マルチノードGPU通信をやってみた
2024年06月04日 火曜日
CONTENTS
はじめに
はじめまして。IIJクラウドサービスの基盤チームに所属しているshimada-kです。昨今の生成AI/LLM(大規模言語モデル)の盛り上がりはすさまじいものがありますが、遅ればせながら、私たちのチームでも様々な角度から検証を始めております。先日、同僚のt-moriyamaが、GPUサーバに関する記事(https://eng-blog.iij.ad.jp/archives/24836)を投稿しましたが、こちらはその環境を使用した後続の記事の一つとなります。私はこれまでインフラに関する仕事に携わってきたこともあり、最初のテーマとして「Ethernet上でマルチノードGPUによるDeep Learning環境を構築、動作させてみた」という内容で記事を書いてみたいと思います。
今回のゴール
さて、テーマとしては上述のとおりなのですが、そもそも検証用のGPUサーバは1台しかありません(ただし、GPUは2枚搭載されています)。また、GPUノード間を接続するための検証用のネットワーク機器も限られています。これらの条件で、ロスレスイーサネットを含めた本格的な検証を行うのは無理があります。そのため今回は、実際にDeep Learningのコード(画像分類)を書いて、Ethernetを経由したGPUノード間の通信を発生させるところまでをターゲットにすることにしました。今後行うであろう本格的な検証の前提知識として活用できればよいかなと思っています。
検証構成
まず、必須となるGPUサーバですが、以下が搭載されています。
- NVIDIA A100 TENSOR CORE GPU x 2
- Intel Ethernet 25G 2P E810-XXV
上記のネットワークアダプタはRoCEv2/RDMAをサポートしていますので、GPUとNICを1つずつpassthroughしたVMを作成することにしました。構成としては以下のような感じです。
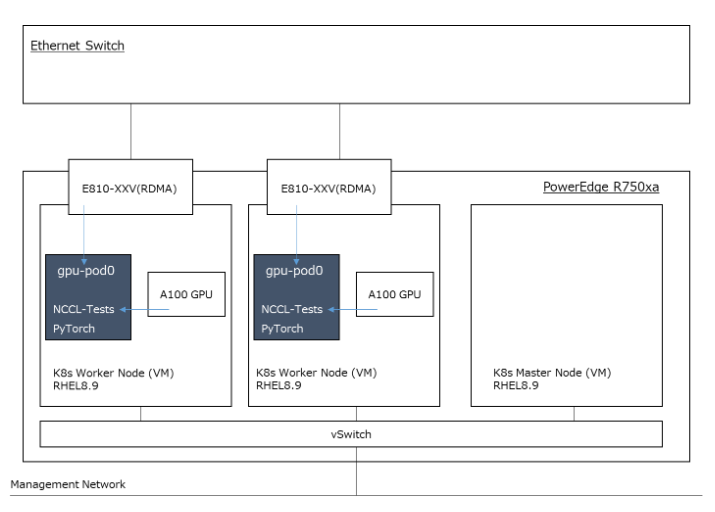
今回の内容にKubernetesは必須ではありませんでしたが、本番環境では使うことになるでしょうから、この構成にも含めました。なお、OSやKubernetesのバージョンは、NVIDIA GPU Operatorの「Supported Operating Systems and Kubernetes Platforms(Bare Metal / Virtual Machines with GPU Passthrough)」(https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/latest/platform-support.html#supported-operating-systems-and-kubernetes-platforms)に合わせています。コンテナランタイムも同様です。(https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/latest/platform-support.html#supported-container-runtimes)
KubernetesのDeploy
まずはKubernetes Clusterを構築します。1 Master Node + 2 Worker Node(GPU Node)の構成です。GPU PodがpassthroughしたNICへアクセスする必要があるため、Multusとwhereabouts(IPAM)もDeployしています。
[root@master0 ~]# kubectl get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME gpu0 Ready <none> 2d19h v1.28.9 10.138.61.54 <none> Red Hat Enterprise Linux 8.9 (Ootpa) 4.18.0-513.5.1.el8_9.x86_64 containerd://1.6.31 gpu1 Ready <none> 2d19h v1.28.9 10.138.61.55 <none> Red Hat Enterprise Linux 8.9 (Ootpa) 4.18.0-513.5.1.el8_9.x86_64 containerd://1.6.31 master0 Ready control-plane 2d20h v1.28.9 10.138.61.49 <none> Red Hat Enterprise Linux 8.9 (Ootpa) 4.18.0-513.5.1.el8_9.x86_64 containerd://1.6.31 [root@master0 ~]# kubectl -n kube-system get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES calico-kube-controllers-7c968b5878-4mt9t 1/1 Running 0 2d20h 192.168.84.195 master0 <none> <none> calico-node-b6mcs 1/1 Running 4 (22h ago) 2d19h 10.138.61.54 gpu0 <none> <none> calico-node-bpfsf 1/1 Running 3 (22h ago) 2d19h 10.138.61.55 gpu1 <none> <none> calico-node-jvmgk 1/1 Running 0 2d20h 10.138.61.49 master0 <none> <none> coredns-5dd5756b68-d4pzd 1/1 Running 0 2d20h 192.168.84.193 master0 <none> <none> coredns-5dd5756b68-vlsgc 1/1 Running 0 2d20h 192.168.84.194 master0 <none> <none> etcd-master0 1/1 Running 0 2d20h 10.138.61.49 master0 <none> <none> kube-apiserver-master0 1/1 Running 0 2d20h 10.138.61.49 master0 <none> <none> kube-controller-manager-master0 1/1 Running 0 2d20h 10.138.61.49 master0 <none> <none> kube-multus-ds-8zldw 1/1 Running 4 (22h ago) 2d19h 10.138.61.54 gpu0 <none> <none> kube-multus-ds-nk4sq 1/1 Running 3 (22h ago) 2d19h 10.138.61.55 gpu1 <none> <none> kube-multus-ds-xtmrc 1/1 Running 0 2d20h 10.138.61.49 master0 <none> <none> kube-proxy-958qs 1/1 Running 4 (22h ago) 2d19h 10.138.61.54 gpu0 <none> <none> kube-proxy-t4txb 1/1 Running 0 2d20h 10.138.61.49 master0 <none> <none> kube-proxy-tlld8 1/1 Running 3 (22h ago) 2d19h 10.138.61.55 gpu1 <none> <none> kube-scheduler-master0 1/1 Running 0 2d20h 10.138.61.49 master0 <none> <none> whereabouts-2jkkq 1/1 Running 3 (22h ago) 2d6h 10.138.61.55 gpu1 <none> <none> whereabouts-fc2wx 1/1 Running 0 2d6h 10.138.61.49 master0 <none> <none> whereabouts-z2nfl 1/1 Running 4 (22h ago) 2d6h 10.138.61.54 gpu0 <none> <none>
NVIVIA GPU OperatorのDeploy
NVIDIA GPU Operatorをインストールします。NVIDIA GPU OperatorはアプリケーションがNVIDIA GPU使用するために必要となるコンポーネントをDeployしてくれます。また、GPUの使用状況や性能を可視化するためのDCGM Exporter(https://docs.nvidia.com/datacenter/cloud-native/gpu-telemetry/latest/dcgm-exporter.html)もあわせてDeployされます。GPU OperatorはHelmで簡単にインストールすることができます。
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia helm repo update helm install --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operator --set toolkit-version=1.15.0-ubi8 [root@master0 ~]# helm -n gpu-operator ls -a NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION gpu-operator-1715330617 gpu-operator 1 2024-05-10 17:43:38.337169199 +0900 JST deployed gpu-operator-v24.3.0 v24.3.0
