キャラクター付けを目的としたファインチューニング-ローカルLLMの底力
2024年10月01日 火曜日

CONTENTS
こんにちわ。とみーです。皆様いかがお過ごしでしょうか?
今回色々ローカルLLMの活用法を模索する中で、やっぱファインチューニングも必要だということで取り組んでいたりします。
その内容について、知った内容等をまとめてみました。
RAGはやっぱり便利だ-この技術の活用法を模索中
実は現在、社内情報を使ったRAG(Retrieval Augmented Generation)向けチャットをさらに良いものにするためにどういう対応が必要かを調べて回ったりしています。これまでの投稿を見ていただけると分かると思うのですが、私個人として実はAPI型LLMというのはあまり取り扱うのが好きではありません。理由も過去の記事を参照いただければわかるのではないかと思います。
とは言え、API型LLMのすばらしさも承知していて、正直なところあれらのLLMには勝てる気がしません。単純性能においては。
やっぱりバックエンド基盤のサイズがケタ違いですし、その中においてオールマイティな推論を行わせるとなるとやはり最先端モデル、ローカルLLMなら最低でも70BサイズのLLMが必要となるでしょう。しかしながら、70Bサイズってどのぐらいのモデルサイズになるかというと、一般的に出回るLLMではおよそ150GB。16bit floatで動かすには150GBのビデオメモリが「最低限で」必要になります。
そんなリソースを独り占め的に使うのは正直無理があると感じていて、だとするならば、現実的に扱えるモデルサイズは恐らく7B-13B当たりのサイズになるのではないかと考えています。これでしたら、よほどロングコンテキストなモデルでない限りは現実的なGPUを使って推論・学習をさせることが出来るのではないかなと思います。
そこで今回は、今組み上げているRAGだけではなく、モデルも一定のファインチューニングを実行したうえでどういうチューニングをしたらよいのかについて考えをまとめてみました。あるいみ私自身独自の理解を挟みながらこうしたものに取り組んでいる関係上、世間一般に比べて遅れたテクノロジを相手にしてるのかもしれませんが、その点は何卒ご了承ください。
ただ、中身を理解しない事には先に進めない性格ということもあり、他と比べて鈍足な側面はあると思いますし、これについては致し方ないと私自身は判断しています。
チャットボットのログイン画面
さて、現在RAGを用いたチャットの構造は以下のようにしています。
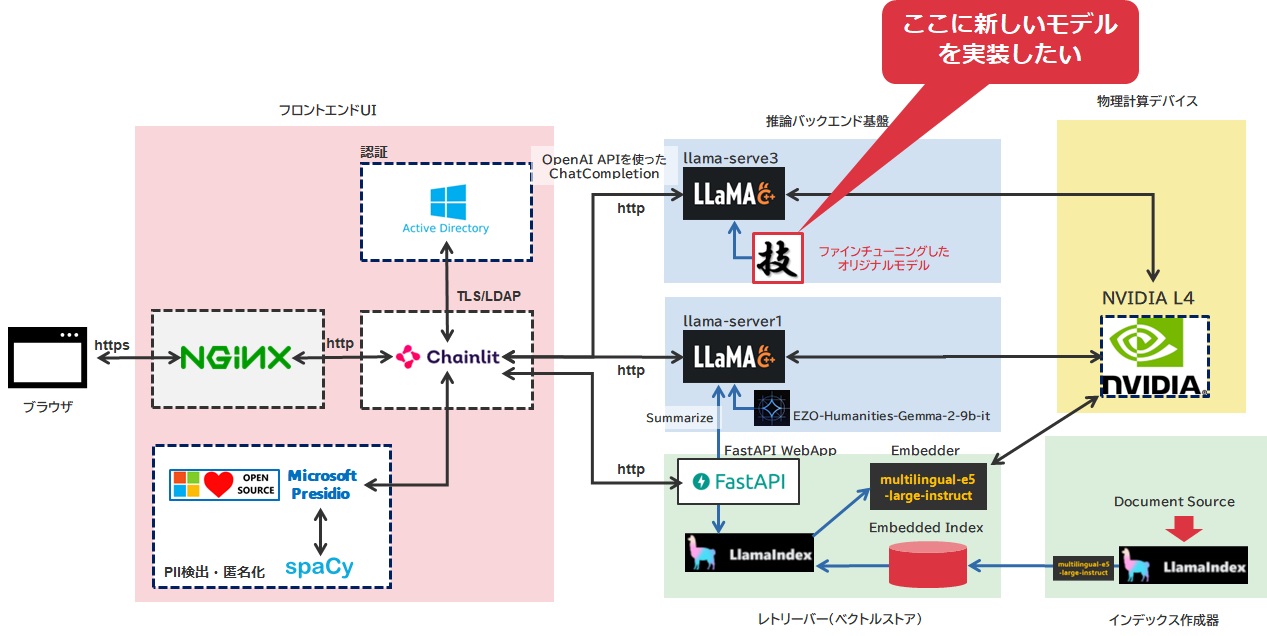
元々以前の投稿でもお伝えしたように、HODACHIさん(現在はAXCXEPT社)からHugging Faceで公開されておりますEZO-Humanities-9B-Gemma-2-itというモデルを使って、LlamaIndex上に登録した社内QAデータを先頭512トークンから複数のEmbeddingデータでベクトル化した状態で登録しており、これを検索しつつ必要な情報を取り出して当社内で取り扱うサービスに関する概要レベルのQAができるチャットボットを試作していってます。
既に実はこれとは別にもっと多くの情報量を用いたチャットボットが本社側の部署で先にリリースされており、それがすでに走っており推論能力も高いのですが、バックエンド側で使われてるLLMがAPI型なのです(詳細は伏せる)。
これに対抗して私の環境ではすべてのリソースにおいてインターネット依存しない構成とすることを念頭に上記システムを組み上げているところです。
EZOモデルはとても汎用性が高く、日本語が上手。意図の読み取りはおろか、アライメントもしっかり施されていてコンテンツフィルタリング的な機能もLlama-3.xと比べると抜群に高いです。ただ、言葉が汎用的すぎるということで、今回のコンセプトは
「もうちょっとばかし当社(IIJ)に魂を売ってもらおうか・・・」
という形で進めたく。
MoRAという方法を知る
総称は High-Rank Updating for Parameter-Efficient Fine-Tuning というもので、一般によく知られるLoRAと似たような差分学習法の一つです。本来するべきフルファインチューニングと比較してVRAM消費を最小限に抑えることが可能です。この手法を知ったのはそれこそX.comでHODACHIさんのツイートを拝見して知りました。
GitHubでこの方法は公開されており、実際にはPeft-0.9.0ライブラリに追加処理を施すことでMoRAの機能を実装する形となります。
https://github.com/kongds/MoRA
実装方法ですが、以下の流れにそって適用します。
- 事前にPeftを導入しておく
- 上記Githubサイトからソースをクローンする。そのあと以下のようにpipコマンドを実行して、Peftライブラリ拡張を行う
git clone https://github.com/kongds/MoRA cd MoRA pip install -e ./peft-mora
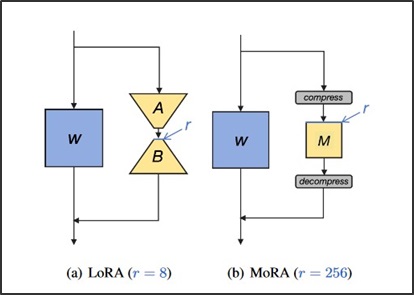
MoRAとLoRA
MoRAとLoRAの違いですが、差分として切り出す行列の構成が大きく変わります。LoRAでは低ランク行列を処理するための変換器Aとそれを元のサイズに戻すための変換器Bを挟んで、ランクrの行列を作ります。rの行列サイズをものすごく小さくすることにより、リソース消費を極限まで減らすことを可能にしています。
