日本の東西でデータ同期 – 東西分断しても動き続けるオブジェクトストレージを作る
2020年12月23日 水曜日

CONTENTS
【IIJ 2020 TECHアドベントカレンダー 12/23(水)の記事です】
あるリージョンに何か起きても他のリージョンは健全に動かしたい
今回は「IIJオブジェクトストレージサービス」でどのようにリージョン間でデータを共有しているか説明します。
IIJオブジェクトストレージはs3相当のAPIを備えたオブジェクトストレージです。東日本、西日本の2つのリージョンを提供しており西日本リージョンを先行してリリース、東日本リージョンは2019年7月にリリースしました。今回はこの東日本リージョンのリリースの際に検討、実装した内容を書いています。
東西2つのリージョンはそれぞれ異なるデータセンターにあり設備は独立しています。しかしデータ(※)のレイヤーで考えてみると完全に独立はしていません。何種類かのデータを東西で共有する必要があります。
(※)この文脈の”データ”はお客様のデータを管理するために使うデータ(メタデータ)を指しています。
東西リージョンができることで東西の通信ができなくなる分断状態、そして片方のリージョンに障害が起きて機能不全になることを考慮しないといけなくなりました。
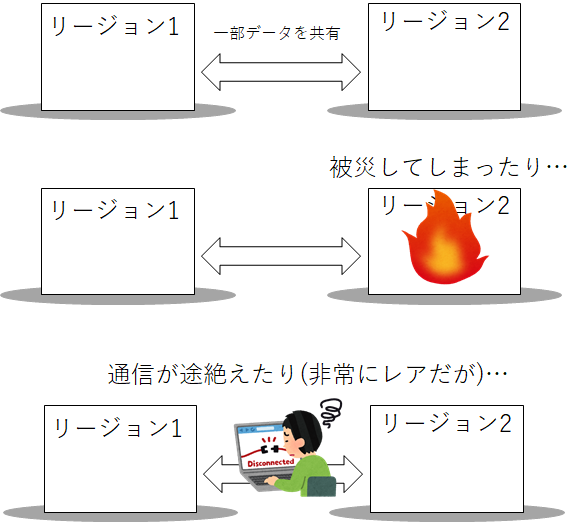
このような事態に陥ってもサービス提供が継続できる仕組みを実現できないか検討しました。
東西で共有が必要な情報の代表的なものがバケットの情報です。バケットとはオブジェクトストレージでデータ(オブジェクト)を格納する領域、入れ物です。
IIJオブジェクトストレージではバケットの名前は東西で重複を許していません。このことが設計を難しくしています。
DBをIIJのプライベートバックボーン越しにクラスタリングする
東西でのデータ共有の実現方法はいくつか考えられます。東西間でAPIを相互に呼び合うことでも実現できますし、データベースでの同期でも実現できるでしょう。
今回は重複が許されないデータを扱います。一意制約が実装されているデータベースを使う方がアプリケーションの実装をシンプルにできそうだと考えデータベースを使って東西でデータを共有することにしました。同期用のネットワークは「IIJプライベートバックボーンサービス」を利用しセキュアに繋ぐことにしました。
データベースはMySQLを利用してきたのでそれを踏襲しました。レプリケーションの手段としてGroup Replicationが提供され始めた時期でしたのでこの技術を積極的に利用することにしました。遠隔2拠点に向いているようには思えませんでしたが、運用負荷が低い点が魅力的でした。Group Replicationは従来と比較してリカバリが非常に簡単です。障害が起きても再起動すればリカバリを自動で行ってくれます。
方針は決まったのですが離れた2つの拠点を跨いでMySQL Group Replicationを組んだ経験がありません。リージョンを跨げばサーバ間の遅延が大きくなるのは明らかです。データ更新の性能が低下することが予見されたので事前に設計を見直しリスクを回避することにしました。
東西で共有が必須なデータの絞り込み、更新頻度の整理を行いました。東西で共有が必須なデータに対する更新頻度は低いことが分かりました。更新頻度が高いデータは各リージョンで管理すれば良さそうです。そこで東西共有用と各リージョン用にデータベースを2つに分けることにしました。性能への要求レベルを下げることで実現可能性を上げる狙いです。また障害が起きた場合の影響範囲を分離することも狙っています。
次に技術検証を行いました。実際に遅延を仕込むことで性能がどのように変化するか、レプリカが外れることが無いか確認しました。2つのネットワークセグメントを用意しそこにデータベースサーバを配置してクラスタリングを行い、2セグメントをつなぐルータに遅延を仕込むことで検証を行いました。本番を想定して数十ミリ秒の遅延を入れて検証したところ参照、更新ともに性能は低下しますが実用可能な性能を有していることが分かりました。
分断が起きるとMySQLはどう振る舞うのか?
