Hugging Face Pipelineを使ったお手軽AIプログラミング
2023年02月16日 木曜日

CONTENTS
Hugging Faceってご存じですか?
AIを使用したプログラム・スクリプトを作る際、ゼロから起こす場合は以下のような部分を作り込んだり、Githubなどのリポジトリサイトからソースを入手したりする必要があったりします。
- AIモデル
- トレーニングのためのロジック
- 評価・テストのためのロジック
- データローダ
- トレーニング・評価データを読み込むためのフォーマット、読み込み処理・変換処理など
- チェックポイントの書き出し
Hugging Faceというサイトは、学習済みモデルやデータセットなどを公開するリポジトリサイトであると同時に、これらを手軽に利用するためのインタフェースともいえるようなライブラリを公開しており、学習済みモデルを使用した例えば英日翻訳の仕組みなどを簡単に実装することができます。有名なものとしては、自然言語処理系のモデルを取り扱う「transformers」というライブラリがありますし、Diffusion-Modelを使用した画像生成系処理を取り扱う「diffusers」ライブラリがあります。
私はStable-Diffusionを取り扱う際にこのサイトを知り、AIリポジトリとしては有名であるということからいろいろ触れるようになりました。
とりあえずtransformersを導入してみる
transformersライブラリはPyPIに収録されてますので、pipで容易にインストールができます。
pip install transformers
transformersでmBARTを使った翻訳機を作成してみる
transformersで翻訳機を作ってみたので、とりあえずまずはソースを記載してみます。
ここで取り上げる機械学習モデルはMeta社(旧Facebook社)が開発したBARTというモデルであり、これを多言語対応したmBARTというのを適用しています。
これは、これまた有名なBERT(Googleが開発した機械学習モデル)をもとにしており、BERTは全体をTransformerと呼ばれるブロックを使用して構築しているのに対して、BARTはこれより少し古いモデルであるSeq2Seqという再帰型ブロックを使用して組まれていることが特徴で、BERTと比べてパラメータ数を減らし、より少ないメモリリソースで駆動できることを目指したモデルです。
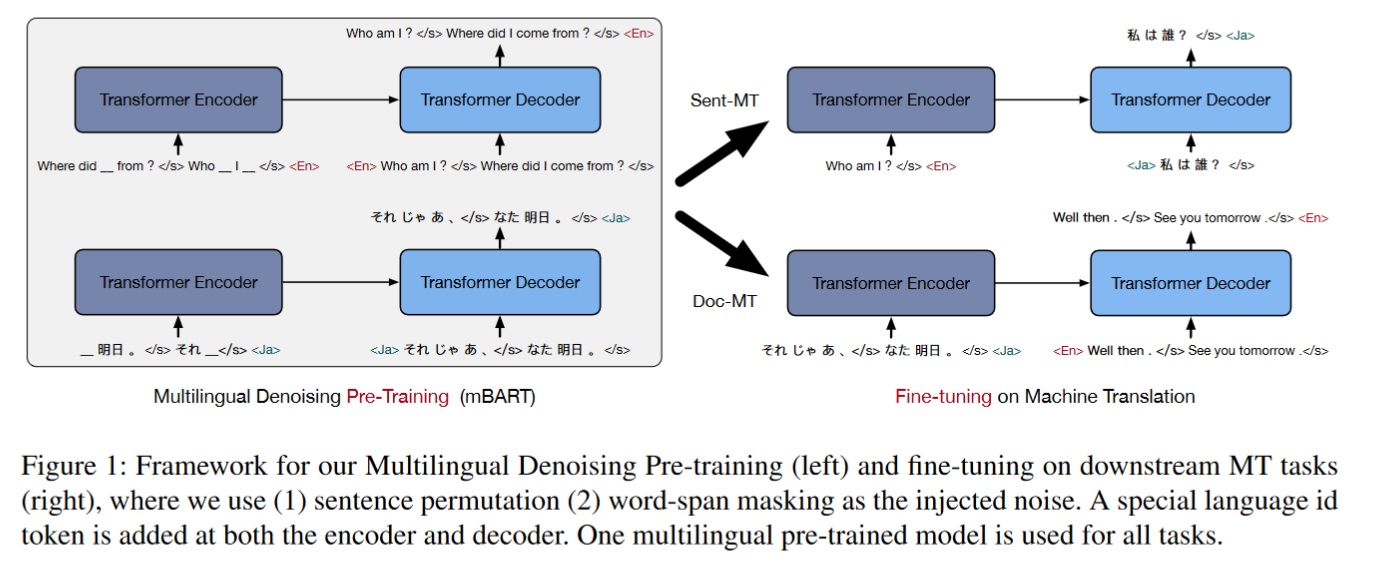
論文[Multilingual Denoising Pre-training for Neural Machine Trans]より引用
代わりに犠牲になるのが並列度で、直列型モデルであるがゆえに翻訳スピードは少し遅くなります。短い文章だとおよそ1分半、長い文章だと10分程度かかります。しかし、翻訳精度はなかなかのもので、私が使用できる環境も限りがあることからこれをよく使用します。
from transformers import pipeline, MBart50TokenizerFast, MBartForConditionalGeneration