しかし、LoRAの場合は、学習する際に取り扱う行列サイズが小さすぎるという問題があります。そのため、その小さすぎる行列の要素(パラメータ)をわずかでも変化させてしまうことにより、既存機能が崩れてしまったり、極端に学習内容が刷り込まれてしまったりすることがあります。
そこで、MoRAの場合は圧縮・復元過程に非パラメータ依存の圧縮機、復元器を通してランクを高めに設定した正方行列Mを差分データとして取り扱います。ここで修正されるデータの影響度はLoRAの場合と比較して下がるため、既存機能に対する干渉を小さくすることが出来るという事のようでして、転じて「新しい知識を適用することに向いている」と言われています。
なお、正方行列というのはその名と図を見ると分かるように、正方形の行列、つまりは行と列の数が同じ行列であることを示します。
 実は、Github上で公開されているMoRAの適用プログラムでは、rの値はLoRAの値をそのまま適用しています。これも論文の中で記述があり、それを参考に内容をまとめてみました。
実は、Github上で公開されているMoRAの適用プログラムでは、rの値はLoRAの値をそのまま適用しています。これも論文の中で記述があり、それを参考に内容をまとめてみました。
MoRAのランク値を求めてみる
論文の中でLoRAだとrとしてあらわされるランク行列の次元数は、MoRAではr^として扱われていました。
この値をベースに計算すると、通常よく使用されるLoRAの値はr=4,8あたりが多いかと思われるのですが、この場合最終的にMoRAに対して適用される値は r^=256 となるようです。

最後に書かれてるように、rはどうやらLoRAモード時の値のままで変更せずに済むようです。この辺りは詳しくは後述したいと思います。
よって、Peftライブラリを用いてLoRA実装をしてた以下のコード
peft_config = peft.LoraConfig(
r=LORA_R,
lora_alpha=LORA_ALPHA,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
lora_dropout=LORA_DROPOUT,
bias="none",
task_type="CAUSAL_LM",
)
これは以下のように表現されるようです。
peft_config = peft.LoraConfig( use_mora=True, mora_type=6, r=LORA_R, target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"], lora_dropout=LORA_DROPOUT, task_type="CAUSAL_LM", )
2行目、3行目にある引数がMoRAに該当するわけですが、ここでmora_typeというのは、LoRAのランク値rが大きいか小さいかによって2つの選択肢があります。
- rが大きい場合は mora_type=1
- rが小さい場合はmora_type=6
とのことで、今回r=8ということでランク値の低い環境では回転行列を適用することを示すType6を適用することが望ましいようです。
公開ソースの中身をやっぱり追いかけてみた。
この辺りの処理は、Github上に公開されてるコードのうち、以下のところに記述があります。
MoRA/peft-mora/src/peft/tuners/lora/layer.py class LoraLayer(BaseTunerLayer)のクラス関数、 def update_layer配下、110行目~
if use_mora:
new_r = int(math.sqrt((self.in_features + self.out_features)*r)+0.5)
if mora_type == 6:
# type 6 require new_r to be even for RoPE
new_r = new_r//2*2
self.lora_A[adapter_name] = nn.Linear(new_r, new_r, bias=False)
self.r[adapter_name] = new_r
nn.init.zeros_(self.lora_A[adapter_name].weight)
self.lora_B[adapter_name] = self.lora_A[adapter_name]
self.use_mora[adapter_name] = True
self.scaling[adapter_name] = 1.0
元のコードでは、そもそもuse_moraの値が存在する場合の条件分岐がありません。つまり上記こそが追加されたMoRAの処理ということになります。r^という変数はここではnew_rという変数で宣言されています。理論上では+0.5が追加されていませんでしたが、このコードではmath.sqrtで計算された値に+0.5した状態でint型へ変換する処理が書かれています。