[root@master0 ~]# kubectl -n gpu-operator get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES gpu-feature-discovery-f2m7x 1/1 Running 0 22h 192.168.155.215 gpu0 <none> <none> gpu-feature-discovery-rh9s6 1/1 Running 0 22h 192.168.5.195 gpu1 <none> <none> gpu-operator-1715330617-node-feature-discovery-gc-764864f6768vg 1/1 Running 4 (22h ago) 2d19h 192.168.155.207 gpu0 <none> <none> gpu-operator-1715330617-node-feature-discovery-master-5fffdcq9m 1/1 Running 0 2d19h 192.168.84.196 master0 <none> <none> gpu-operator-1715330617-node-feature-discovery-worker-f5tqt 1/1 Running 0 2d19h 192.168.84.198 master0 <none> <none> gpu-operator-1715330617-node-feature-discovery-worker-hxp5t 1/1 Running 4 (22h ago) 2d19h 192.168.155.208 gpu0 <none> <none> gpu-operator-1715330617-node-feature-discovery-worker-vn56f 1/1 Running 3 (22h ago) 2d19h 192.168.5.248 gpu1 <none> <none> gpu-operator-76587986b4-gvrtk 1/1 Running 0 2d19h 192.168.84.197 master0 <none> <none> nvidia-container-toolkit-daemonset-cnf2v 1/1 Running 0 22h 192.168.155.204 gpu0 <none> <none> nvidia-container-toolkit-daemonset-hd9vv 1/1 Running 0 22h 192.168.5.250 gpu1 <none> <none> nvidia-cuda-validator-mwptl 0/1 Completed 0 22h 192.168.5.253 gpu1 <none> <none> nvidia-cuda-validator-tx6dk 0/1 Completed 0 22h 192.168.155.197 gpu0 <none> <none> nvidia-dcgm-exporter-kvdsv 1/1 Running 0 22h 192.168.5.252 gpu1 <none> <none> nvidia-dcgm-exporter-xtf8n 1/1 Running 0 22h 192.168.155.195 gpu0 <none> <none> nvidia-device-plugin-daemonset-8mbln 1/1 Running 0 22h 192.168.5.255 gpu1 <none> <none> nvidia-device-plugin-daemonset-gk9fl 1/1 Running 0 22h 192.168.155.214 gpu0 <none> <none> nvidia-driver-daemonset-f6dhp 1/1 Running 4 (22h ago) 2d19h 192.168.155.205 gpu0 <none> <none> nvidia-driver-daemonset-glrtr 1/1 Running 3 (22h ago) 2d19h 192.168.5.247 gpu1 <none> <none> nvidia-mig-manager-2zqk6 1/1 Running 0 22h 192.168.5.254 gpu1 <none> <none> nvidia-mig-manager-9vh57 1/1 Running 0 22h 192.168.155.213 gpu0 <none> <none> nvidia-operator-validator-5bv82 1/1 Running 0 22h 192.168.155.193 gpu0 <none> <none> nvidia-operator-validator-svl8w 1/1 Running 0 22h 192.168.5.251 gpu1 <none> <none>
GPU OperatorのDeploy後、GPUが正しく認識されているか確認しておきます。
[root@master0 ~]# kubectl -n gpu-operator exec nvidia-driver-daemonset-f6dhp -- nvidia-smi Sun May 12 22:24:01 2024 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA A100 80GB PCIe On | 00000000:14:00.0 Off | Off | | N/A 37C P0 45W / 300W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+ [root@master0 ~]# kubectl -n gpu-operator exec nvidia-driver-daemonset-glrtr -- nvidia-smi Sun May 12 22:24:31 2024 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA A100 80GB PCIe On | 00000000:14:00.0 Off | 0 | | N/A 38C P0 47W / 300W | 0MiB / 81920MiB | 0% Default | | | | Disabled | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
モニタリングの準備
コードを実行している間のGPUの使用状況やRDMAのカウンタをPrometheus + Grafanaでモニタリングできるようにしておきます。GPUに関しては、上述のとおり、GPU OperatorがDCGM ExporterをDeployしてくれているので、これをそのまま使用すればよいです。GPUやVRAMの使用状況、温度、消費電力などを収集してくれます。RDMAのカウンタについては、以下のように各Podの/sys/class/infiniband/{device name}/ports/{port}/hw_countersにある各ファイルに記録されていますが、これを取得するための既成のコレクタを見つけることができませんでした。
root@gpu-pod0:/sys/class/infiniband/irdma0/ports/1/hw_counters# ls RxECNMrkd cnpIgnored ip4InMcastPkts ip4InTruncatedPkts ip4OutOctets ip6InMcastOctets ip6InReasmRqd ip6OutNoRoutes iwInRdmaReads iwOutRdmaSends lifespan tcpInSegs RxUDP cnpSent ip4InOctets ip4OutMcastOctets ip4OutPkts ip6InMcastPkts ip6InTruncatedPkts ip6OutOctets iwInRdmaSends iwOutRdmaWrites rxVlanErrors tcpOutSegs TxUDP ip4InDiscards ip4InPkts ip4OutMcastPkts ip4OutSegRqd ip6InOctets ip6OutMcastOctets ip6OutPkts iwInRdmaWrites iwRdmaBnd tcpInOptErrors tcpRetransSegs cnpHandled ip4InMcastOctets ip4InReasmRqd ip4OutNoRoutes ip6InDiscards ip6InPkts ip6OutMcastPkts ip6OutSegRqd iwOutRdmaReads iwRdmaInv tcpInProtoErrors root@gpu-pod0:/sys/class/infiniband/irdma0/ports/1/hw_counters# ls *Rdma* iwInRdmaReads iwInRdmaSends iwInRdmaWrites iwOutRdmaReads iwOutRdmaSends iwOutRdmaWrites iwRdmaBnd iwRdmaInv root@gpu-pod0:/sys/class/infiniband/irdma0/ports/1/hw_counters# for t in $(ls *Rdma*); do echo -n "$t: "; cat $t; done iwInRdmaReads: 23 iwInRdmaSends: 240 iwInRdmaWrites: 141075419 iwOutRdmaReads: 6 iwOutRdmaSends: 235 iwOutRdmaWrites: 137113821 iwRdmaBnd: 0 iwRdmaInv: 0
そこで今回は、以下のようなExporterを作って、GPU Podで実行することにしました。
package main
import (
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
"io"
"log"
"net/http"
"os"
"path/filepath"
"strconv"
"strings"
"time"
)
var (
defaultInterval = 10 * time.Second
iwInRdmaWrites = prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Name: "iwInRdmaWrites",
Help: "iwInRdmaWrites",
}, []string{"device", "port"})
iwOutRdmaWrites = prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Name: "iwOutRdmaWrites",
Help: "iwOutRdmaWrites",
}, []string{"device", "port"})
iwInRdmaReads = prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Name: "iwInRdmaReads",
Help: "iwInRdmaReads",
}, []string{"device", "port"})
iwOutRdmaReads = prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Name: "iwOutRdmaReads",
Help: "iwOutRdmaReads",
}, []string{"device", "port"})
iwInRdmaSends = prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Name: "iwInRdmaSends",
Help: "iwInRdmaSends",
}, []string{"device", "port"})
iwOutRdmaSends = prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Name: "iwOutRdmaSends",
Help: "iwOutRdmaSends",
}, []string{"device", "port"})
iwRdmaBnd = prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Name: "iwRdmaBnd",
Help: "iwRdmaBnd",
}, []string{"device", "port"})
iwRdmaInv = prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Name: "iwRdmaInv",
Help: "iwRdmaInv",
}, []string{"device", "port"})
mapping = map[string]*prometheus.GaugeVec{
"iwInRdmaReads": iwInRdmaReads,
"iwInRdmaWrites": iwInRdmaWrites,
"iwOutRdmaReads": iwOutRdmaReads,