方針が決まったのでMySQLのクラスタを組んで障害試験をしてみます。東西が分断されてしまっても各リージョンで複数のサーバが稼働できるように5台でクラスタを組むことにしました。
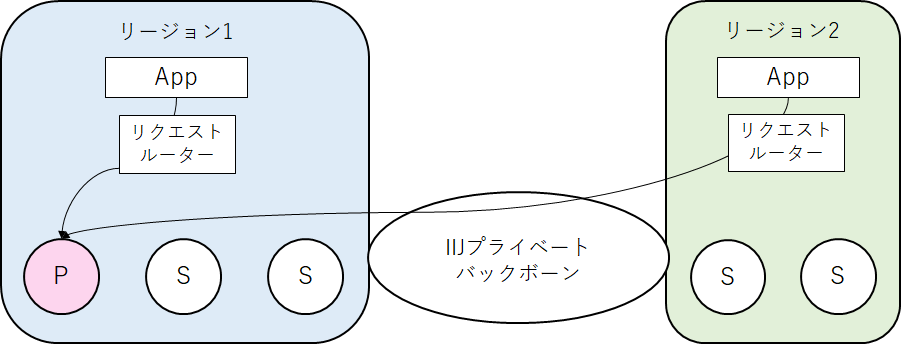
Group Rplicationによるサーバ間の通信、アプリケーションからのアクセスともにIIJプライベートバックボーンを経由します。 プライマリは更新、参照ができるサーバ、セカンダリは参照のみ可能なサーバです。
プライマリは更新、参照ができるサーバ、セカンダリは参照のみ可能なサーバです。
Group Replicationはプライマリ、セカンダリと役割が各サーバに割り当たります。プライマリの選出はクラスタに参加するサーバ同士の多数決で決まります。
過半数を獲得するとプライマリになります。上の図ではリージョン1にいる1台が多数決で過半数を獲得した場合を示しています。
では、東西を分断してみましょう。ちなみにIIJプライベートバックボーンは高い可用性を持っておりこのような事態が起きないように運用されています。
ただサービスとしてはここまで考慮して設計をしています。

リージョン1ではデータベースの更新、参照ともに可能ですがリージョン2では参照しかできなくなりました。
今度はプライマリがリージョン2にいる場合を考えてみましょう。この場合投票が発生し、リージョン1にプライマリが選出されます。
リージョン2にあったプライマリは更新を拒否する状態になり不整合の発生を回避します。

MySQL Group Replicationはネットワーク分断に対して適切に対処する設計がなされており少数側のセグメント側のデータ更新を適切にブロックし、データ不整合が発生しないように動きます。
この挙動がサービスの可用性として受け入れられるかを検討します。オブジェクトストレージの操作は大きくバケットの操作とオブジェクトの操作に区分されます。
オブジェクトストレージへのアクセスはそのほとんどがオブジェクトの操作です。リージョン障害が起きてもこの操作は何としても継続して提供しなくてはいけません。
オブジェクトの操作を処理する際は、操作の権限を確認するためにバケットのデータを参照しますが更新は実施しません。つまり更新ができないリージョンにおいてもオブジェクトの操作は継続できます。
しかしバケットの操作のうち、バケットの作成と削除はデータベースの更新が必須です。つまりリージョン障害がおきるとパターンによってはバケットの作成、削除ができなくなります。
お客様の利用状況を分析するとバケットの作成、削除の頻度は多くありません。このような障害の発生確率とのバランスを考え、苦渋の決断でしたが障害時にバケット作成、削除ができなくなることを許容することにしました。
そんな都合の良いリクエストルータがいない問題
前半の絵では省略していましたがGropu Replicationではクエリを目的のサーバに届けるためにリクエストルータが必要です。
Oracle社純正のMySQL Routerを検証しましたが分断を起こすと参照クエリでも実行できないことが分かり今回は利用できないと判断しました。これはデータ不整合を起こさないように慎重に作られている結果だと思いますが我々の期待する動きとは異なりました。
そこでProxySQLを利用することにしました。ProxySQLはOSSのリクエストルータです。MySQLとクライアント(アプリケーション)の間に配置します。MySQLのプロトコルまで踏み込んで処理を行うため、クエリの内容に合わせたルーティングが可能です。データの分散配置や特定のクエリしか許さないファイアウォール的な使い方など、様々な用途で利用できます。
前述のとおりProxySQLではサーバに対してどのようなクエリを投げるか細かく指定できます。
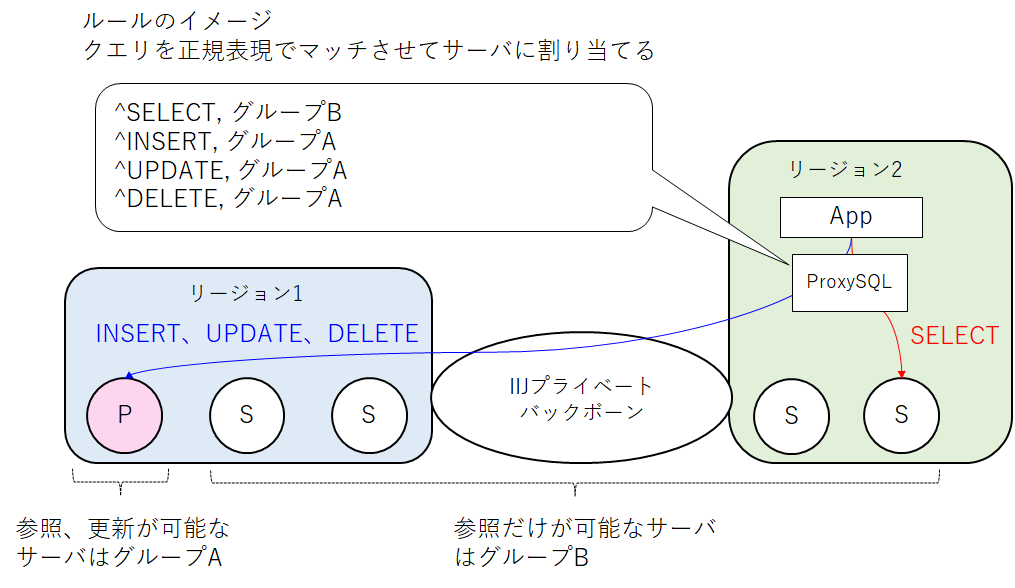
設定はクラスタの状態をProxySQLに提供するためのビューと、ルールを使って行います。ルールの適用条件は正規表現で書くことができ、マッチしたルールをどの状態のサーバへ投げるか指定できます。
今回はINSERT、UPDATE、DELETEのような更新系クエリはプライマリ、SELECTなど参照系のクエリはセカンダリへ振り分けました。
ここまでは順調だったのですが、アプリケーションとの結合試験で我々は大きな大きな過ちに気が付きます。
我々のアプリケーションはJavaで書かれておりJDBCでデータベースにアクセスをします。実装にはフレームワークを利用しています。
アプリケーションを書く際は意識をしませんが、SELECTやINSERTのような見慣れたクエリ以外にもSET句など様々なクエリ、コマンドをデータベースに送っています。
