1つの大きなLLM(大規模言語モデル)を複数のGPUで力を合わせて動かそう
2024年05月07日 火曜日
CONTENTS
LLM群雄割拠の時代
昨今、ローカルGPUで駆動できるようなLLM(大規模言語モデル)もかなり増えてきて、キャッチコピー的に「ついに我が家にもGPT-4が!」とか言われるようになってまいりました。パラメータ規模で言えば70億~130億(7B-13B)パラメータ、700億(70B)パラメータ、1400億(140B)パラメータあたりのモデルが活発にリリースされているように見受けられます。
大きなモデルをGPU寄せ集めしつつ遊びたい!
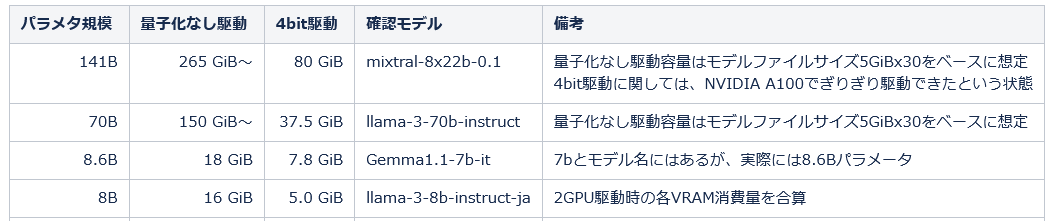
しかしながら、コンシュマー向けのGPUにおいては、7B-13B規模ぐらいなら量子化という技術を使うことでなんとか動作可能ですが、さすがに70B規模となりますと動かすのはAI特化型のGPUでもそう簡単には行きません。その手前にある例えばMixture of Experts(MoE)というアーキテクチャで動作するような8x7B系のモデルでもアクティブに動作するパラメータ数は40B-50Bパラメータありまして、実際単体GPUでの駆動は難しいのではないかなぁと思います。いくつかこれまで確認できた中でパラメータ規模と必要VRAM容量についてまとめてますので掲示してみました。
実は以前から思っていたことで「複数のGPUを寄せ集めて1つのモデルが動かせたりしないかなぁ?」ってのがあったんですけど、探せど探せど見つかるネタは「ジョブを分散して学習処理を高速化する」とか「Stable-Diffusionのようなモデルでよりたくさんの画像を並列処理で出力できないか」とかそういった種類のものばかりで、「1つのモデルを複数のGPUで動かす」という情報はなかなか手に入らず苦慮しました。
今回、たまたまが重なって色んなことが出来ることが分かりましたので、そのあたりについて述べたいなぁとか思ってます。
「device_map=”auto”」という設定
知ってる人は知ってると思うのですが、モデルを作成するときに「device_map=”auto”」って設定をすることがあったりしませんか?
LLM系の知見を持ってる人が息をするように当たり前に書いてるこの設定。実はこれこそが「1つのLLMを複数GPUに跨って実行させる設定」なんですよね。
例えばこんな内容
model_id = "meta-llama/Meta-Llama-3-70B-Instruct"
HF_TOKEN=os.getenv('HF_TOKEN')
bnb_config = BitsAndBytesConfig(
load_in_8bit=True,
)
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id,token=HF_TOKEN)
model = transformers.AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
quantization_config=bnb_config,
low_cpu_mem_usage=True,
device_map="auto",
token=HF_TOKEN,
)
print(model)
これは、AI/ML向け汎用GPUサーバの中身をご紹介って記事で紹介されているマシンをお借りして検証した際に、LLaMa-3-70b-instructを動かす際のPythonプログラムを一部抜き出したものです。プログラムでは8bit量子化状態で動いているのですが、その際 device_map=”auto” という一文をmodel定義の設定値に入れることで、もし2つのGPUがそのマシンに搭載されていれば、プログラムは二手にモデルを分割して動かすようになります。
Hugging Faceのサイトにあるページでも紹介されてます。
この処理は「並列処理」ではなく、「ディスパッチ」と言われ、直訳すると「派遣する」なのですが、単一GPUでは処理し切れないものを複数のGPUあるいはCPU、ストレージも含めて余裕あるリソースに対して処理を派遣してもらって対応する意味合いで使われてるようです。行われてる処理自体は「並列処理」ではないと言えば確かにその通りです。これに対してHugging Faceはもう一つの解釈として「モデルの並列化」という言葉を使っています。
異なるGPUを組み合わせても動かせる!