"iwOutRdmaWrites": iwOutRdmaWrites,
"iwInRdmaSends": iwInRdmaSends,
"iwOutRdmaSends": iwOutRdmaSends,
"iwRdmaBnd": iwRdmaBnd,
"iwRdmaInv": iwRdmaInv,
}
)
func collectMetrics() {
go func() {
for {
files, err := filepath.Glob("/sys/class/infiniband/irdma0/ports/1/hw_counters/*Rdma*")
if err != nil {
log.Fatal(err)
}
for _, file := range files {
f, err := os.Open(file)
if err != nil {
log.Printf("failed to open %s, err: %v\n", file, err)
continue
}
contents, err := io.ReadAll(f)
f.Close()
if err != nil {
log.Printf("failed to read %s, err: %v\n", file, err)
continue
}
metricValue, err := strconv.ParseFloat(
strings.TrimSuffix(string(contents), "\n"), 64)
if err != nil {
log.Printf("failed to parse contents(%s), err: %v\n", contents, err)
continue
}
metricName := filepath.Base(file)
log.Printf("current %s value: %f\n", metricName, metricValue)
mapping[metricName].WithLabelValues("irdma0", "1").Set(metricValue)
}
time.Sleep(defaultInterval)
}
}()
}
func main() {
http.Handle("/metrics", promhttp.Handler())
for _, v := range mapping {
prometheus.MustRegister(v)
}
collectMetrics()
if err := http.ListenAndServe(":8000", nil); err != nil {
log.Fatalf("failed to start http server, err: %v", err)
return
}
}
ネットワーク機器もその通信量を把握するため、gNMI(https://gnmic.openconfig.net/)によるデータ収集を行っています。
コンテナイメージの作成
マルチGPUノード間の通信を発生させるためのツールやコードを実行するためのコンテナイメージを作成します。ベースイメージにはNVIDIA社が公開しているPyTorchのコンテナイメージ(https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch)を使用し、今回の検証に必要なパッケージをインストールしておきます。また、nccl-testsというNCCL(※1)によるGPU間通信の性能を評価するためのベンチマークツールもビルドしておきます。
※1. NCCL= NVIDIA Collective Communication Library(https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/index.html)
FROM nvcr.io/nvidia/pytorch:23.09-py3
RUN apt-get update && \
apt-get install -y \
openssh-server \
rdma-core \
libibverbs1 \
libibverbs-dev \
librdmacm1 \
librdmacm-dev \
rdmacm-utils \
ibverbs-utils \
perftest \
iproute2 \
iputils-ping \
rdmacm-utils && \
apt-get clean && \
rm -rf /var/lib/apt/lists/* && \
git clone https://github.com/NVIDIA/nccl-tests.git && \
cd nccl-tests && \
make MPI=1 MPI_HOME=/usr/localCUDA_HOME_HOME=/usr/local/cuda NCCL_HOME=/usr/lib/x86_64-linux-gnu
openssh-serverをインストールしているのは後述のnccl-testsをマルチノードGPU環境で実行するために必要となるからです。
GPU Podの起動
GPU PodにはGPU, NIC, RDMA Deviceをわりあてる必要があります。最初にhost-deviceとwhereaboutsを使用したNADを作成し、PodからE810 NICにアクセスできるようにしておきます。
apiVersion: "k8s.cni.cncf.io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: nic0
spec:
config: '{
"cniVersion": "0.3.0",
"type": "host-device",
"device": "ens192",
"ipam": {
"type": "whereabouts",
"range": "10.100.100.0/30"
}
}'
以下のPodを作成します。PodにはGPUと上記で作成したNICをわりあてています。また、いくつかのNCCLのパラメータを環境変数として渡しています。上述のRDMAカウンタを取得するためのExporterも実行しています。
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod0
labels:
app: gpuNode
annotations:
k8s.v1.cni.cncf.io/networks: nic0
spec:
containers:
- name: pytorch
workingDir: /mydir
securityContext:
privileged: true
image: pytorch-23.09-py3-custom
imagePullPolicy: IfNotPresent
command:
- "bash"
- "-c"
- "--"
args:
- "./rdma-monitor"
resources:
requests:
nvidia.com/gpu: 1
limits:
nvidia.com/gpu: 1
volumeMounts:
- mountPath: /mydir
name: mydir
env:
- name: MASTER_ADDR
value: "10.100.100.1"
- name: MASTER_PORT
value: "54321"
- name: NCCL_DEBUG
value: TRACE
- name: NCCL_SOCKET_IFNAME
value: net1
- name: NCCL_SOCKET_FAMILY
value: AF_INET
volumes:
- name: mydir
hostPath:
path: /root/script
type: Directory
これでPodが起動し、GPUとNICはPodからアクセスできるようになっていますが、RDMA Deviceは依然Host OS側のNetwork namespaceに存在しているため、Podからはみえません。NVIDIAのNICであれば、NVIDIA Network Operatorが全てよしなにやってくれるのでしょうが、今回の環境はIntel NICを使っています。私の調査不足の可能性はありますが、Intel NICに関するOperatorなどの実装は見つかりませんでした。どうするか迷いましたが、今回は手動で対応することにしました。
root@gpu-pod0:/mydir# ip -o a 1: lo inet 127.0.0.1/8 scope host lo\ valid_lft forever preferred_lft forever 1: lo inet6 ::1/128 scope host \ valid_lft forever preferred_lft forever 3: net1 inet 10.100.100.1/29 brd 10.100.100.7 scope global net1\ valid_lft forever preferred_lft forever 3: net1 inet6 fe80::b696:91ff:feec:a458/64 scope link \ valid_lft forever preferred_lft forever 4: eth0 inet 192.168.155.224/32 scope global eth0\ valid_lft forever preferred_lft forever 4: eth0 inet6 fe80::d046:e9ff:fe23:ec11/64 scope link \ valid_lft forever preferred_lft forever root@gpu-pod0:/mydir# ibv_devinfo -v No IB devices found
以下はRDMA DeviceのNetwork Namespaceの変更に関するドキュメントの記述です。
rdma system show - display RDMA subsystem network namespace mode and privileged qkey state
NEWMODE - specifies the RDMA subsystem mode. Either exclusive or
shared. When user wants to assign dedicated RDMA device to a
particular network namespace, exclusive mode should be set before
creating any network namespace. If there are active network
namespaces and if one or more RDMA devices exist, changing mode
from shared to exclusive returns error code EBUSY.
When RDMA subsystem is in shared mode, RDMA device is accessible
in all network namespace. When RDMA device isolation among
multiple network namespaces is not needed, shared mode can be
used.
It is preferred to not change the subsystem mode when there is
active RDMA traffic running, even though it is supported.