ここで、rの値が小さい場合、MoRAではRoPEを用いた回転行列を適用してその文章の位置情報を付与しようとしますが、その性質により次元数は必ず2の倍数(要は偶数)とする必要があります。そのため、mora_type=6に設定されている場合、確実に偶数に設定するための処理として、一度int型の値を2で割り、2を掛けるということをすることにより、偶数を導出できるようにしているようです。そう考えてみると、int型にする際の+0.5はここで効いてくるかもしれないですね。
本来行列を縮小するはずのA層はnew_rを一辺とした正方行列に置き換えられます。そして、元のサイズに戻すためのB層はA層と同一の値であると設定されています。
スケーリング値は、LoRAの場合はα/rで計算されるのですが、MoRAの場合これが1.0に固定されています。
詳細はこれ以上は省略します(私自身の力の限界によるものです、ごめんなさい)が、基本的にはこの正方行列の中に差分データが書き込まれ、その後の処理でRoPEが組み込まれ、正方行列が正しくモデルに組み込まれるようにReshapeされた後で次の層へ処理が移動するというような形で動くようです。
実際にファインチューニングした場合のLoRAとMoRAの動きの違い
実際のファインチューニングに際して使用しているプログラム等は後述するために内容は前後するのですが、ファインチューニングを様々な学習率・様々な方式に切り替えつつ試した結果、loss値の変化が面白いことになりました。
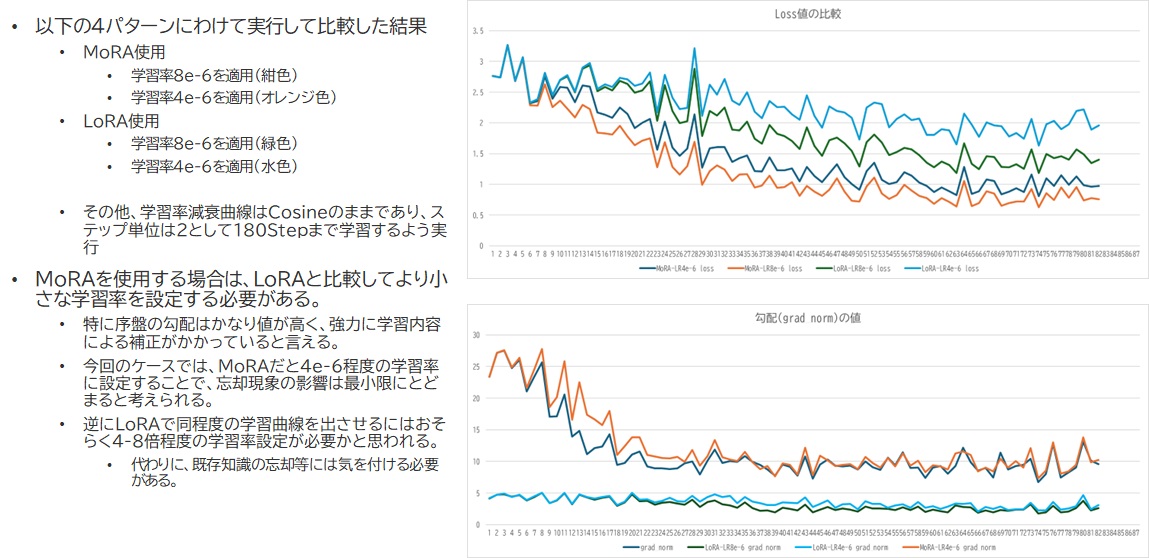 右上のグラフがloss値(Optimizerに渡される誤差値)、右下のグラフが勾配値です。MoRAとLoRAでは特に勾配値に大きな差が出ることが分かりました。それだけより強力にOptimizerに対して変更をかけるよう指示が出ていることになります。対してLoRAは勾配が常に低値であるため、実際のloss値としてもなかなか値が0に向かいません。学習率が低いとほぼ値が下がらず、学習できてるのかどうかがかなり怪しい状況となってます。
右上のグラフがloss値(Optimizerに渡される誤差値)、右下のグラフが勾配値です。MoRAとLoRAでは特に勾配値に大きな差が出ることが分かりました。それだけより強力にOptimizerに対して変更をかけるよう指示が出ていることになります。対してLoRAは勾配が常に低値であるため、実際のloss値としてもなかなか値が0に向かいません。学習率が低いとほぼ値が下がらず、学習できてるのかどうかがかなり怪しい状況となってます。
こうしたことから、MoRA自体に結構強力な収束力があるように感じられました。と同時に、一定値に収束するとそこで勾配値は下がり、過剰な学習を避けるような動きをしているように思えました。
ファインチューニングの実行
今回使用している環境は以下ですね。(今回も本社側の環境を少々お借りして検証を行っています。)
- Intel(R) Xeon(R) Gold6442Y × 2( 24core 48Threads)
- 512GB (32GB×16) (DDR5)
- PRAID CP500iによるRAID構成:System: RAID1, Data:RAID5+1Hotspare
- 1GbE x1, 25GbE x2, 100GbE x2
- NVIDIA L40S x2(ada lovelace/VRAM48GB GDDR6)
以下のプログラムを実行して試行しました。以前に多様なファインチューニングにGemma-1.1で挑んだことがあるんですが、今回リソースが潤沢だ!ってことで敢えてbfloat16のままでファインチューニングを試みました。LoRA差分データをまず生成し、その後それを元モデルとマージしてマージドモデルとして出力するようプログラムを書いています。後は別途.envファイルの設定が必要です。
#
# EZO-Common-9B-Gemma-2-itモデルのファインチューニングスクリプト(教師あり)
# Dataset は .envで振り分けられたデータに従い使用形態を定める
# Huggingface trlライブラリ内のSupervised Fine Tuning Trainerを使用する
# 2024/9/13 y-tominaga
#
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import TrainingArguments,BitsAndBytesConfig
from trl import SFTTrainer, DataCollatorForCompletionOnlyLM, SFTConfig
import datasets
import datetime
import peft
from peft import PeftModel
import os
import pandas as pd
from pathlib import Path
from dotenv import load_dotenv
from transformers.trainer_utils import set_seed
load_dotenv()
# 乱数のシードを設定する
set_seed(42)
# 定数の設定(環境変数.envより取得)
BASEMODEL_ID =str(os.getenv("BASEMODEL_ID"))
BASEMODEL_TOKEN =str(os.getenv("BASEMODEL_TOKEN"))
DATASETMODE =str(os.getenv("DATASETMODE"))