またSELECT文といっても、更新と同じような扱いとなるSELECT ~ FOR UPDATEをどこにルーティングするのかなど検討することは増えますしそれらを正規表現で拾い上げ、適切なデータベースサーバへルーティングするのは困難だと判断しました。
アプリケーションの改修やフレームワークのバージョンアップのたびにルールの見直しをするのは負荷も高く、現実的ではありません。
フレームワーク等が送っているクエリ、コマンドなどの例
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED SET autocommit=? SELECT @@session.transaction_isolation SELECT ? SET character_set_results = NULL commit SET autocommit=? commit SELECT @@session.transaction_read_only SELECT @@session.auto_increment_increment AS auto_increment_increment, @@character_set_client AS character_set_client, @@character_set_connection AS character_set_connection, @@character_set_results AS character_set_results, @@character_set_server AS character_set_server, @@collation_server AS collation_server, @@init_connect AS init_connect, @@interactive_timeout AS interactive_timeout, @@license AS license, @@lower_case_table_names AS lower_case_table_names, @@max_allowed_packet AS max_allowed_packet, @@net_write_timeout AS net_write_timeout, @@sql_mode AS sql_mode, @@system_time_zone AS system_time_zone, @@time_zone AS time_zone, @@transaction_isolation AS transaction_isolation, @@wait_timeout AS wait_timeout
この問題に対して解決策としてルーティングルールを極力シンプルにすることで対処しました。非常に乱暴ですがクエリのマッチング条件「.*」のような全マッチにし、全クエリをプライマリに送るように設定しました。しかしこれでは障害時にプライマリが見えなくなった場合に参照を継続することができません。この問題を救ったのもまたProxySQLです。
ProxySQLはルールやサーバの状態、クエリの統計情報をmysqlコマンドを経由して取得、操作することが出来ます。
設定値や現在の状態がそれぞれ特殊なテーブル(ビュー)にマッピングされており、SQLで操作できるのです。
我々はこの機能を利用し簡単なスクリプトを書くことで対処しました。ProxySQLを介してサーバの状態を監視し、書き込み可能なサーバが見えなくなった段階でセカンダリへクエリが向くようにルールをスクリプトが更新します。
これにより、当初考えていた動作が実現できました。

まとめと今後の展望
MySQL Group Replicationはネットワーク分断に対して適切に対処する設計がなされており少数側のセグメント側のデータ更新を適切にブロックし、データ不整合が無いように振る舞います。この動作とうまく協調しながら、目的の可用性を実現する仕組みをデータベースクライアント側の動作を調整することで実現することが出来ました。
今回の設計ではクライアントがデータベースにアクセスするネットワークと、データベースが東西で同期するネットワークは同じものを利用しています。
これがネットワーク分断時の設計を難しくしています。ここは改善点かもしれませんが、一方で必要な可用性に対して過剰な投資となる可能性もあるためコストや運用面でのバランス感覚が必要となってくるポイントだと思います。
今作るとすればどう作るでしょうか。地理分散を実現しながら、強い整合性を持つデータベースが多く出てきています。
「NewSQL」と呼ばれているようですがNoSQLであきらめていた部分を様々な分散システムの技術を組み合わせることで改善したデータベースです。
分散トランザクション、データベースのシャーディング、Raftによる合意形成などキーワードを拾うだけで興味がそそられます。
そのような新しい技術の利用も検討しつつ、安定したサービスを提供できるように検証、改善を進めていきたいと思います。