上述の内容にしたがい、Podを一度削除し、exclusive modeへ変更します。
//モード変更前 [root@gpu0 ~]# rdma system show netns shared copy-on-fork on echo "options ib_core netns_mode=0" >> /etc/modprobe.d/ib_core.conf reboot //モード変更後 [root@gpu0 ~]# rdma system show netns exclusive copy-on-fork on
正常にexclusive modeに変更されたため、再度Podを起動したうえで、RDMA DeviceをPodのnetwork namespaceへ移動させます。
[root@gpu0 ~]# containerid=$(nerdctl -n k8s.io container ls | grep pytorch | awk '{print $1}')
[root@gpu0 ~]# echo $containerid
75208fa4379f
[root@gpu0 ~]# pid=$(nerdctl -n k8s.io container inspect ${containerid} --format '{{.State.Pid}}')
[root@gpu0 ~]# ls /proc/${pid}/ns
cgroup ipc mnt net pid pid_for_children time time_for_children user uts
[root@gpu0 ~]# ln -s /proc/${pid}/ns/net /var/run/netns/gpu-test
[root@gpu0 ~]# rdma dev set irdma0 netns gpu-test
これでアプリケーションを実行するコンテナからdeviceがみえるようになりました。
[root@master0 pod]# kubectl exec -ti gpu-pod0 -- bash
root@gpu-pod0:/mydir# ibv_devinfo -v
hca_id: irdma0
transport: InfiniBand (0)
fw_ver: 1.53
node_guid: b696:91ff:feec:a458
sys_image_guid: b696:91ff:feec:a458
vendor_id: 0x8086
vendor_part_id: 5531
hw_ver: 0x2
phys_port_cnt: 1
max_mr_size: 0x200000000000
page_size_cap: 0x40201000
max_qp: 131069
max_qp_wr: 4063
device_cap_flags: 0x00221000
RC_RNR_NAK_GEN
MEM_WINDOW
MEM_MGT_EXTENSIONS
max_sge: 13
max_sge_rd: 13
max_cq: 262141
max_cqe: 1048574
max_mr: 2097150
max_pd: 262141
max_qp_rd_atom: 127
max_ee_rd_atom: 0
max_res_rd_atom: 0
max_qp_init_rd_atom: 255
max_ee_init_rd_atom: 0
atomic_cap: ATOMIC_NONE (0)
max_ee: 0
max_rdd: 0
max_mw: 2097150
max_raw_ipv6_qp: 0
max_raw_ethy_qp: 0
max_mcast_grp: 131072
max_mcast_qp_attach: 8
max_total_mcast_qp_attach: 1048576
max_ah: 131072
max_fmr: 0
max_srq: 0
max_pkeys: 1
local_ca_ack_delay: 0
general_odp_caps:
rc_odp_caps:
NO SUPPORT
uc_odp_caps:
NO SUPPORT
ud_odp_caps:
NO SUPPORT
xrc_odp_caps:
NO SUPPORT
completion timestamp_mask: 0x000000000001ffff
core clock not supported
device_cap_flags_ex: 0x221000
tso_caps:
max_tso: 0
rss_caps:
max_rwq_indirection_tables: 0
max_rwq_indirection_table_size: 0
rx_hash_function: 0x0
rx_hash_fields_mask: 0x0
max_wq_type_rq: 0
packet_pacing_caps:
qp_rate_limit_min: 0kbps
qp_rate_limit_max: 0kbps
tag matching not supported
num_comp_vectors: 8
port: 1
state: PORT_ACTIVE (4)
max_mtu: 4096 (5)
active_mtu: 1024 (3)
sm_lid: 0
port_lid: 1
port_lmc: 0x00
link_layer: Ethernet
max_msg_sz: 0x7fffffff
port_cap_flags: 0x04050000
port_cap_flags2: 0x0000
max_vl_num: invalid value (0)
bad_pkey_cntr: 0x0
qkey_viol_cntr: 0x0
sm_sl: 0
pkey_tbl_len: 1
gid_tbl_len: 32
subnet_timeout: 0
init_type_reply: 0
active_width: 4X (2)
active_speed: 25.0 Gbps (32)
phys_state: LINK_UP (5)
GID[ 0]: fe80::b696:91ff:feec:a458, RoCE v2
GID[ 1]: ::ffff:10.100.100.1, RoCE v2
rpingとperftest packageに含まれているベンチマークツールを使用して、セットアップしたRDMAネットワークが正しく動作しているか確認します。
- rping
//サーバ側 root@gpu-pod0:/workspace/nccl-tests# rping -sdvVa 10.100.100.1 verbose validate data created cm_id 0x55c34c61b270 rdma_bind_addr successful rdma_listen cma_event type RDMA_CM_EVENT_CONNECT_REQUEST cma_id 0x7f292c000ce0 (child) child cma 0x7f292c000ce0 created pd 0x55c34c614780 created channel 0x55c34c6120e0 created cq 0x55c34c61bb60 created qp 0x55c34c61d400 rping_setup_buffers called on cb 0x55c34c60f830 allocated & registered buffers... accepting client connection request cq_thread started. cma_event type RDMA_CM_EVENT_ESTABLISHED cma_id 0x7f292c000ce0 (child) ESTABLISHED recv completion Received rkey 3fb84b15 addr 558db36de0f0 len 64 from peer server received sink adv server posted rdma read req rdma read completion server received read complete server ping data: rdma-ping-0: ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqr server posted go ahead send completion recv completion Received rkey 8584c0f7 addr 558db36d9fb0 len 64 from peer server received sink adv rdma write from lkey ec9d1456 laddr 55c34c61d770 len 64 rdma write completion server rdma write complete server posted go ahead send completion recv completion Received rkey 3fb84b15 addr 558db36de0f0 len 64 from peer server received sink adv server posted rdma read req rdma read completion server received read complete server ping data: rdma-ping-1: BCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrs server posted go ahead send completion recv completion Received rkey 8584c0f7 addr 558db36d9fb0 len 64 from peer server received sink adv rdma write from lkey ec9d1456 laddr 55c34c61d770 len 64 rdma write completion server rdma write complete server posted go ahead send completion recv completion Received rkey 3fb84b15 addr 558db36de0f0 len 64 from peer server received sink adv server posted rdma read req rdma read completion server received read complete server ping data: rdma-ping-2: CDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrst server posted go ahead send completion recv completion Received rkey 8584c0f7 addr 558db36d9fb0 len 64 from peer server received sink adv rdma write from lkey ec9d1456 laddr 55c34c61d770 