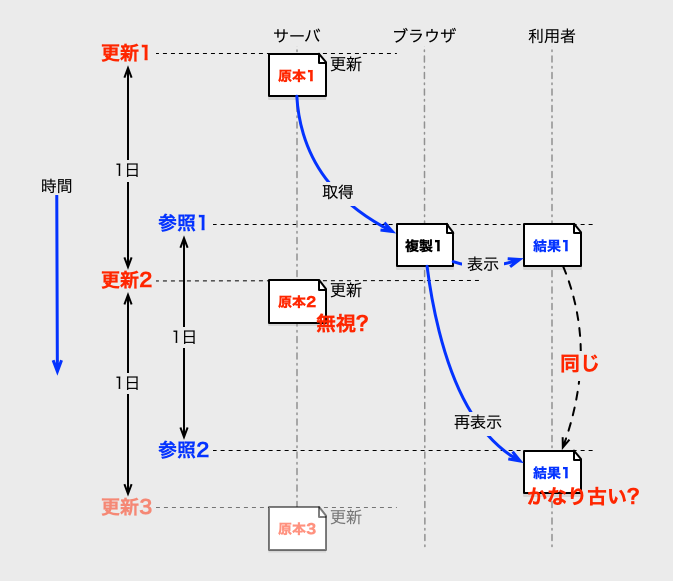
| 順序 | 図のラベル | 処理内容 |
|---|---|---|
| 1. | 更新1 | サーバのデータが「原本1」に更新される。 |
| 2. | 参照1 | サーバのデータが参照され、「複製1』のキャッシュが作られて、「原本1」と同じ「結果1」の内容が表示される。 |
| 3. | 更新2 | サーバのデータが「原本2」に更新される。 |
| 4. | 参照2 | 既に「複製1』のキャッシュがあり、キャッシュ期限を超えていないので、「複製1」を利用して「結果1」を表示する。(「原本1」と同じ古いデータを表示) |
この図のようにタイミング悪く更新や参照が起こると、キャッシュ期間よりも古いデータが簡単に表示されてしまうのです。
これは、キャッシュ期間が保証するのはキャッシュした時期の新しさで、データ自体の新しさは保証していないからです。
言葉だけでは分かりにくいので、絵にしたのが以下の図です。
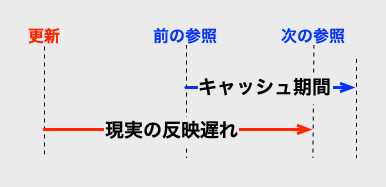
現実の反映遅れとキャッシュ期間には、計測開始のタイミングにズレがあるわけです。
そこで、現実の許容される遅れとキャッシュ期間の、現実的な関係を絵にすると、以下のようになります。

キャッシュ期間の短縮
現実的に考えると、先ほどの絵のように、許容される遅れより、キャッシュ期間はかなり短いものにせざるを得ません。 短くした場合の例として、キャッシュ期間を6時間に短く変更すると以下の図のようになります。
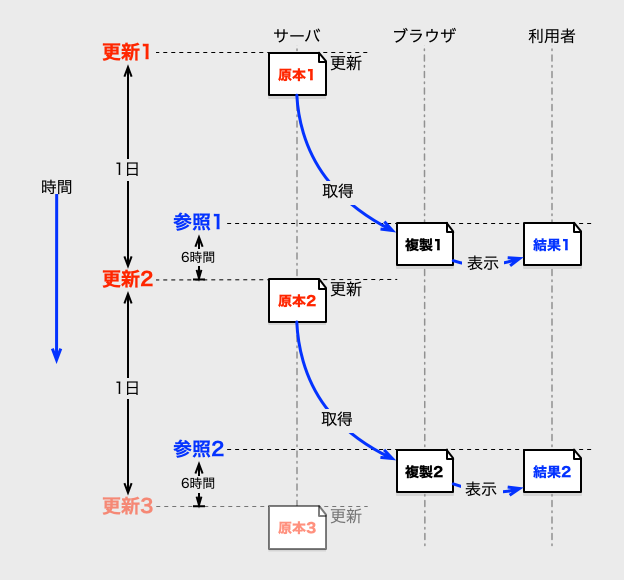
この様に、キャッシュ期間を短くすれば、反映の遅延は抑えられます。
しかし、キャッシュ期間を短くすると、通信コストを削減する効果は下がります。 その問題は、参照の頻度が高いときに顕著です。
イメージしやすいように、以下の図は、参照の頻度以外の条件を同じで、キャッシュ期限を少し超える6時間強の間隔で、参照を3回繰り返した場合の例です。
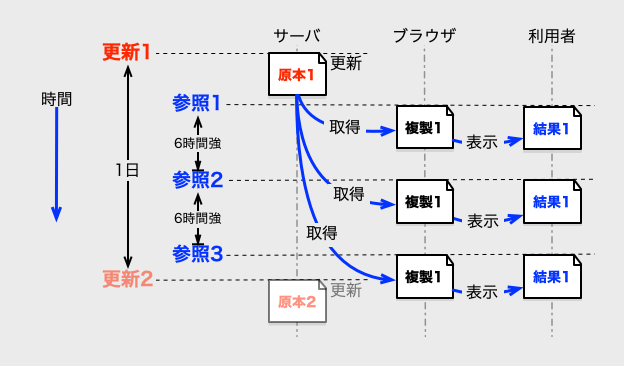
更新されていないのに、「原本1」のデータが無駄に3回取得されています。
このように、キャッシュ期間を短くしすぎると、キャッシュが活用されず、無駄な通信が増えます。
更新が反映されなければ、新しい情報を提供する意味もなくなりますから、キャッシュ期間はあまり長くできません。しかし、逆にキャッシュ期間を短くすると、キャッシュ再利用も減ってしまいます。
このように、キャッシュ期間には、反映の遅れと通信効率についてトレードオフの関係があります。 そのため、適切な設定が意外と難しいのです。
つづく
HTTPキャッシュ制御の基本的な部分まで説明しましたが、この基本的なキャッシュ期限のみの制御は、正直なところ微妙です。
それでは困るので、もちろんHTTPキャッシュ制御にも、それらの対策が組み込まれています。
と言うわけで、その対策などのHTTPキャッシュ制御の応用的な仕組みの話が続きます。
次回「HTTPキャッシュを使いこなして、Webアプリを快適に(2)」もぜひ読んでください。




