Docker Swarmでお手軽に冗長なMariaDBを作る
2022年11月30日 水曜日

CONTENTS
こんにちは、九州支社技術部(九州・中四国事業部)所属のy-morimotoです。
最近は、AWSのRDSなどで、冗長なDBはクリックポンで作れてしまいますが、自前で冗長なDBを作ろうとすると、何気に大変なイメージがあるかと思います。
ところが今回、そんな大変なイメージを払拭出来そうな、素晴らしいコンテナイメージを見つけましたので、ちょっとご紹介させて頂きます。
1.使うコンテナイメージ
使うコンテナイメージはbitnami様のbitnami/mariadb-galeraです。
これをDocker Swarm環境に展開して、冗長なDBをお手軽に作りたいと思います。
2.mariadb-galeraの概要
mariadb-galeraは3つのDBで冗長構成します。
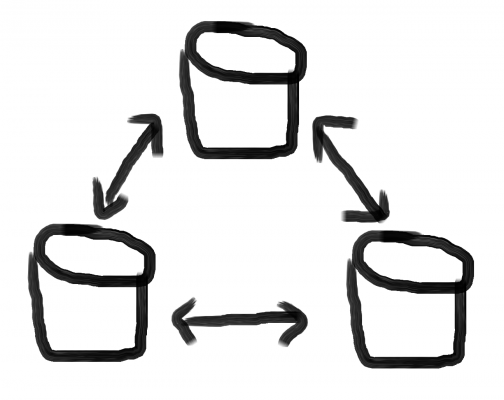
どのDBでも更新と参照が可能です。
3つのうち2つ動いていれば、継続して動いてくれる特性を持っていますが、
1台だと動かなくなる、ちょっと寂しん坊です。
その為、最初の起動は1台でも動くような細工が必要です。
3.yamlファイル
Docker SwarmでDBを動かすために、今回はyamlファイルを3つ準備します。
| docker-compose.yaml | DB3台とAdminer(WEBでDB操作できるツール)の定義yaml |
| init1.yaml | 初期起動step1(DB1個で動かす)の定義yaml |
| init2.yaml | 初期起動step2(DB1個で動いている所に、DB2個参加させる)の定義yaml |
作成したものがこちらになります。
https://github.com/iij/maria
4.動かしてみる
環境の準備
以前「ブラウザだけでDockerしたい」で紹介しました、Docker Playgroundで実際に動かしてみましょう。
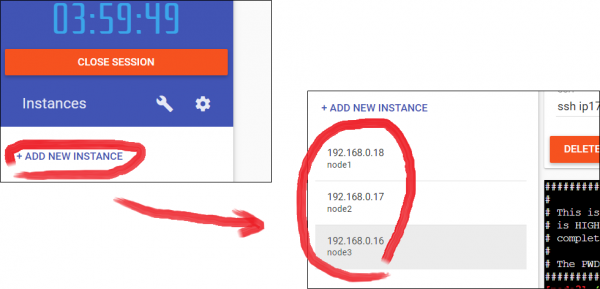
まずログインしたら「+ADD NEW INSTANCE」で3つnodeを作ります。
Swarmの構築
次に Swarm を組みます。node1でinitして
docker swarm init --advertise-addr=eth0 --listen-addr=eth0:2377
node2/3をmasterで追加する為のjoin-tokenを確認し
docker swarm join-token manager

確認で表示されたコマンドをnode2/3で実行します。
(ブラウザのコンソールからは直接コピーが出来ないようなので、ssh接続して実行するか、適当なファイルにリダイレクトして[EDITOR]ボタンから開いてコピーすると良いです。ペーストは shift+insertで出来ました。)
docker swarm join --token {TOKEN} {IP}:{PORT}
正しく追加できたことをnode1で確認します
docker node ls

