AI/ML向け汎用GPUサーバの中身をご紹介
2024年04月16日 火曜日

CONTENTS
はじめに
はじめまして、クラウド本部でインフラエンジニアをしているt-moriyamaです。
最近AIの話題も世間でずいぶんと浸透したようでいろいろとビジネス方面での活用方法が出てきていますが、AI/MLの検証利用目的でDell Technologies社製のGPU搭載サーバ、PowerEdge R750xaを入手しました。今後何回かに分けてGPUサーバやAI/MLに関する情報をお伝えしていきたいと思いますが、まず今回はせっかくなのであまりお目にかかる事が少ないであろう機器の中身を紹介させていただきます。
外観
当該機器は弊社DCの検証ルームに設置しました。

(PowerEdge R750xaを開けて上から見た図、画像の上側がフロント面側)
標準的な奥行1200mmのラックに設置したのですが、ご覧の通り全長が非常に長く背面側のクリアランスがほとんどない無いギリギリの配置になりました。現にマウント位置によっては背面に設置しているPDUと干渉する事が分かったため、それを避ける形でラックの最下部に設置しています。昨今GPU搭載サーバの要件について排熱や消費電力のハードルの高さは認知されてきていますが、筐体の寸法や重量についても意識いただくといいと思います。
PowerEdge R750xaはPCI Express仕様のAI/ML向けGPUを最大で4本搭載できる仕様ですが、今回入手したサーバはNVIDIA A100 Tensorが2本積まれています。
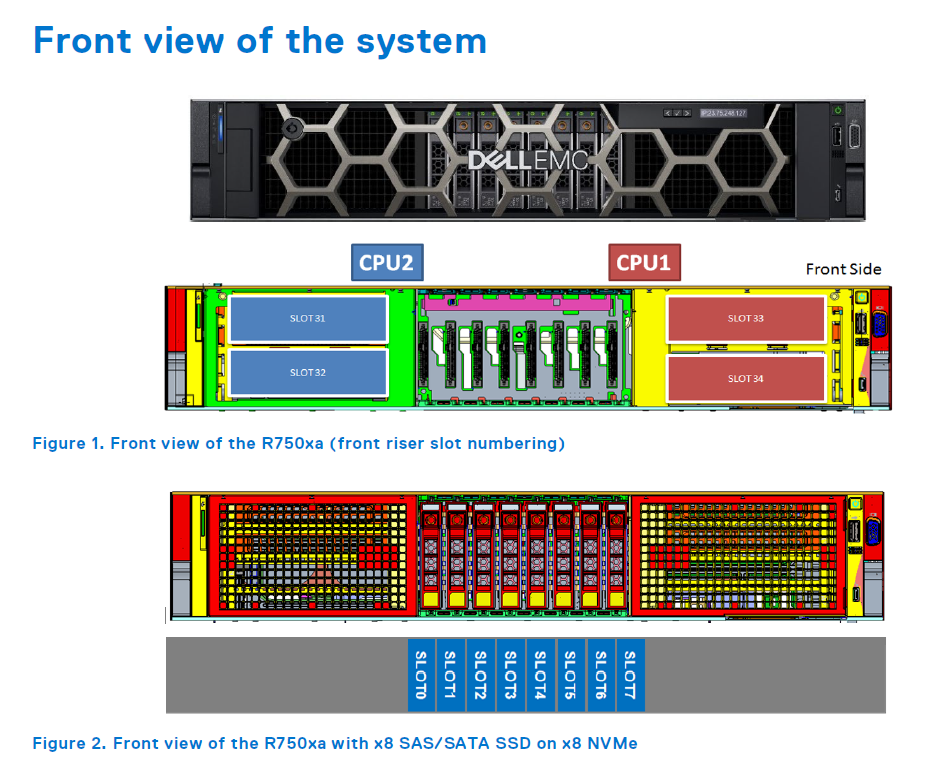
引用元:https://i.dell.com/sites/csdocuments/product_docs/en/poweredge-r750xa-technical-guide.pdf
A100の搭載位置は筐体の最もフロント側で、HDD/SSDドライブベイと同じ並びです。
内部構造
A100をメインボードと電気的に接続するためには専用の信号ケーブルとライザーカードを使用します。メインボード側のコネクタも通常のPCI Expressと違う特殊な形状でした。公式テクニカルガイドではメインボード中継基板をpaddle cardと呼称していましたが、通常のPCI Expressスロットに対してハーフピッチ程度のロープロファイル仕様のようです。