len 64 rdma write completion server rdma write complete server posted go ahead send completion cma_event type RDMA_CM_EVENT_DISCONNECTED cma_id 0x7f292c000ce0 (child) server DISCONNECT EVENT... wait for RDMA_READ_ADV state 10 rping_free_buffers called on cb 0x55c34c60f830 destroy cm_id 0x55c34c61b270 //クライアント側 root@gpu-pod1:/workspace/nccl-tests# rping -cdvVa 10.100.100.1 -C 3 verbose validate data count 3 created cm_id 0x558db36d9270 cma_event type RDMA_CM_EVENT_ADDR_RESOLVED cma_id 0x558db36d9270 (parent) cma_event type RDMA_CM_EVENT_ROUTE_RESOLVED cma_id 0x558db36d9270 (parent) rdma_resolve_addr - rdma_resolve_route successful created pd 0x558db36d4aa0 created channel 0x558db36d00c0 created cq 0x558db36d9600 created qp 0x558db36d9c00 rping_setup_buffers called on cb 0x558db36cd830 allocated & registered buffers... cq_thread started. cma_event type RDMA_CM_EVENT_ESTABLISHED cma_id 0x558db36d9270 (parent) ESTABLISHED rdma_connect successful RDMA addr 558db36de0f0 rkey 3fb84b15 len 64 send completion recv completion RDMA addr 558db36d9fb0 rkey 8584c0f7 len 64 send completion recv completion ping data: rdma-ping-0: ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqr RDMA addr 558db36de0f0 rkey 3fb84b15 len 64 send completion recv completion RDMA addr 558db36d9fb0 rkey 8584c0f7 len 64 send completion recv completion ping data: rdma-ping-1: BCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrs RDMA addr 558db36de0f0 rkey 3fb84b15 len 64 send completion recv completion RDMA addr 558db36d9fb0 rkey 8584c0f7 len 64 send completion recv completion ping data: rdma-ping-2: CDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrst rping_free_buffers called on cb 0x558db36cd830 destroy cm_id 0x558db36d9270
- ib_write_bw
//サーバ側
root@gpu-pod0:/workspace/nccl-tests# ib_write_bw --report_gbits --report-both -D60 -F -R
************************************
* Waiting for client to connect... *
************************************
---------------------------------------------------------------------------------------
RDMA_Write BW Test
Dual-port : OFF Device : irdma0
Number of qps : 1 Transport type : IB
Connection type : RC Using SRQ : OFF
PCIe relax order: ON
ibv_wr* API : OFF
CQ Moderation : 1
Mtu : 1024[B]
Link type : Ethernet
GID index : 1
Max inline data : 0[B]
rdma_cm QPs : ON
Data ex. method : rdma_cm
---------------------------------------------------------------------------------------
Waiting for client rdma_cm QP to connect
Please run the same command with the IB/RoCE interface IP
---------------------------------------------------------------------------------------
local address: LID 0x01 QPN 0x00c3 PSN 0x7f64d6
GID: 00:00:00:00:00:00:00:00:00:00:255:255:10:100:100:01
remote address: LID 0x01 QPN 0x00c3 PSN 0x19cf42
GID: 00:00:00:00:00:00:00:00:00:00:255:255:10:100:100:02
---------------------------------------------------------------------------------------
#bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps]
65536 1324156 0.00 23.14 0.044138
---------------------------------------------------------------------------------------
//クライアント側
root@gpu-pod1:/workspace/nccl-tests# ib_write_bw --report_gbits --report-both -D60 -F -R 10.100.100.1
---------------------------------------------------------------------------------------
RDMA_Write BW Test
Dual-port : OFF Device : irdma0
Number of qps : 1 Transport type : IB
Connection type : RC Using SRQ : OFF
PCIe relax order: ON
ibv_wr* API : OFF
TX depth : 128
CQ Moderation : 1
Mtu : 1024[B]
Link type : Ethernet
GID index : 1
Max inline data : 0[B]
rdma_cm QPs : ON
Data ex. method : rdma_cm
---------------------------------------------------------------------------------------
local address: LID 0x01 QPN 0x00c3 PSN 0x19cf42
GID: 00:00:00:00:00:00:00:00:00:00:255:255:10:100:100:02
remote address: LID 0x01 QPN 0x00c3 PSN 0x7f64d6
GID: 00:00:00:00:00:00:00:00:00:00:255:255:10:100:100:01
---------------------------------------------------------------------------------------
#bytes #iterations BW peak[Gb/sec] BW average[Gb/sec] MsgRate[Mpps]
65536 1324156 0.00 23.14 0.044138
---------------------------------------------------------------------------------------
以下は上記のベンチマークツールを実行しているときのRDMAのグラフです。Exporterも正常に動作しているようです。
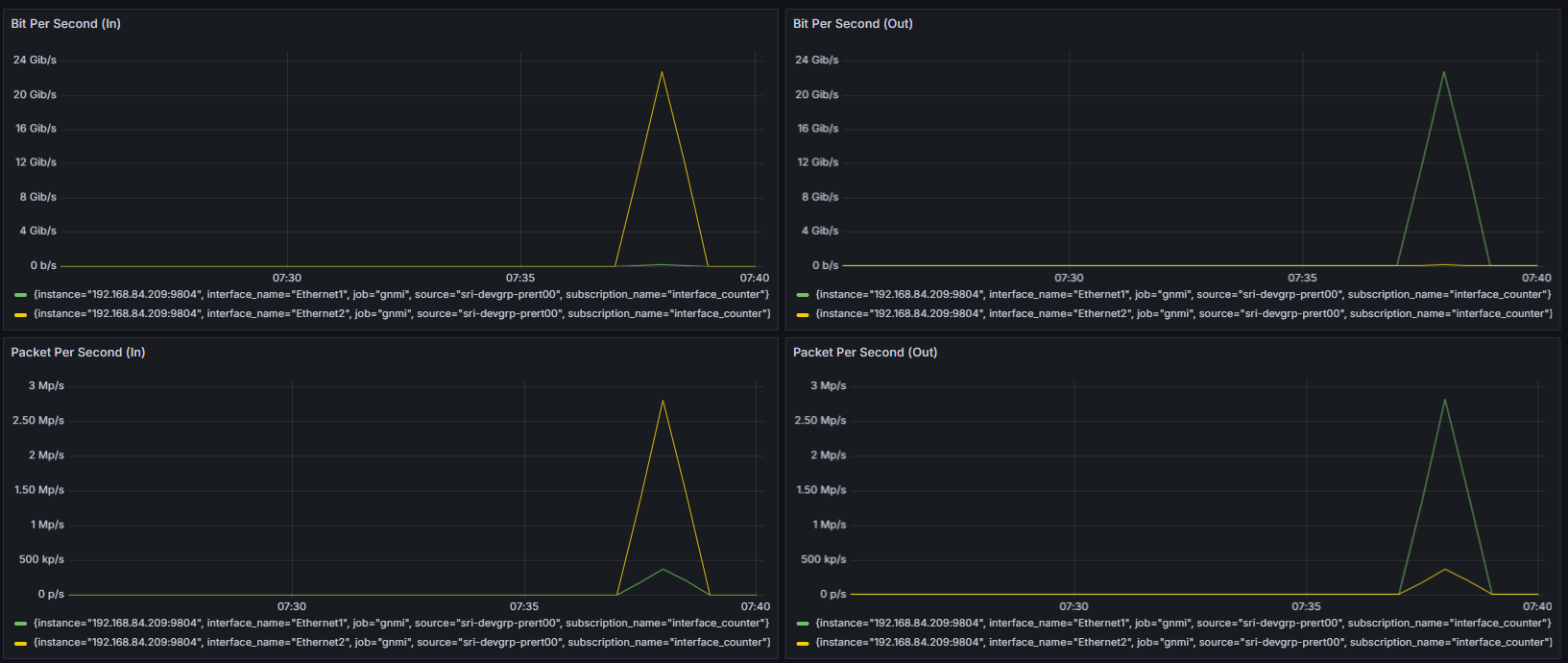
同じくスイッチ側のTraffic量です。
最後にbuildしておいたnccl-testsを使って、NCCLを使用したGPU – GPU間の通信性能を確認しておきます。なお、下記のログ上は省略しておりますが、mpirunコマンドを実行する前提として、コマンドを実行しているPodからそれ以外のPodに対して、SSHができる必要があります。