import sys
import argparse
import os
#引数処理
parser = argparse.ArgumentParser()
parser.add_argument('--file',type=str)
optvar=parser.parse_args()
#モデルの入手
model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-one-to-many-mmt")
#トークナイザの入手
tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50-one-to-many-mmt")
#ソース言語・ターゲット言語の指定
tokenizer.src_lang = "en_XX"
tokenizer.tgt_lang = "ja_XX"
#トークナイザに投入する文字列長の指定
tokenizer.model_maxlength = 2048
#Pipelineを使用して翻訳タスクを実行するオブジェクトを作成する
pipe=pipeline("translation",model=model,tokenizer=tokenizer,src_lang="en_XX",tgt_lang="ja_XX",device=0,batch_size=16)
#翻訳元ファイルを開いて、翻訳処理を開始する
with open(optvar.file) as f:
for line in f:
#翻訳処理を実行する。最大長は1024とし、truncate処理は有効にする
translations = pipe(line,max_length=1024,truncation=True)
#原文の表示
print(line)
#翻訳結果の表示
print(str(translations[0]["translation_text"]))
#空行を挿入
print("\n")
このスクリプトを動かすにあたって、英語の文章を用意しときます。
DeepLを使用して以下のような英訳文を作り、これをテキストファイルとして保存します。
■原文 このテキストは、DeepLを使用して日本語から英語に翻訳をしたものになります。 ここで英語で生成されたテキストをmBARTに通して、どのように日本語に訳されたかを確認してみることを目的として作成しました。 Hugging Faceは非常に便利で、私もよく活用しています。 ■DeepLで英訳 This text has been translated from Japanese to English using DeepL. The text generated here in English was created for the purpose of running it through mBART to see how it was translated into Japanese. Hugging Face is very useful and I use it often.
