A100GPUでGPU Benchmark 動かしてみた
2024年07月16日 火曜日

CONTENTS
はじめに
はじめまして。IIJクラウドサービスの基盤チームに所属しているyukihです。こちらは以前の2つの記事、AI/ML向け汎用GPUサーバの中身をご紹介 | IIJ Engineers Blog、マルチノードGPU通信をやってみた | IIJ Engineers Blog に引き続きGPU環境を使用した記事となります。私は、いままでGPUやAIに関わっておらず、このGPUがどれほどの性能かわからなかったため、「GUIを使用しないベンチマークを動作させ、性能を数値化してみた話」という内容で記事を書いてみたいと思います。
実行環境
使用するベンチマークの概要
tensolflow/benchmarks tf_cnn_benchmarks
-
- TensorFlowが公開しているベンチマークテスト(Tensorflow使用)
- 画像分類問題に対していくつかのパラメータを指定して実行すると,1秒あたりに学習した画像枚数を出力
- benchmarks/scripts/tf_cnn_benchmarks at master · tensorflow/benchmarks · GitHub
lambdal/deeplearning-benchmark
-
- lambdalが公開しているベンチマークテスト(Pytorch使用)
- 画像分類だけではなく、様々なモデル (transformer, bertなど) を使い、計測可能。
- deeplearning-benchmark/pytorch/README.md at master · lambdal/deeplearning-benchmark · GitHub
環境
ソフトウェア
- OS : Ubuntu Server 22.04 LTS
- Python3 3.9.6
- NVIDIA Driver : 535
- Docker : Latest (2023/11/20)
- NVIDIA container-toolkit : Latest (2023/11/20)
- Tensorflow : 2.14.0 (tensorflow/tensorflow:2.14.0-gpu)
- Pytorch : 2.1.0 (nvidia/pytorch:23.06-py3)
ハードウェア
- GPU:NVIDIA A100 (80GB)
- サーバ:ESXi 7.0U3 上のVM
- 検証方法:PCIパススルー、MIG分割の2パターンで検証
検証方法
- Tensorflow Benchmark
- GPU 1枚での測定
- GPU 2枚での測定
- MIG分割したGPUでの測定
- Pytorch Benchmark
- GPU 1枚での測定
- GPU 2枚での測定
検証結果
Tensorflow Benchmark
検証1:GPU1枚、GPU2枚
まずは、NVIDIA A100の結果になります。左の濃い緑がGPU1枚、右の薄い緑が2枚の結果です。また、この検証では層が多く、計算量が多いモデルresnet152_v2と、軽いモデルであるlenetを用いました。
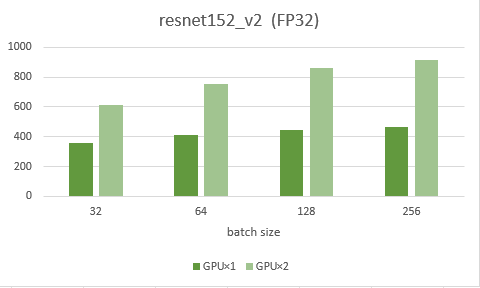
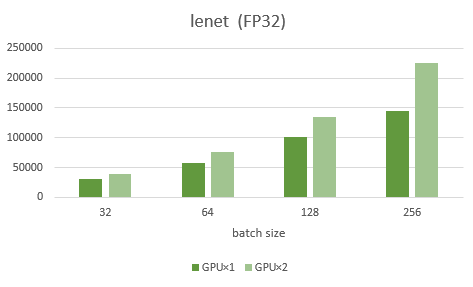
結果として、軽いモデルであるlenetではバッチサイズが少ないほどGPU1枚と2枚の結果が変わらず、有効的に使えてないことがわかります。重いモデルであるresnetでは、バッチサイズが多くなるほど2倍に近い数値を出せており、有効的に使えていることがわかります。よって、GPUを2枚使う場合、計算量が多いモデルであれば、2倍に近い数値を出せることがわかりました。
検証2:MIG分割
次に、NVIDIAの上位モデルに搭載している1枚のGPUを複数に分割して使用できるMIGを使って検証しました。グラフでは左からMIGを使わずに1枚使った時、MIGでの80G、40G、20G、10Gとなります。また、MIGでは、GPUが物理的に8つのブロックに分かれておりそのうちの7つのブロックを割り当てることができます。グラフにあるMIGの後の数字はそのブロック数を示します。
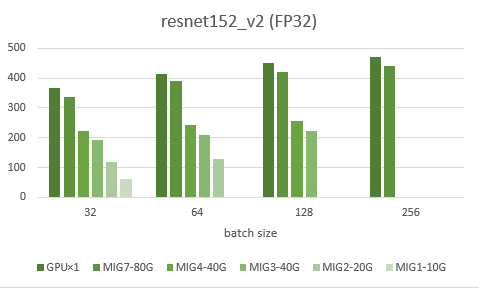
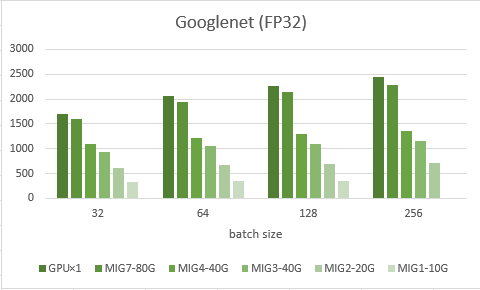
結果として、まずそのままGPUを1枚使うのに比べ、MIGの80Gは5~10%のロスが発生していました。これは、最大でも8ブロック中7ブロックしか使えないからだと考えられます。次に、メモリ量の違いですがこちらは想定通り、メモリ量に大体比例して結果も減少しました。また、3ブロックの40Gと4ブロックの40Gでは、5~10%ほどの違いが出ることもわかりました。
今回、MIGというものを初めて使用しましたが、パススルーよりもかなり実行時間がかかったり、途中で止まってしまうことが何度かあり、安定して動かすのが難しかった印象がありました。
Pytorch Benchmark
初めにこの lambda/deeplearning-benchmark は、様々なGPUでのベンチマーク結果がLambda社から公開されています。
(参考: GPU Benchmarks for Deep Learning | Lambda (lambdalabs.com) )
そのため、この検証では、GPUと使用コンテナが同じ場合に他のハードウェアが異なると結果がどう変わるのかに焦点を当てました。
以下に、GPU1枚と2枚の検証結果を示します。


結果として、GPU1枚での結果は上記にのせたLambda社が公開している結果とほとんど同じ数値になりました。また、2枚目のほうでも、waveglow以外のモデルについてはほとんど同じ数値になりました。したがって、このBenchmarkでは、GPU以外のハードウェアはほとんど関係なく、ソフトウェアによって結果が変わると考えられます。
まとめ
今回、ほとんど知識がない状態でとりあえず動かしてみようという感じで行いましたが、計測結果を出すことが出来たのでよかったです。今回はGPUが1種類のため比較はできませんが、もし機会があったら実際に比較してみたいと思います。また、この内容を社内の有識者に見てもらったところFP16,32だけでなく8など試すとよいなどいくつかの助言をいただいたので、今後パラメータの調整などを行い、より詳しく動かしてみようと思います。