root@gpu-pod0:/workspace/nccl-tests/build# ls all_gather_perf all_reduce_perf alltoall_perf broadcast_perf gather_perf hypercube_perf reduce_perf reduce_scatter_perf scatter_perf sendrecv_perf timer.o verifiable root@gpu-pod0:/workspace/nccl-tests/build# mpirun --allow-run-as-root -H 10.100.100.1:1,10.100.100.2:1 ./all_reduce_perf -b 10GB -e 10GB -g 1 [1715554417.351542] [gpu-pod1:51731:0] rc_iface.c:513 UCX ERROR ibv_create_srq() failed: Operation not supported [gpu-pod1:51731] pml_ucx.c:309 Error: Failed to create UCP worker [1715554417.882585] [gpu-pod0:52047:0] rc_iface.c:513 UCX ERROR ibv_create_srq() failed: Operation not supported [gpu-pod0:52047] pml_ucx.c:309 Error: Failed to create UCP worker # nThread 1 nGpus 1 minBytes 10737418240 maxBytes 10737418240 step: 1048576(bytes) warmup iters: 5 iters: 20 agg iters: 1 validation: 1 graph: 0 # # Using devices # Rank 0 Group 0 Pid 52047 on gpu-pod0 device 0 [0x14] NVIDIA A100 80GB PCIe # Rank 1 Group 0 Pid 51731 on gpu-pod1 device 0 [0x14] NVIDIA A100 80GB PCIe gpu-pod0:52047:52047 [0] NCCL INFO NCCL_SOCKET_FAMILY set by environment to AF_INET gpu-pod0:52047:52047 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to net1 gpu-pod0:52047:52047 [0] NCCL INFO Bootstrap : Using net1:10.100.100.1<0> gpu-pod0:52047:52047 [0] NCCL INFO cudaDriverVersion 12040 NCCL version 2.18.5+cuda12.2 gpu-pod0:52047:52056 [0] NCCL INFO Plugin Path : /opt/hpcx/nccl_rdma_sharp_plugin/lib/libnccl-net.so gpu-pod0:52047:52056 [0] NCCL INFO P2P plugin IBext gpu-pod0:52047:52056 [0] NCCL INFO NCCL_SOCKET_FAMILY set by environment to AF_INET gpu-pod0:52047:52056 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to net1 gpu-pod0:52047:52056 [0] NCCL INFO NET/IB : Using [0]irdma0:1/RoCE [RO]; OOB net1:10.100.100.1<0> gpu-pod0:52047:52056 [0] NCCL INFO Using network IBext gpu-pod0:52047:52056 [0] NCCL INFO comm 0x564b10cb5ca0 rank 0 nranks 2 cudaDev 0 nvmlDev 0 busId 14000 commId 0xd304be7ee9fbd4fb - Init START gpu-pod0:52047:52056 [0] NCCL INFO Channel 00/02 : 0 1 gpu-pod0:52047:52056 [0] NCCL INFO Channel 01/02 : 0 1 gpu-pod0:52047:52056 [0] NCCL INFO Trees [0] 1/-1/-1->0->-1 [1] -1/-1/-1->0->1 gpu-pod0:52047:52056 [0] NCCL INFO P2P Chunksize set to 131072 gpu-pod0:52047:52056 [0] NCCL INFO Channel 00/0 : 1[0] -> 0[0] [receive] via NET/IBext/0 gpu-pod0:52047:52056 [0] NCCL INFO Channel 01/0 : 1[0] -> 0[0] [receive] via NET/IBext/0 gpu-pod0:52047:52056 [0] NCCL INFO Channel 00/0 : 0[0] -> 1[0] [send] via NET/IBext/0 gpu-pod0:52047:52056 [0] NCCL INFO Channel 01/0 : 0[0] -> 1[0] [send] via NET/IBext/0 gpu-pod0:52047:52056 [0] NCCL INFO Connected all rings gpu-pod0:52047:52056 [0] NCCL INFO Connected all trees gpu-pod0:52047:52056 [0] NCCL INFO threadThresholds 8/8/64 | 16/8/64 | 512 | 512 gpu-pod0:52047:52056 [0] NCCL INFO 2 coll channels, 0 nvls channels, 2 p2p channels, 2 p2p channels per peer gpu-pod0:52047:52056 [0] NCCL INFO comm 0x564b10cb5ca0 rank 0 nranks 2 cudaDev 0 nvmlDev 0 busId 14000 commId 0xd304be7ee9fbd4fb - Init COMPLETE # # out-of-place in-place # size count type redop root time algbw busbw #wrong time algbw busbw #wrong # (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s) 10737418240 2684354560 float sum -1 3825027 2.81 2.81 0 3825795 2.81 2.81 0 gpu-pod0:52047:52047 [0] NCCL INFO comm 0x564b10cb5ca0 rank 0 nranks 2 cudaDev 0 busId 14000 - Destroy COMPLETE # Out of bounds values : 0 OK # Avg bus bandwidth : 2.80687 #
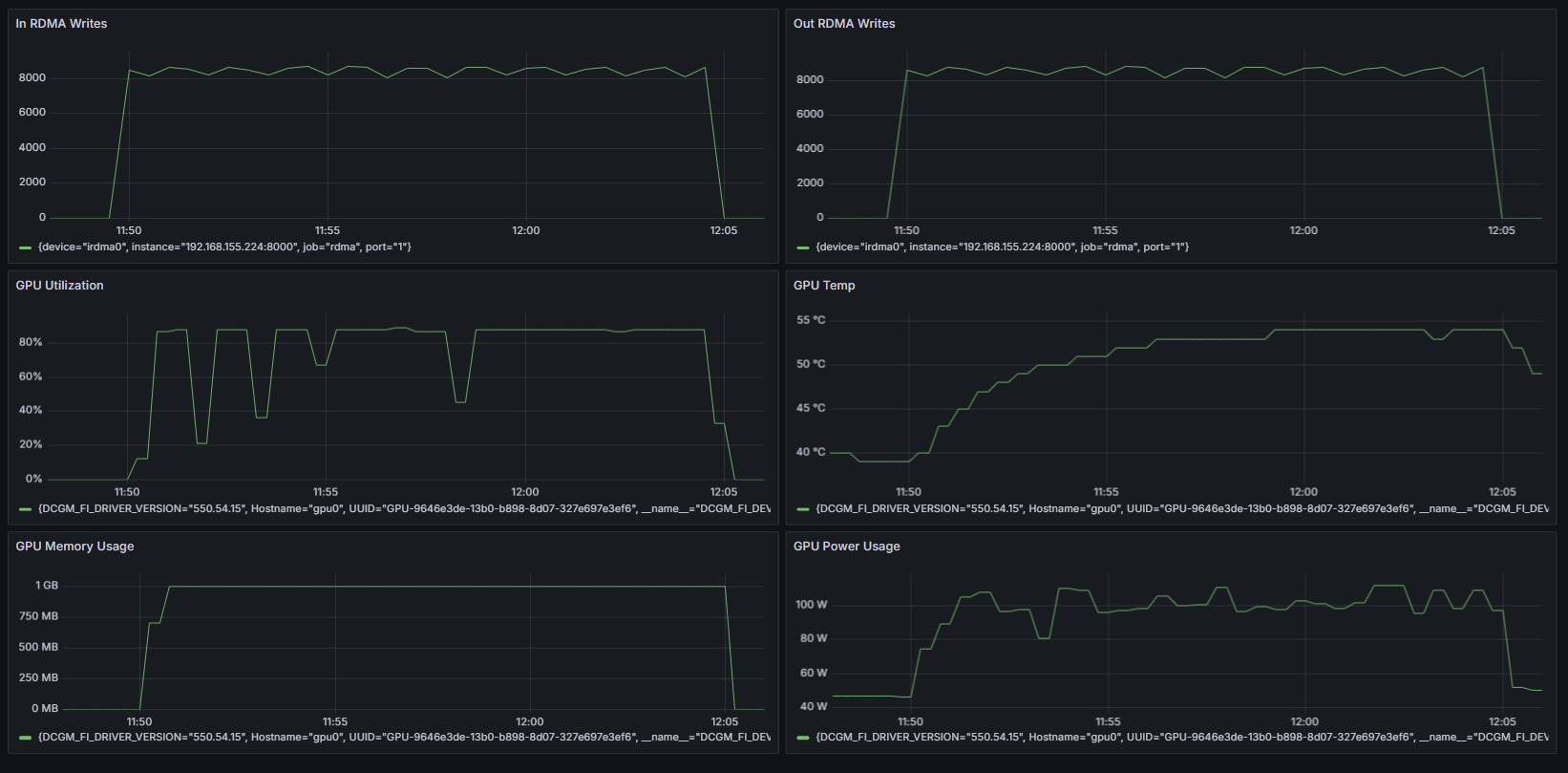
nccl-testsを実行しているときのGPU、RDMAのグラフです。正しく負荷をかけられているようです。

スイッチ側のTraffic量は以下のとおりです。

ここまでにセットアップした環境は正常に動作しているようです。
Deep Learningコードの実行
最後に今回のゴールである画像分類を行うコードを書いて、この環境で実行してみます。10クラスの乗り物や動物の画像が含まれたデータセット(CIFAR10)と、学習済みのモデル(ResNet-18)を使います。
import argparse
import logging
import os
import random
import sys
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torch.nn.parallel import DistributedDataParallel
from torch.utils.data import DataLoader
from torch.utils.data.distributed import DistributedSampler
from torchvision.datasets import CIFAR10
from torchvision.models import resnet18, ResNet18_Weights
logger = logging.getLogger(__name__)
def setup_logging(debug):
log_format = ('%(levelname) -10s %(asctime)s %(name) -30s %(funcName) '
'-35s %(lineno) -5d: %(message)s')
level = logging.INFO
if debug:
level = logging.DEBUG
logging.basicConfig(level=level, format=log_format)
def set_random_seeds(random_seed):
torch.manual_seed(random_seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(random_seed)
random.seed(random_seed)
def test(model, device, test_loader):
model.eval()
correct, total = 0, 0
with torch.no_grad():
for data in test_loader:
images, labels = data[0].to(device), data[1].to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
return accuracy
def train(model, device, training_loader, optimizer):
model.train()
criterion = nn.CrossEntropyLoss()
for data in training_loader:
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
def parse_args(args):
parser = argparse.ArgumentParser(description="")
parser.add_argument("--epochs",
type=int,
default=10)
parser.add_argument("--batch_size",
type=int,
default=128)
parser.add_argument("--learning_rate",
type=float,
default=0.1)
parser.add_argument("--random_seed",
type=int,
default=0)
parser.add_argument("--debug",
action="store_true")
parser.add_argument("--pre-trained",
action="store_true")
return parser.parse_args(args)
def main():
if not torch.cuda.is_available():
logger.info("\n\n**No cuda device found**\n\n")