そしてこれを先述したスクリプトにかけるとこういう出力になりました。
■mBARTで翻訳 This text has been translated from Japanese to English using DeepL. このテキストは、DeepLを使用して日本語から英語に翻訳されています。 The text generated here in English was created for the purpose of running it through mBART to see how it was translated into Japanese. 英語で作成されたテキストは、MBARTを通して日本語に翻訳する方法を確認するために作成されました。 Hugging Face is very useful and I use it often. ハンギングフェイスは非常に有用であり、私は頻繁にそれを使用します。
たったあれだけのコードでここまでできるのか!?ということで、当初はかなり驚きました。
ただ、別にpipelineなどのステートメントだけですべての処理をしてるわけではなく、実はHugging Faceのリポジトリから必要なデータをダウンロードしていたりします。
Hugging Face transformersの仕組み
transformersが導入された段階で、Pythonキャッシュ(ホームディレクトリ配下の.cacheディレクトリ)が作られますが、そこにモデルがダウンロードされてない場合、transformersは必要なファイルのダウンロードを開始します。以下はdiffusersライブラリを使用した場合ですが、Stable-Diffusion v2.1をPipelineで動かそうとしたとき、以下のような表示が標準出力に出てきました。

12個ほどファイルがダウンロードされているのがわかりますね。この中でいくつかGB単位でダウンロードされているものがありますが、これがモデル本体であろうと容易に推察できます。Hugging Faceへの接続先となるFQDNは一貫して「huggingface.co」であり、TLS1.2で暗号化された状態で通信され、基本的にはダウンロード処理が大半であることを確認しています。ほかには、APIトークンを要求する場合の認証処理が行われていることを確認しています。
Hugging Faceはこうしてダウンロードした必要なデータを以下のように管理しています。

Huggingfaceからダウンロードされたファイルの配置状況
ファイル本体はBLOBとして16進数で示すユニークな名称で保存され、それがSnapshotsディレクトリ内のシンボリックリンクを経由して使用するような形態をとってるようです。シンボリックリンクとして記載されているのは、必要となるモデルの周辺設定データであり、モデル本体は拡張子「.bin」で格納されていることがわかります。
最上段はライブラリ名で別れていますが、transformersでダウンロードしたものに関してはHugging Face Hub経由でダウンロードしたものとして取り扱われるようです。
この仕組みの何がうれしいか、そして何が苦手か
この仕組みの何がうれしいかというと、少なくともモデルの評価が手っ取り早くできることです。頭でアイデアが浮かんだときにぱっとそれを形にできるというのは非常にありがたいです。例えば、以下の図は日々の調査の中で「もーちょっとarXiv.orgからダウンロードした論文、簡単に日本語訳出来ないかなー」とか思ってスクリプトを作ったときの処理の流れをざっくり書いたものです。
この時、DeepLなんかも活用してみたりはしたのですが、DeepLは文の途中で改行が入るとそこで文を打ち切って翻訳する特性があったため、そのままコピペするだけでは翻訳内容が重複してうまく読み取れなくなることが多く、それがまた面倒だったりしたのです。
そこで、別の用途で使ってたmBARTの翻訳精度がなかなか良かったので、これを活用して別のライブラリなども使用しつつ翻訳機を作ったのですが、そのコアエンジン部分のソースが先述したPythonスクリプトというわけなのです。