DATASETLOCALDIR =str(os.getenv("DATASETLOCALDIR"))
DATASETID =str(os.getenv("DATASETID"))
DATA_MAXLENGTH =int(os.getenv("DATA_MAXLENGTH"))
LORA_R =int(os.getenv("LORA_R"))
LORA_ALPHA =int(os.getenv("LORA_ALPHA"))
LORA_DROPOUT =float(os.getenv("LORA_DROPOUT"))
TRAIN_BATCHSIZE =int(os.getenv("TRAIN_BATCHSIZE"))
TRAIN_ACCUM_STEPS =int(os.getenv("TRAIN_ACCUM_STEPS"))
TRAIN_WARMSTEPS =int(os.getenv("TRAIN_WARMSTEPS"))
TRAIN_SAVESTEPS =int(os.getenv("TRAIN_SAVESTEPS"))
TRAIN_MAXSTEPS =int(os.getenv("TRAIN_MAXSTEPS"))
TRAIN_LR =float(os.getenv("TRAIN_LR"))
TRAIN_LOGGINGSTEPS =int(os.getenv("TRAIN_LOGGINGSTEPS"))
MODEL_SAVEDIR =str(os.getenv("MODEL_SAVEDIR"))
# データパターンによる学習プロンプトのテンプレート
# Contextが存在する場合
prompt_with_context_format = """<start_of_turn>user
{context}{instruction}<end_of_turn>
<start_of_turn>model
{response}<eos>"""
# Contextが存在しない場合
prompt_no_context_format = """<start_of_turn>user
{instruction}<end_of_turn>
<start_of_turn>model
{response}<eos>"""
# ログ出力処理
def log_output(log_message):
now = datetime.datetime.now()
timestamp_string = now.strftime('%Y-%m-%d %H:%M:%S')
print(str(timestamp_string) + " - " + log_message)
# サンプルプロンプト化処理(SFTTrainerが使用する)
def format_samples(samples):
prompts = []
# データセットの instruction 列と input 列と output 列を組み合わせてプロンプトを組み立てます。
for instruction, output in zip(samples["instruction"], samples["output"]):
prompt = prompt_no_context_format.format(instruction=instruction, response=output)
prompts.append(prompt)
return prompts
#
# メイン処理
#
def main():
# デバイスの選択
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"device: {device}")
# ベースモデルIDの定義
model_id = BASEMODEL_ID
# トークナイザの作成
tokenizer = AutoTokenizer.from_pretrained(
model_id,
padding_side="left",
TOKENIZERS_PARALLELISM=False,
token=BASEMODEL_TOKEN
)
# モデル構築の実行
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
token=BASEMODEL_TOKEN,
attn_implementation="eager",
use_cache=False,
)
#元モデルは推論モードで取り込む
model.eval()
#データセットモード:HF/CSVの設定を入手
dataset_mode = DATASETMODE
#データセット指定
if dataset_mode=="HF":
#データセット指定(Huggingfaceから拾う想定)
dataset_name = DATASETID
dataset = datasets.load_dataset(dataset_name,split="train")
dataset = dataset.shuffle(seed=42)
else:
#取り込みデータをdatasets.load_datasetで読み取り
filepath = DATASETLOCALDIR
dataset_lib = filepath
dataset = datasets.load_dataset("csv",data_dir=dataset_lib)
# 取り込みトークン数上限の設定
data_max_length = DATA_MAXLENGTH