return
args = parse_args(sys.argv[1:])
local_rank = 0
setup_logging(args.debug)
set_random_seeds(random_seed=args.random_seed)
torch.distributed.init_process_group(backend="nccl")
transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
training_data_set = CIFAR10(root="./data",
train=True,
download=False,
transform=transform)
logger.info(f"Class of dataset: {training_data_set.classes}")
logger.info(f"The number of training dataset: {len(training_data_set)}")
training_sampler = DistributedSampler(dataset=training_data_set)
test_data_set = CIFAR10(root="./data",
train=False,
download=False,
transform=transform)
logger.info(f"The number of test dataset: {len(test_data_set)}")
training_loader = DataLoader(dataset=training_data_set,
batch_size=args.batch_size,
num_workers=os.cpu_count(),
pin_memory=True,
sampler=training_sampler)
test_loader = DataLoader(dataset=test_data_set,
batch_size=args.batch_size,
num_workers=os.cpu_count(),
pin_memory=True,
shuffle=False)
weights = None
if args.pre_trained:
weights = ResNet18_Weights.DEFAULT
model = resnet18(weights=weights)
model.fc = nn.Linear(model.fc.in_features, len(test_data_set.classes))
device = torch.device(f"cuda:{local_rank}")
model = model.to(device)
dist_model = DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)
optimizer = optim.SGD(model.parameters(),
lr=args.learning_rate,
momentum=0.9,
weight_decay=1e-5)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=200)
for epoch in range(1, args.epochs + 1):
logger.info(f"Start Epoch {epoch}")
train(model=dist_model,
device=device,
training_loader=training_loader,
optimizer=optimizer)
if epoch % 10 == 0:
accuracy = test(
model=dist_model,
device=device,
test_loader=test_loader)
logger.info(f"Epoch: {epoch}, Accuracy: {accuracy}")
scheduler.step()
if __name__ == "__main__":
main()
//gpu-pod0 root@gpu-pod0:/mydir# torchrun --nproc_per_node=1 --nnodes=2 --node_rank=0 --master_addr="10.100.100.1" --master_port=54321 2.py --epochs 200 --batch_size 128 --learning_rate 0.01 --pre-trained INFO 2024-05-14 02:49:30,831 __main__ main 115 : Class of dataset: ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] INFO 2024-05-14 02:49:30,831 __main__ main 116 : The number of training dataset: 50000 INFO 2024-05-14 02:49:31,143 __main__ main 125 : The number of test dataset: 10000 gpu-pod0:18999:18999 [0] NCCL INFO NCCL_SOCKET_FAMILY set by environment to AF_INET gpu-pod0:18999:18999 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to net1 gpu-pod0:18999:18999 [0] NCCL INFO Bootstrap : Using net1:10.100.100.1<0> gpu-pod0:18999:18999 [0] NCCL INFO cudaDriverVersion 12040 NCCL version 2.18.5+cuda12.2 gpu-pod0:18999:19026 [0] NCCL INFO Plugin Path : /opt/hpcx/nccl_rdma_sharp_plugin/lib/libnccl-net.so gpu-pod0:18999:19026 [0] NCCL INFO P2P plugin IBext gpu-pod0:18999:19026 [0] NCCL INFO NCCL_SOCKET_FAMILY set by environment to AF_INET gpu-pod0:18999:19026 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to net1 gpu-pod0:18999:19026 [0] NCCL INFO NET/IB : Using [0]irdma0:1/RoCE [RO]; OOB net1:10.100.100.1<0> gpu-pod0:18999:19026 [0] NCCL INFO Using network IBext gpu-pod0:18999:19026 [0] NCCL INFO comm 0x55f6bc9e0030 rank 0 nranks 2 cudaDev 0 nvmlDev 0 busId 14000 commId 0x3a288a96e7f2c04e - Init START gpu-pod0:18999:19026 [0] NCCL INFO Channel 00/02 : 0 1 gpu-pod0:18999:19026 [0] NCCL INFO Channel 01/02 : 0 1 gpu-pod0:18999:19026 [0] NCCL INFO Trees [0] 1/-1/-1->0->-1 [1] -1/-1/-1->0->1 gpu-pod0:18999:19026 [0] NCCL INFO P2P Chunksize set to 131072 gpu-pod0:18999:19026 [0] NCCL INFO Channel 00/0 : 1[0] -> 0[0] [receive] via NET/IBext/0 gpu-pod0:18999:19026 [0] NCCL INFO Channel 01/0 : 1[0] -> 0[0] [receive] via NET/IBext/0 gpu-pod0:18999:19026 [0] NCCL INFO Channel 00/0 : 0[0] -> 1[0] [send] via NET/IBext/0 gpu-pod0:18999:19026 [0] NCCL INFO Channel 01/0 : 0[0] -> 1[0] [send] via NET/IBext/0 gpu-pod0:18999:19026 [0] NCCL INFO Connected all rings gpu-pod0:18999:19026 [0] NCCL INFO Connected all trees gpu-pod0:18999:19026 [0] NCCL INFO threadThresholds 8/8/64 | 16/8/64 | 512 | 512 gpu-pod0:18999:19026 [0] NCCL INFO 2 coll channels, 0 nvls channels, 2 p2p channels, 2 p2p channels per peer gpu-pod0:18999:19026 [0] NCCL INFO comm 0x55f6bc9e0030 rank 0 nranks 2 cudaDev 0 nvmlDev 0 busId 14000 commId 0x3a288a96e7f2c04e - Init COMPLETE INFO 2024-05-14 02:49:31,643 __main__ main 158 : Start Epoch 1 INFO 2024-05-14 02:49:36,462 __main__ main 158 : Start Epoch 2 INFO 2024-05-14 02:49:40,914 __main__ main 158 : Start Epoch 3 INFO 2024-05-14 02:49:45,388 __main__ main 158 : Start Epoch 4 INFO 2024-05-14 02:49:49,812 __main__ main 158 : Start Epoch 5 INFO 2024-05-14 02:49:54,254 __main__ main 158 : Start Epoch 6 INFO 2024-05-14 02:49:58,685 __main__ main 158 : Start Epoch 7 INFO 2024-05-14 02:50:03,136 __main__ main 158 : Start Epoch 8 INFO 2024-05-14 02:50:07,553 __main__ main 158 : Start Epoch 9 INFO 2024-05-14 02:50:11,996 __main__ main 158 : Start Epoch 10 INFO 2024-05-14 