(CPUに隣接するメインボード上のPCI Expressスロットとそこにインストールされた中継基板のアップ)
コネクタ規格の諸元などは見つけられませんでしたが、GPU中継基板側はSFF-8654 74pin仕様のコネクタを2本併用しているのかなと個人的に推測しています。
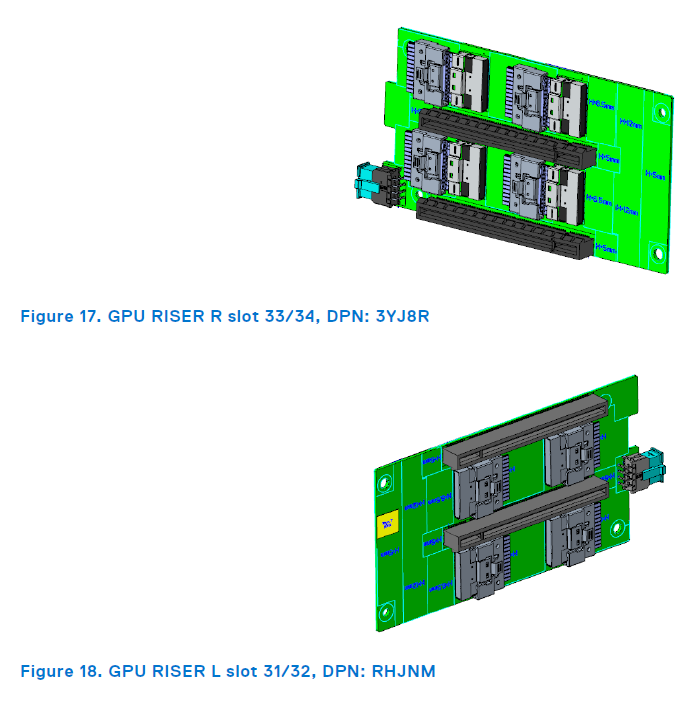
引用元:https://i.dell.com/sites/csdocuments/product_docs/en/poweredge-r750xa-technical-guide.pdf
なおBMC上で確認すると、ちゃんと各カードとも物理的にx16レーンで接続されている事が伺えます。
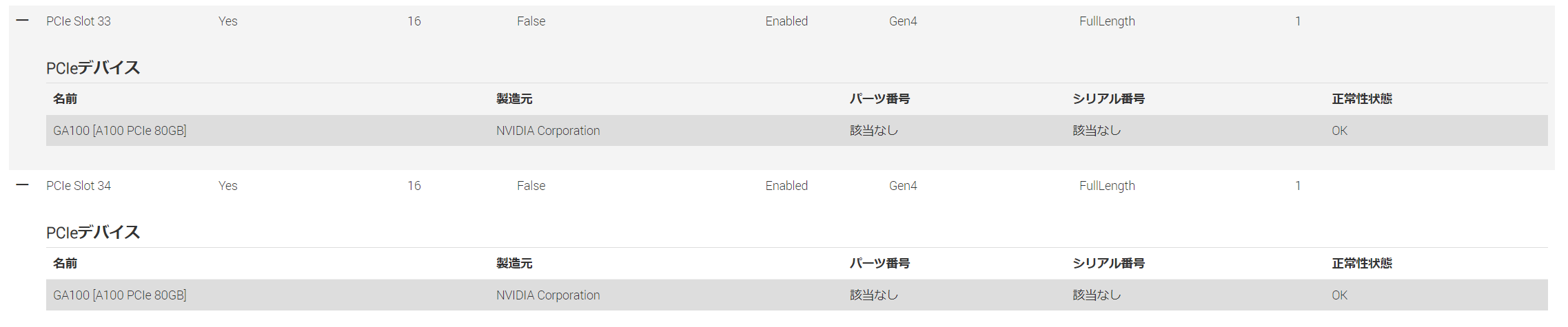
今回入手したサーバのA100は2本ともフロントから見て右側のベイにマウントされ、かつ2つ搭載されたCPUの片側から伸びているPCI Expressバスに接続される形で出荷されていました。恐らくですが、高いパフォーマンスを要求されるAL/ML用途に於いて2つのCPU間のインターコネクトバス(UPI)を経由することによるペナルティを回避するためにあえてこのような非対称設計になっているのだと思います。面白いですね。
専用の信号ケーブルと電源ケーブルを筐体の中央に通す配線になりますが、2本のGPU分だけでもかなり押し込むような密度でした。これが4本のGPUを満載した構成だと、想像するだけでギョッとします。細かいアセンブリの解体手順を公式がメンテナンスマニュアル動画として公開してくれているので、興味のある方はじっくりご覧いただければと思います。
https://www.dell.com/support/contents/ja-jp/videos/videoplayer/how-to-replace-paddle-card-on-poweredge-r750xa/1700848452984839460
NVIDIA A100 Tensor Core GPU !!!
さていよいよ本命のA100とご対面です。


カタログスペック上、A100のPCI Expressモデルはこれ一本で最大300Wを消費するなかなかに大喰らいなデバイスですがご覧のようにファンレス構成です。およそ7~8割ほどの容積を占めるであろう銅製のヒートシンクが目を引きますが、A100とCPUの間に位置するファンが吸気する形でA100のヒートシンクを冷やしてくれる設計です。
このA100はCPUと接続するPCI Expressバスと別にNVLinkと呼ばれるデータバスを持っています。

(2本のA100を直結する黒い3つのNVLinkブリッジアダプタ)
このNVLinkはPCI Expressよりも高速なリンクを形成できる事を謳っており、写真のようなブリッジアダプタを介して2本のGPUをポイントツーポイントで接続することでシステム全体での性能をさらに引き上げることができるそうです。
ただ今回我々の検証ではこのブリッジアダプタを解除して利用することにしました。理由については次回以降のBlogで明らかになるかと思います。
お付き合いいただきありがとうございました。次回のブログでは今回のサーバをセットアップして実際にGPUを用いたAIを動かしてみた事例を紹介する予定です。