# ベースモデルをフリーズ
for param in model.parameters():
param.requires_grad = False
if param.ndim == 1:
param.data = param.data.to(torch.float16)
# VRAM消費量を節約するための調整
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
log_output("ベースデータ取り込みが完了しました。")
# モデルの概形表示を行う
print(model)
# PEFTを用いたMoRA学習の設定
# PEFT設定の定義(更新対象はAttn層のQKV及びOutput、MLP全般)
# BIASは使用しない
peft_config = peft.LoraConfig(
use_mora=True,
mora_type=6,
r=LORA_R,
target_modules=[
"q_proj",
"o_proj",
"k_proj",
"v_proj",
"gate_proj",
"up_proj",
"down_proj"
],
lora_dropout=LORA_DROPOUT,
task_type="CAUSAL_LM",
)
# モデルにLoRAをかぶせた状態にする
model = peft.get_peft_model(model, peft_config)
log_output("MoRA可変パラメータの適用が完了しました。")
model.print_trainable_parameters()
# トレーニング処理準備
# DataCollatorにresponse_templateを指定することで、回答のみを評価できるようにする
response_template = "<start_of_turn>model"
data_collator = DataCollatorForCompletionOnlyLM(response_template, tokenizer=tokenizer)
# チェックポイント及び完成モデルの配置場所(任意に定義。必要に応じてディレクトリは自動作成)
now = datetime.datetime.now()
timestamp_string = now.strftime('%Y%m%d_%H%M%S')
save_dir=MODEL_SAVEDIR + "/" + timestamp_string
# GPUのキャッシュをクリアにする
torch.cuda.empty_cache()
sft_config = SFTConfig(
per_device_train_batch_size=TRAIN_BATCHSIZE,
gradient_accumulation_steps=TRAIN_ACCUM_STEPS,
warmup_steps=TRAIN_WARMSTEPS,
save_steps=TRAIN_SAVESTEPS,
max_steps=TRAIN_MAXSTEPS,
learning_rate=TRAIN_LR,
bf16=True,
logging_steps=TRAIN_LOGGINGSTEPS,
output_dir=save_dir,
optim="paged_adamw_32bit", #A100の場合はこちらを有効にする
dataloader_pin_memory=True,
lr_scheduler_type="cosine", #学習スケジューラはCosineを使用
weight_decay=0.001, #AdamWにおける全体の学習減衰率
max_grad_norm=0.3, #勾配クリッピング
max_seq_length=data_max_length,
)
# SFTTrainerの定義
trainer = SFTTrainer(
model=model,
train_dataset=dataset["train"],
args=sft_config,
data_collator=data_collator,
peft_config=peft_config,
formatting_func=format_samples,
)
# Flash Attention 2を使用するため、SDPカーネルを有効にした状態で実行する
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
trainer.train() # 学習を実行
log_output("トレーニング完了:MoRA差分データを書き込みます")
#トレーニング結果の保存
model.save_pretrained(save_dir) # outputフォルダに学習後のモデルを保存
log_output("MoRA差分データ書き込み完了しました。")
# モデル・Trainer・キャッシュ等のクリア
del model
del trainer
torch.cuda.empty_cache()
log_output("クリーンアップ処理が完了しました。")
#
# マージモデルの作成
#
# ベースモデルの再読み込み
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
attn_implementation="eager",
cache_dir="checkpoints",
use_cache=False,