02:50:16,988 __main__ main 170 : Epoch: 10, Accuracy: 0.8046 *snip* INFO 2024-05-14 03:03:43,614 __main__ main 158 : Start Epoch 191 INFO 2024-05-14 03:03:48,065 __main__ main 158 : Start Epoch 192 INFO 2024-05-14 03:03:52,504 __main__ main 158 : Start Epoch 193 INFO 2024-05-14 03:03:56,925 __main__ main 158 : Start Epoch 194 INFO 2024-05-14 03:04:01,354 __main__ main 158 : Start Epoch 195 INFO 2024-05-14 03:04:05,772 __main__ main 158 : Start Epoch 196 INFO 2024-05-14 03:04:10,187 __main__ main 158 : Start Epoch 197 INFO 2024-05-14 03:04:14,601 __main__ main 158 : Start Epoch 198 INFO 2024-05-14 03:04:19,002 __main__ main 158 : Start Epoch 199 INFO 2024-05-14 03:04:23,415 __main__ main 158 : Start Epoch 200 INFO 2024-05-14 03:04:28,352 __main__ main 170 : Epoch: 200, Accuracy: 0.856 //gpu-pod1 root@gpu-pod1:/mydir# torchrun --nproc_per_node=1 --nnodes=2 --node_rank=1 --master_addr="10.100.100.1" --master_port=54321 2.py --epochs 200 --batch_size 128 --learning_rate 0.01 --pre-trained INFO 2024-05-14 02:49:30,173 __main__ main 115 : Class of dataset: ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] INFO 2024-05-14 02:49:30,173 __main__ main 116 : The number of training dataset: 50000 INFO 2024-05-14 02:49:30,483 __main__ main 125 : The number of test dataset: 10000 gpu-pod1:18706:18706 [0] NCCL INFO cudaDriverVersion 12040 gpu-pod1:18706:18706 [0] NCCL INFO NCCL_SOCKET_FAMILY set by environment to AF_INET gpu-pod1:18706:18706 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to net1 gpu-pod1:18706:18706 [0] NCCL INFO Bootstrap : Using net1:10.100.100.2<0> gpu-pod1:18706:18732 [0] NCCL INFO Plugin Path : /opt/hpcx/nccl_rdma_sharp_plugin/lib/libnccl-net.so gpu-pod1:18706:18732 [0] NCCL INFO P2P plugin IBext gpu-pod1:18706:18732 [0] NCCL INFO NCCL_SOCKET_FAMILY set by environment to AF_INET gpu-pod1:18706:18732 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to net1 gpu-pod1:18706:18732 [0] NCCL INFO NET/IB : Using [0]irdma0:1/RoCE [RO]; OOB net1:10.100.100.2<0> gpu-pod1:18706:18732 [0] NCCL INFO Using network IBext gpu-pod1:18706:18732 [0] NCCL INFO comm 0x559aadac68a0 rank 1 nranks 2 cudaDev 0 nvmlDev 0 busId 14000 commId 0x3a288a96e7f2c04e - Init START gpu-pod1:18706:18732 [0] NCCL INFO Trees [0] -1/-1/-1->1->0 [1] 0/-1/-1->1->-1 gpu-pod1:18706:18732 [0] NCCL INFO P2P Chunksize set to 131072 gpu-pod1:18706:18732 [0] NCCL INFO Channel 00/0 : 0[0] -> 1[0] [receive] via NET/IBext/0 gpu-pod1:18706:18732 [0] NCCL INFO Channel 01/0 : 0[0] -> 1[0] [receive] via NET/IBext/0 gpu-pod1:18706:18732 [0] NCCL INFO Channel 00/0 : 1[0] -> 0[0] [send] via NET/IBext/0 gpu-pod1:18706:18732 [0] NCCL INFO Channel 01/0 : 1[0] -> 0[0] [send] via NET/IBext/0 gpu-pod1:18706:18732 [0] NCCL INFO Connected all rings gpu-pod1:18706:18732 [0] NCCL INFO Connected all trees gpu-pod1:18706:18732 [0] NCCL INFO threadThresholds 8/8/64 | 16/8/64 | 512 | 512 gpu-pod1:18706:18732 [0] NCCL INFO 2 coll channels, 0 nvls channels, 2 p2p channels, 2 p2p channels per peer gpu-pod1:18706:18732 [0] NCCL INFO comm 0x559aadac68a0 rank 1 nranks 2 cudaDev 0 nvmlDev 0 busId 14000 commId 0x3a288a96e7f2c04e - Init COMPLETE INFO 2024-05-14 02:49:31,051 __main__ main 158 : Start Epoch 1 INFO 2024-05-14 02:49:35,866 __main__ main 158 : Start Epoch 2 INFO 2024-05-14 02:49:40,322 __main__ main 158 : Start Epoch 3 INFO 2024-05-14 02:49:44,790 __main__ main 158 : Start Epoch 4 INFO 2024-05-14 02:49:49,219 __main__ main 158 : Start Epoch 5 INFO 2024-05-14 02:49:53,661 __main__ main 158 : Start Epoch 6 INFO 2024-05-14 02:49:58,091 __main__ main 158 : Start Epoch 7 INFO 2024-05-14 02:50:02,542 __main__ main 158 : Start Epoch 8 INFO 2024-05-14 02:50:06,960 __main__ main 158 : Start Epoch 9 INFO 2024-05-14 02:50:11,403 __main__ main 158 : Start Epoch 10 INFO 2024-05-14 02:50:16,394 __main__ main 170 : Epoch: 10, Accuracy: 0.8046 *snip* INFO 2024-05-14 03:03:42,975 __main__ main 158 : Start Epoch 191 INFO 2024-05-14 03:03:47,472 __main__ main 158 : Start Epoch 192 INFO 2024-05-14 03:03:51,908 __main__ main 158 : Start Epoch 193 INFO 2024-05-14 03:03:56,331 __main__ main 158 : Start Epoch 194 INFO 2024-05-14 03:04:00,760 __main__ main 158 : Start Epoch 195 INFO 2024-05-14 03:04:05,178 __main__ main 158 : Start Epoch 196 INFO 2024-05-14 03:04:09,594 __main__ main 158 : Start Epoch 197 INFO 2024-05-14 03:04:14,006 __main__ main 158 : Start Epoch 198 INFO 2024-05-14 03:04:18,407 __main__ main 158 : Start Epoch 199 INFO 2024-05-14 03:04:22,822 __main__ main 158 : Start Epoch 200 INFO 2024-05-14 03:04:27,748 __main__ main 170 : Epoch: 200, Accuracy: 0.856
上記のコードを実行しているときのグラフです。
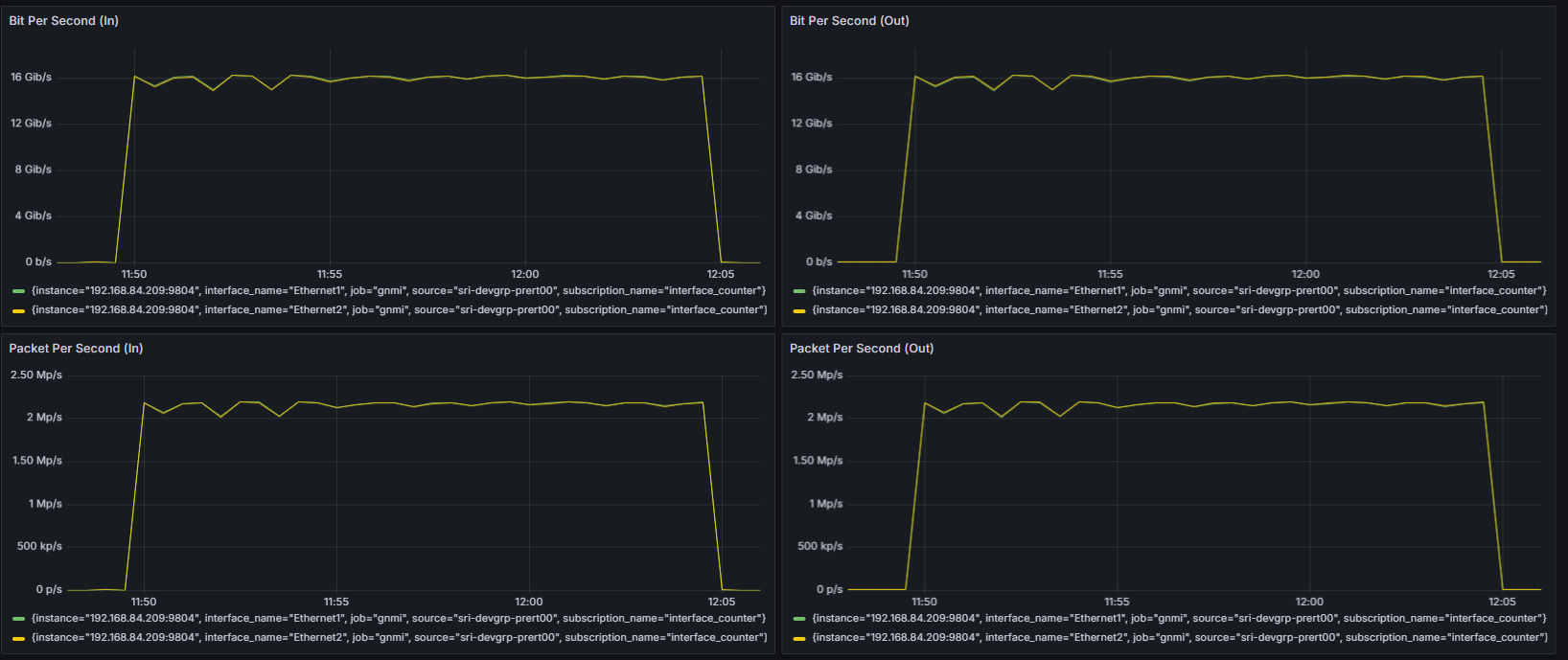
当初の予定通り、Ethernet/RDMAをつかった2つのGPU Podによる学習ができました。
まとめ
今回、GPU、RDMA、NCCL、Deep Learningといった知識がほぼ0の状態からスタートしましたが、この記事を書くことを通じて色々と勉強することができました。ひきつづき、必要となるスキルセットを習得できるよう努めたいと思います。なお、ロスレスイーサネットを含め、この分野の検証を行なうにはGPUサーバやネットワーク機器が必要ですが、残念ながら、私たちは十分なマシンリソースは持ち合わせていません。機器やラボの借用など、協力してもいいよという機器メーカ様がいらっしゃいましたらお声かけいただければ幸いです。