ファイルの準備
Swarm が組めたら、次はyamlファイル等の準備です。
node1/2/3いずれか、どこのnodeでやってもOKです。
git clone https://github.com/iij/maria.git
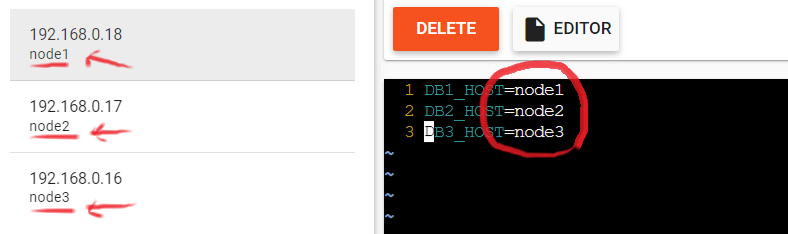
cloneしたら、ディレクトリに移動して、.env(環境設定ファイル)を編集します。
cd maria vi .env
.env の中身は、ADD NEW INSTANCE で出来た node名に合わせて更新します。(node1/2/3 であれば更新不要です)
次に、パスワード定義ファイルを作成します。
echo 'お好みのパスワード' > .DB_PASSWORD
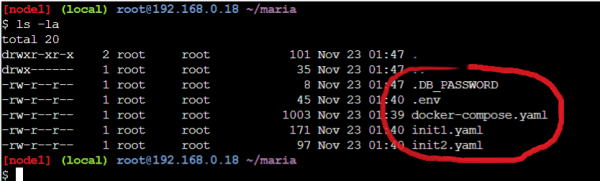
.env と .DB_PASSWORD を作成出来たら、正しくファイル準備できたか軽く確認します。
ls -la
3つのyamlと.envと.DB_PASSWORDが有る事を確認します。
yamlファイルの簡易な構文チェックも行います。
docker compose convert
コマンドを実行した結果、docker-compose.yaml中のDB1_HOSTなどの環境変数が正しくnode1などになっており、エラーが表示され無ければOKです。
DBの起動
yamlファイル等の準備も終わったら、次はいよいよ起動です。
下準備
DBの展開は、docker stack deploy で行っていきますが、composeと違って.env が反映されないので、ちょっと下準備します。
対策はenv $(cat .env)してdocker stack deployすればOKですが、毎回入力は面倒なのでaliasを作ります。
alias dsd='env $(cat .env) docker stack deploy'
DB1を単独モードで起動
まずは、docker-compose.yamlとinit1.yamlでDB1を単独起動します。stack名はmariaにします。
dsd -c docker-compose.yaml -c init1.yaml maria
DB1のサービスが起動して 1/1 になっている事を確認します。
docker stack services maria

1/1になっていたら、Adminerを使って実際にDB1に接続してみましょう。
[OPEN PORT]ボタンを押して、ダイアログに「8080」を入力して開きます。
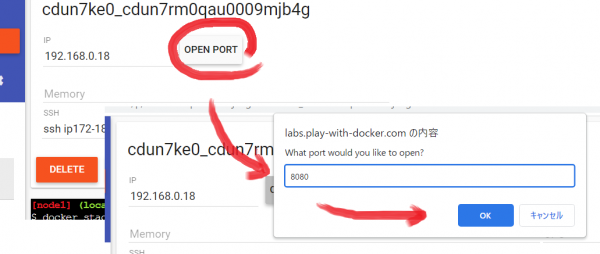
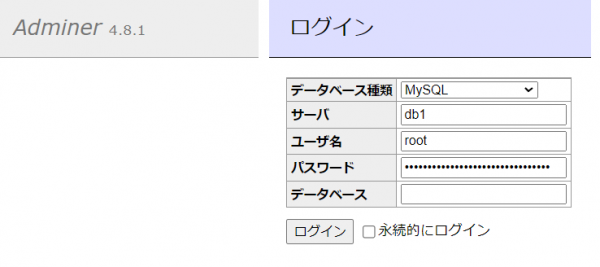
ログイン画面が表示されたら、サーバに「db1」ユーザ名に「root」パスワードに .DB_PASSWORD に設定した内容を入力して、ログインします。
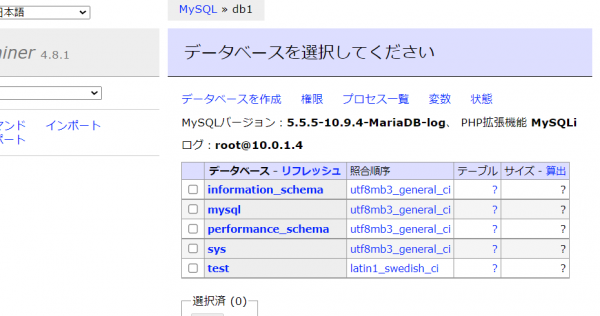
ログインに成功して、正常にデータベースのリストが表示されたら、DB1は起動完了です。
DB2/3を起動
DB1の起動が確認出来たら、docker-compose.yamlとinit2.yamlでDB2/3を起動します。
dsd -c docker-compose.yaml -c init2.yaml maria
DB2/3のサービスが起動して1/1になっている事を確認します。
docker stack services maria
(少し時間がかかる場合があるみたいです。docker service logs -f maria_db2などで起動時のログを眺めたりしながら1/1になるのを待ちましょう。)