このように、手間をかけずにまずは形を作ってみるというところで、こうしたHugging Faceのライブラリは非常に役に立っています。完全に内部システムとして動かす場合は、これらの必要なソースなりPretrained Modelなどをダウンロードしてきちんと組み上げていけばよいのだと思います。
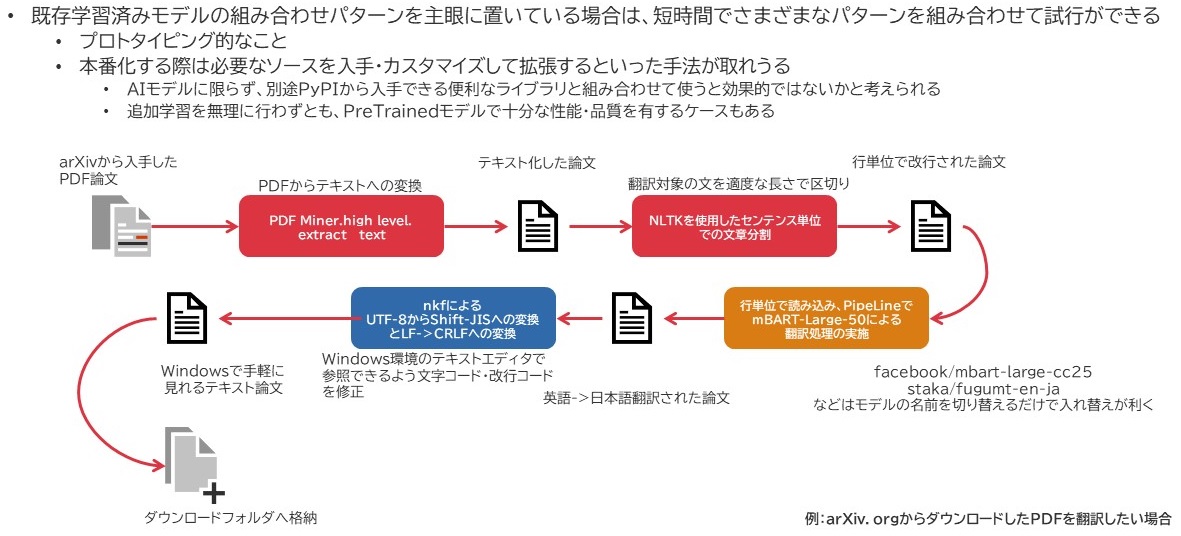
arXiv.orgからダウンロードする論文をもう少し手軽に読みたいという考えから。
反面、こうした仕組みはしっかり仕組みを読み込まないと意図しない通信先へ通信が発生し、気づかないところでデータ漏洩リスクが発生する場合があることです。
AIモデルの中にはAPI処理だけを公開しており、モデルそのものはローカル環境で動かせないものがあったりします。代表的なものでいうとGPT-3などがそうですね。GPT-3はそのことを強く表に出しているので問題ないと思いますが、この辺りの仕様を隠ぺいしていて、GPU動いてないなーと思ったら実は意図しないサーバへAPIリクエスト出して投入したデータが外へ出ていったということは少なくないと思います。(Baidu(PaddlePaddle)のERNIEなどはGitHubで提供してるソースを見る限りRESTAPIへのリクエストを投げる処理しか記述されておらず、どうやら本体はBaiduが保有する巨大クラスタの中にあるようです。OpenAI-GPT3と似たような感じですね。)
また、インターネット接続を前提としているため、キャッシュがない状態でこのプログラムを動かした場合にHugging Faceと通信ができずにエラー終了するケースがあります。その際、Python側はダウンロードに失敗したことは表に出さず、単純に「必要なソースがない」とエラー出力をします。そのため通信障害が原因であることがわかりにくいというところが原因切り分けとしてわかりづらいポイントになりそうです。
Hugging Faceはステータス情報を公開していますので、これはちょくちょく見ておいて損はないかと思います。
データダウンロード時にはいろいろ考慮事項がありそう
同時に、昨今のAIモデルは実に巨大なものが多いです。バージョン更新を検知するとSnapshot更新のために再度モデルデータ等がダウンロードされることがあり、数GB~数十GBあたりのダウンロードが突然発生して処理が止まることもあります。こうした処理の特性は知っておいて損はないんじゃないかな?と思いますので、Hugging Faceで公開される情報等には気を配ったほうがよさそうです。
企業などではプロキシを介してダウンロードをすることもあろうかと思いますが、特にSSLインスペクションなどを使ってるところではトラフィック量は増えることになります。今回はモデルとして利用する場合の説明を記述していますが、ほかにもデータセットをダウンロードすることもできます。この時大きなモデルでは数TB~数十TB規模のダウンロードが発生したりもするため、こうしたものをダウンロードするときに対する考慮事項もおのずと増えるのではないかと思います。
なお、ちょうどこの前ニュースで少し話題になってたReasonSpeechのデータフルセットを入手してみようと、Hugging Face datasetsを使用してダウンロードをしてみたのですが、圧縮状態のデータが1.3TBほどダウンロードされまして、それだけで2日ほど時間を要しましたし、さらにその後のベリファイ処理で16時間ほどを要しました。さらにこれを展開してデータセットを扱うことを考えると数TB規模のストレージをサイジングする必要がありそうです。
EASTUS2リージョンのAzureVMでこの確認は行っていたのですが、常時300Mbpsぐらいの帯域が出ていてもこれほど時間がかかるということから、まぁなかなか骨の折れる処理が必要だし、その間トラフィックを受信し続けられるゲートウェイも必要になってくるなぁと考えるとあまり軽い気持ちで巨大データセットをフル入手することは難しいなと感じました(Hugging Face datasetsには一応、ストリームデータとしてデータセットを利用することも可能なので、そうした対応でトラフィック負荷を軽減する対応はとれるかとは思います)。
私たちITインフラエンジニアはそうしたところに一定の価値を見出すこともできるのではないか?と感じる今日この頃です。