)
log_output("トークナイザ・ベースモデルの再読み込みが完了しました。")
#モデルEmbeddingの再定義
model.resize_token_embeddings(len(tokenizer))
#LoRAファイルの再取り込み
peft_name = save_dir
model = PeftModel.from_pretrained(
model,
peft_name,
device_map="auto",
)
model.eval()
log_output("差分データ取り込み及び推論モード切替完了しました。")
# Merged-model Save Directory Defined.
now = datetime.datetime.now()
timestamp_string = now.strftime('%Y%m%d_%H%M%S')
save_dir="/home/localadms/sft/merged/" + timestamp_string
# Create Merged-model and Save.
merge_model = model.merge_and_unload()
merge_model.save_pretrained(save_dir, max_shard_size="2GB")
log_output("モデルマージ処理完了:データ書き込みが完了しました。全処理を終了します")
if __name__ == "__main__":
main()
ハイパーパラメータは以下の通り設定してみました。
- 学習率:2e-6
- ステップ数:500steps
- 使用したデータセット
- つくよみちゃんデータセット : 凡そ525件ほど(リンク・説明は本ブログ末尾に記述させていただいております)
- 独自に作成したサービス略称と総称を1対1で紐付けたデータ 130件ほど
受け答えの確認
さて、チューニングした結果を眺めてみるのですが・・・無念

ちょっ・・・これ、ちょっとあんまりじゃないですか?ってぐらいに応答が無機質で、さすがに涙がポロリしました。で、原因を突き止めてたりしたのですが、これ、どうやらデータセットの言葉が少なすぎたことに原因がありそうです。
データセットに対するRaR(Rephrase and Respond)
元のデータセットでは例えば以下のようなやり取りがあります。
- <ユーザ> 一日つかれたよ。
- <bot> お疲れ様です。ゆっくりお休みくださいね。
これ自体は、ありふれたユーザとボット間のやり取りであることが分かるわけですが、これがどうもベースとしているGemma-2的にはかなり短いやり取りのようで、この喋り方に塗りつぶされてしまい、元モデルに含まれていたおしゃべりな性格が消えてしまったようです。そこで、以下のような仕組みを用いてこのデータセット上のボットのやりとりをLLMに推論させてみました。
以前、私自身調べて適用したことのある手法の中で「RaR(https://arxiv.org/abs/2311.04205)」というUCLAで生まれた手法がありまして、正式名称は「Rephrase and Respond」っていうのですが、ユーザが入力した質問文を一度LLMが解釈しやすいようにLLM自身の手でRephrase(つまり言い換え)させることによって回答精度を上げるというものがありました。
要は今回採用している方法はいわば「データセットに対するRaR」的な手法と考えるとよいのかなと思います。
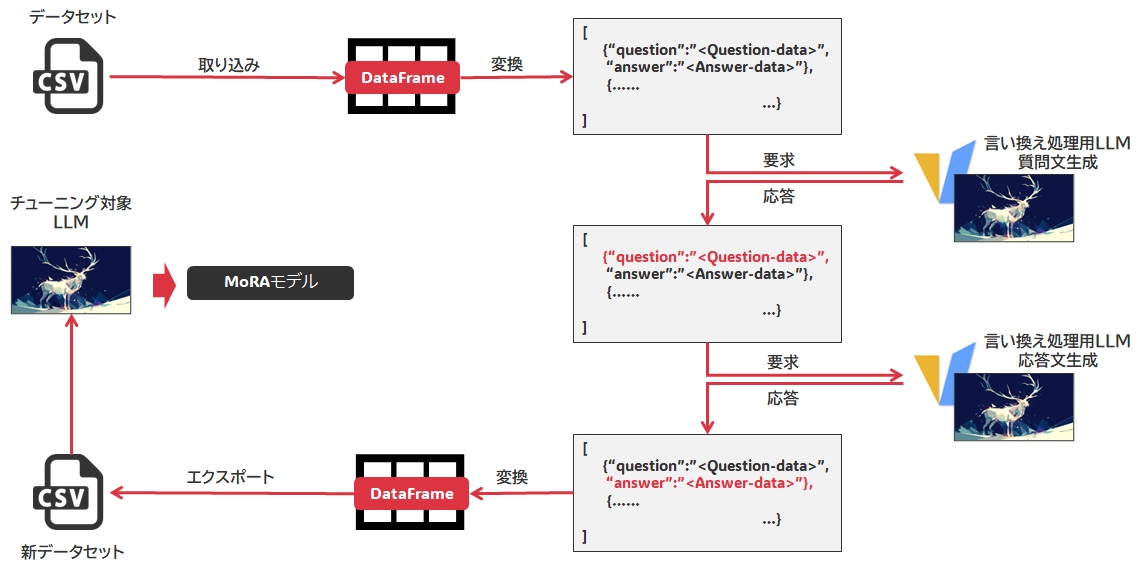
LLMによるデータセット内容の更新
- データセットからデータをロードし、JSONレコード方式に変換します。
- そのデータセット内容に基づき、質問文の言い換えを実行します。これにより、Question-dataの内容が更新されます。
- 続いて、更新された質問を付与して、望むキャラクターに基づいた回答となるように回答文の言い換えを実行します。これによりAnswer-dataの内容が更新されます。
- 更新されたQuestion-data, Answer-dataに基づいてDataFrameにまとめた後、これをCSV変換します。
- これをファインチューニング向けにカスタマイズし、実際にMoRAによるファインチューニングを行います。
なお、推論内容がそぐわない場合はそのケース自体の削除、あるいはその内容の修正を行います。 - 出来上がったモデルを使用して推論を試みてみます。
言い換えに使用するシステムプロンプト
各推論時に用いるシステムプロンプトは以下のようにしました。また、原作のデータセットでは明示的にキャラクターに名前を与えてその上で会話が行われてましたので、適当な名前を定めてこれを踏まえて推論をさせるようシステムプロンプトを構成しています。

システムプロンプト
先述したやり取りは以下のようにデータが書き換えられました。
- <ユーザ> お疲れ様です。今日は一日、お忙しかったのでしょうか?何か大変なことがあったりしましたか?
- <ボット>お疲れ様です!
私、Hueyはいつも元気なので、一日中「大変」って感じることはあまりないんです。でも、IIJスタッフの皆さんをサポートして、少しでもお仕事がスムーズに進むように頑張っているので、その意味では今日も充実した一日でしたよ!何か困っていることがあれば、いつでも私に声をかけてくださいね!