1/1になったら、DB2/3もAdminerで接続確認してみましょう。
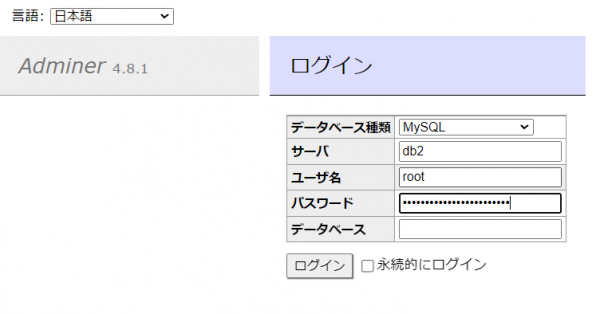
サーバに「db2」「db3」、ユーザ名とパスワードはDB1接続時と同様に「root/.DB_PASSWORDの値」でログイン出来ればOKです。
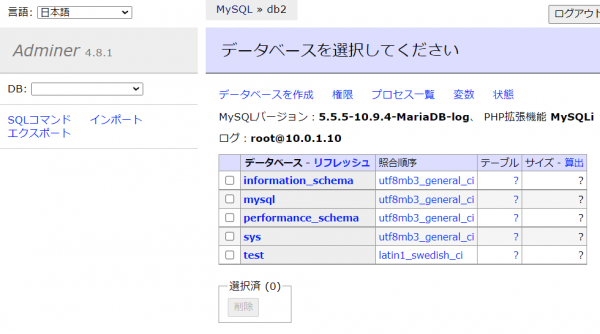
DB1を通常起動に切り替え
DB2/3も起動できたら、docker-compose.yamlのみでDB1を通常起動に切り替えます。
dsd -c docker-compose.yaml maria
(これをしておかないと、init1/2.yamlの状態のDB1は、障害などで再起動された時に、DB2/3のメンバとして参加してくれません。)
DB1が再起動されて0/1になるので、再度1/1になる事を確認します。
docker stack services maria
(これも少し時間がかかる場合があるみたいなので、docker service logs -f maria_db1でDB1の再起動のログでも見たりして1/1になるのを待ちます。)
1/1になって、AdminerからDB1に接続出来るようになれば、冗長なDBの構築完了です、お疲れ様でした!
出来上がったら
あとは、AdminerでDB1/2/3のいずれかに適当に接続し、テーブルを作ったら他のDBに連携されてることなどを確認したりして、遊んでみてください。
5.注意事項とか
MariaDB Galera Clusterの注意点としては、多重障害耐性が必要な場合は使えません。
例えばどこかの1つだけ停止(他のDBが生きている)であれば、再起動後はクラスタに再参加して自動復旧されますが、全部止まった場合は、init1/2.yamlの手順を踏む必要があります。
あと、今回パスワード1個を共通で使っていますが、実際には目的ごとに使い分ける事が出来、本来は分けた方が良い(ハズ)なので、そのあたりは適宜docker-compose.yamlを変更してみてください。
6.停止手順
最後に停止手順です。
今回準備したinit1/2.yamlでは、DB1を最初に起動する形にしているので、最後の更新がDB1になるように、先にDB2/3を止めてから、最後にDB1を止めます。
docker service rm maria_db2 docker service ls docker service rm maria_db3 docker service ls docker stack rm maria docker stack ls
docker stack service lsで、1つ1つ消えたのを確認しながら、service rmしていきます。
なお、DBデータ保存先はvolumesのdb_dataで永続化しているので、最後にstack rmしてもDBデータまでは消えません。
再度init1/2.yamlからstack deployすれば、引き続きDBデータを利用する事ができます。
(逆に、DBデータも完全に消してしまいたい場合は、各nodeでdocker volume rm maria_db_dataして、volumeを削除してください)
7.といったところで
いかがでしょうか?
git cloneしてdocker stack deployを3回たたけば構築完了なので、自分ではかなりお手軽と思っています。
個人的には、最近HA機能が付いたZabbixのyamlを準備し、このDBと組み合わせて、お手軽に冗長構成な監視システムに仕立て上げたいなど考えてたり。
yamlは自由に改変してご利用いただいて大丈夫なので、皆様も是非色々お試しください。