お、なんだか元々Gemma-2が答えてそうな回答に加えて少し元気さが加わったような気がします。
そうして用意したデータが以下の通りで、これを用いて再度先述したスクリプトを用いてファインチューニングを実行してみました。
- つくよみちゃんデータセットから、データセットRaR処理を施し、適用が難しいケースを除外したデータセット(合計493件)
- サービス略称と正式名を1対1で対応付けたデータセット(181件)
リベンジファインチューニングの状況
学習させてみると、やっぱり違いが分かりますね。以下は同じMoRA手法でデータセット更新前・更新後の状態でファインチューニングを行った時のloss及び勾配の状況です。
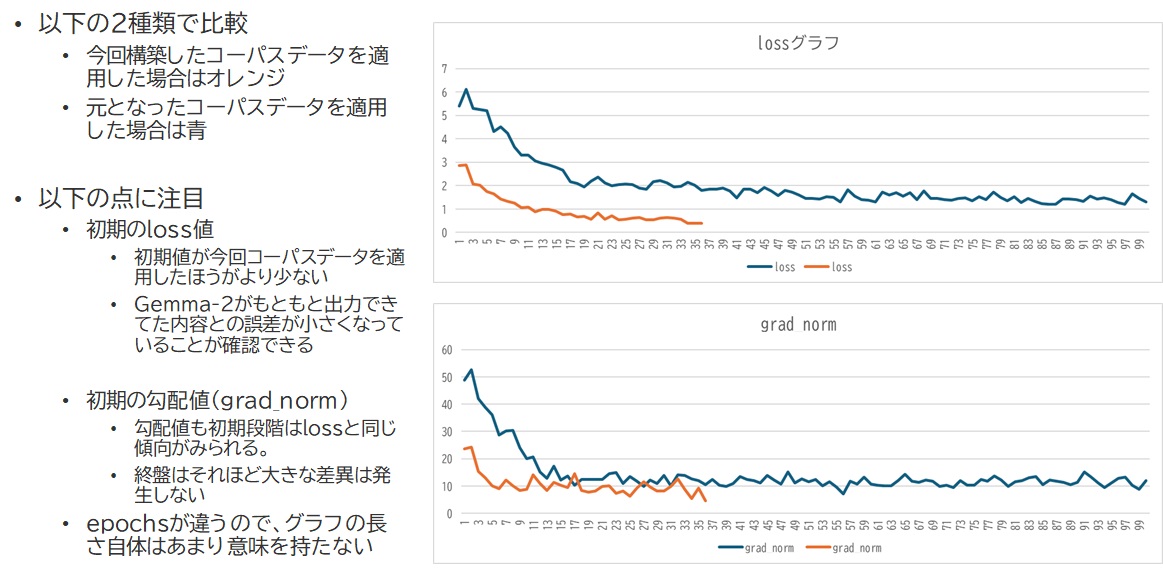
データセットRaRを実行した場合としない場合
データセットRaRを実行してない場合は青色の線で示しているのですが、初期の誤差がやっぱり何もしなければ多いんですね。これが最終的に1.0近傍まで下がってくるということは、それだけ強力に「データセット通りの推論結果を出せ」と迫られてるようなものなのです。つまりは、既存の会話パターンを失っていく過程であるといっても過言ではありません。どんなにStepsを小さく設定しても序盤ですでに1.0まで急激に引き寄せられてることを考えると、恐らくepoch数を1前後にしても大して結果は変わらないでしょう。
これをデータセットRaRを実行することによって、元々モデルの喋り方に寄せたデータセットが相手ですので、まず誤差であるloss値が小さいです。そこからじわじわ引き下げられるような動きをしてるため、既存会話パターンの情報が適度なところでデータセットとマージされたものと考えられます。この辺りの強さを比較した結果としては、勾配の序盤の値を見ると明らかですね。
そしてリベンジ推論!
再度推論してみたところこうなりました。

お、なんだかいい感じではないでしょうか。一部英語のままになってるところがありますけれども・・ちゃんと当社に魂を売った受け答えになっとる!!
ほかの質問に対する推論においては、元モデル、ファインチューニングしたモデル(データセットを改変したもの、データセット改変前のもの)を並べて評価してみました。
 元モデルは口数の多さが目立つのと、質問をした結果に対する答えの粒度が細かいというのが分かります。
元モデルは口数の多さが目立つのと、質問をした結果に対する答えの粒度が細かいというのが分かります。
逆に元データでファインチューニングを試みた場合は、文章が破綻しているように見えますが、これは単に質問の例をいくつか列挙しただけなんですね。ただ、言葉足らず過ぎて誤解を与えてしまう内容になっています。
以下のケースでもそんな感じが表に出てきてますね。

データセット改変後のファインチューニングを実施したモデルは、両者のちょうど間をとったようなバランスの良さがあり、相手から与えられた質問に対する回答として必要なところは押さえてるように見受けられます。
という訳で今回意図する形に多分ファインチューニングは持って行けたんじゃないか!?って気がします。
まずは第一関門突破した的なお気持ちですw
本来あるべきファインチューニングとはずれるやり方
実は、今回取り組んだファインチューニングは、trlというライブラリの中に含まれる Supervised Fine-Tuning (SFT)という手法を使っています。教師ありファインチューニングという手法で、データセットから以下の2要素を取り込んで学習させます。
- Instruction(指示内容)
- output(正解とみなされる回答内容)
outputに対して記述している「正解とみなされる」という所が実は本来のInstruction Tuningとは大きく異なり、本来のInstruction Tuningはその指示の解釈の仕方、推論の順序、そして推論結果を学習させることが本筋であるとされているのですが、SFTの場合はここが少々異なり、あくまでInsturctionで与えられた指示を「outputこそが正解である」と取り扱って強力にその通り答えるよう軌道修正をさせる働きがあります。
そのためにとても学習にかかる拘束力が強く、学習率の設定が非常に難しいというのが印象的でした。ただ、このSFT を実行するSFTTrainerは非常に便利な側面もあり、特にプロンプト作成にかかる手間がものすごく省ける点は非常に私たちのファインチューニングに対するハードルを下げる効果があると感じていて、なんだかんだ言いながらも結局はギリギリの調整をしながらSFTTrainerを使い続けてる現状もあります。
特にキャラ付けに関しては一貫したキャラ付けの下でoutput例を示すことにより、学習状況の調整はloss値及び勾配値を見定めながらで適用するというのはそれ自体はあまりStepsも多くを要しないという意味でよいのではないかなと感じています。
また、SFTTrainerにちょうどよくフィットする他の関数がないというのも理由の一つで、本当にInsturction Tuningをするぞってなると、恐らくtrlライブラリではなく、もっと原始的なTrainerを使うしかないのかなと今のところは感じています。そうなった場合のTrainer設定のつくり方の煩雑さを考えると、導入部分としてSFT Trainerの利用はアリなのではないかなと思ってます。
RAGとファインチューニングを組み合わせ、コレサイキョウ
私自身、実はRAGとファインチューニングは以下の通り認識してまして。
- RAGはLLMにカンペを見せてあげる技術
カンペを見せることで、LLMは言語ベクトルの範囲及び確率呼び出しに一定の制約を受ける
回答方向、回答内容をガイドすることにより、より意図に沿った回答を誘導させることが可能 - ファインチューニングはLLMに追加情報を焼き付ける技術
LLMのベースナレッジとして、根っこを支える情報を支える技術であり、ただ基本的に一度焼き付いた情報はなかなか消去されない
基礎情報やキャラクター設定はRAGで何とかしようとするよりLLMに焼き付けたほうが良いと感じる。
これはまさにその通りなのかなーと今回の実装を通じて感じています。
今回のファインチューニングモデルも、RAGと組み合わせて初めて威力を発揮するモデルであり、雑談には実はあまり強くありません。そりゃそうだという話で、だってIIJサービスのことを何も引っ張ってこれない状況下だと、せいぜい知ってる情報としては当社のサービス名称の対応付けぐらいしか分からないんですから。
ファインチューニングモデルとしてすべてを焼きこむのではなく、例えばRAGに対してやたらめったら反復推論させたくないなぁ・・・とか思ってるような(なぜならば、LLMへその場で言い直しさせるたびに推論処理が発生して回答速度が遅くなるから)基礎的な内容だったりだけを焼き込んで、それ以外の高度な知識をRAGで提供し、あとはそのベクトル特性をきちんと理解したうえで検索可能とするような仕組みを作ることで、高度な質問に対してはRAGの知識をベースにあくまで「LLM自体は一種の日本語纏めLLMとして使用する」ことで特化タスク化、より高度な回答を表現できるように仕立てるという手法がだいぶ役に立つのではないかな?という気がしました。
なお、あまりプロンプティングなどでガチガチに回答の方向性を固めてしまうと、LLM内で選べる選択肢が減りすぎて思ったような推論ができなくなり、結果として言語構成自体が破綻したものを並べてくることがあります。情緒的に書くのもあれですが、あまりLLMを追い詰めすぎるのもよくないということで、LLMがどういう仕組みに基づいて推論をし、結果を出力するのかについて考えつつLLMは設計していくとよいのかなと思いました。
後覚えるべきは「アライメント」か?
実はまだ取り組んでない技術が「アライメント」です。
これについては私自身基礎的なものとしてDPO(Direct Preference Optimization)を勉強中なんですが、本社で取り組んでる人の中にこれを徹底的に理解をして行きたいという人がいまして、その人にそうした解説の座は譲りたいなーなどと考えているところです。
アライメントっていうのは、本来公序良俗に反する回答を防止する目的で実装される機能であり、当初盛り上がっていたのはRLHF(Reinforcement Learning from Human Feedback)という報酬モデルを用いたフィードバック手法でした。そこから現実的に学習コストを抑える方式が次々と登場しているのですが、今回私も触れたtrlライブラリから提供されているもっとも取り扱いやすい技術はDPOかなーと思いますので、並行して私も取り組んでみたいと思います。
実はアライメントって「分からないものは分からない」って答えさせるには?とか、「情報漏洩を防止するためのLLM実装」についても関連性がある技術でもありますので、Enterprise方面においては必須の技術になるのかなと思ってます。主流はPPO(Proximal Parameter Optimization)のほうですが、まずはきちんと押さえるものを押さえたうえで、下手な背伸びはせずに着実な理解を・・・・!を第一に考えながらこの技術には取り組んでいきたく考えています。
今回引用・適用させていただいたもの・補足
今回検証・実装に際して参考にさせていただいたデータセット・LLM・技術情報に対して以下の通り紹介させていただきます。
心より御礼申し上げます!私としても非常に勉強になるところが多く、知見がすごく広がりました。
- つくよみちゃん会話AI育成計画 https://tyc.rei-yumesaki.net/material/kaiwa-ai/ © Rei Yumesaki
- AXCXEPT/EZO-Common-9B-gemma-2-it https://huggingface.co/AXCXEPT/EZO-Common-9B-gemma-2-it
- MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning https://github.com/kongds/MoRA
- MoRAに関する論文 https://arxiv.org/abs/2405.12130
- AIDB RaRに関するまとめ https://ai-data-base.com/archives/51160
今回実装したチューンドモデルについて
なお、当方がこの度作成したモデル自体は社外秘情報を多く含んでいる関係上HuggingFace等リポジトリでの公開ができません。予めご承知おきください。(利用する領域も社内利用に縛って運用しております)
データセットに組み込んだボットの名称に関して
ちなみに今回データセットに組み込んだ名前、Huey(ひゅーい)は私の現在のハンドルネーム「ゆーい」からとったもので、「ゆーい」という綴りからなんかいい仮の名がないものかと考えたところ、ぱっと思い浮かんだのが北斗の拳に登場する「南斗五車星、風のヒューイ」という、かのラオウに瞬殺されたキャラクターでして、「これだ!」と採用した感じです。
実際にはこうしたボットの名称は焼き付けられたAttention/FFN上の情報としては「固有名詞の一種」として残るようで、プロンプトで明示的に名称を指定した場合はそちらに基づくようです。(実際に当方で設定したプロンプトに基づき名前を問うたところ「私の名はAssistantです」と返しました。ファインチューニングの強度によりけりですが、何もプロンプトで指定しなければデータ上の名称が用いられる可能性が高いのかもしれませんね。でも、より強く名称を固定したい場合はプロンプティングで指定したほうが良いと思われます)