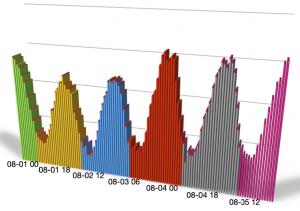
実はこれ、異なるGPUの組み合わせでも動かすことが出来ます。以下の環境は私の所属する九州支社の技術推進課が有する検証サーバでLLaMa-3-8b-instructを動かしてみたときのGPUリソースグラフなのですが、ちゃんとGeForce RTX 3060とNVIDIA L4に分散されて動いていました。但し、Tesla P100を含めようとするとCUDAカーネルが起動しないと怒られたのですが、どうやらFlash_Attention_2が有効化してたことが原因だったようです。
最近個人の方でも(一般のご家庭なのか、逸般の誤家庭なのかはこの際問わない)、GeForceやQuadro系のGPUを複数組み合わせて動かされてる方が増えてきましたし、恐らくはこういう方法で動かして検証や学習処理をなさってるのだろうなーと推察しています。いやはやこの仕組み素敵。
なお、モデル並列化をすると、本来GPU1枚分の処理を複数に分けて実行させる関係上、GPU処理負荷はその分減るようです。
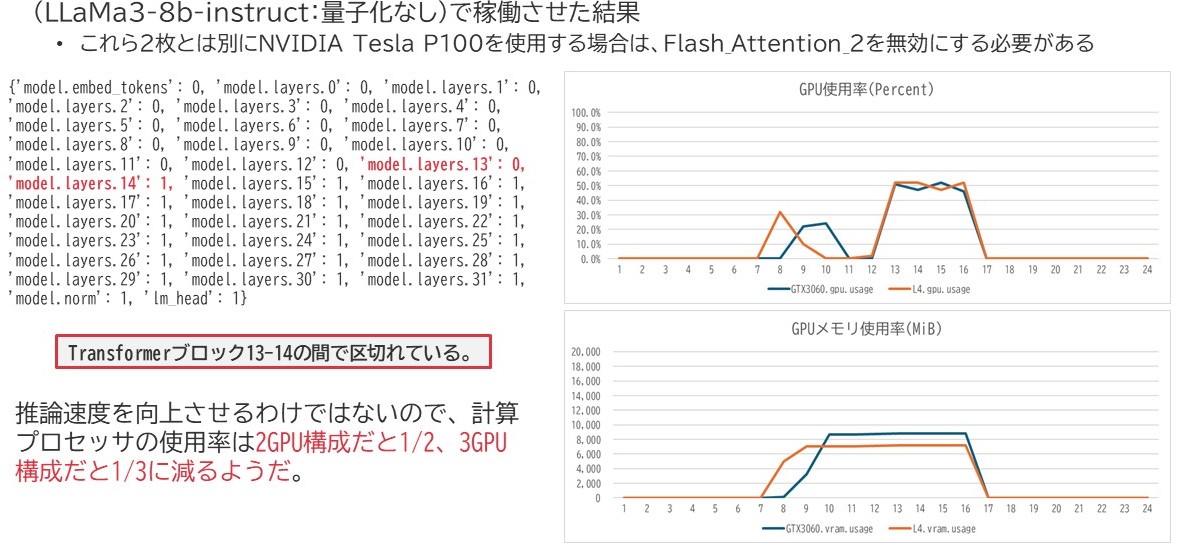 また、上図に記述しているGPUの割り当てとレイヤーの関係に関する記述は、Pythonスクリプト上でprintを使えば出力できます。左側にパラメータ名あるいはレイヤー名、コロンを挟んで右側にGPU番号が並んでいます。基本的にLLaMa3でもMixtral-8x7B, Mixtral-8x22Bいずれもレイヤー単位で「真ん中ではないちょっと手前側」という所でレイヤーが区切られていました。
また、上図に記述しているGPUの割り当てとレイヤーの関係に関する記述は、Pythonスクリプト上でprintを使えば出力できます。左側にパラメータ名あるいはレイヤー名、コロンを挟んで右側にGPU番号が並んでいます。基本的にLLaMa3でもMixtral-8x7B, Mixtral-8x22Bいずれもレイヤー単位で「真ん中ではないちょっと手前側」という所でレイヤーが区切られていました。
print(model.hf_device_map)
この間の接続は nvidia-smi topo -m で確認できます。
■九州支社の環境
GPU0 GPU1 GPU2 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X SYS SYS 0-11 0 N/A
GPU1 SYS X SYS 0-11 0 N/A
GPU2 SYS SYS X 0-11 0 N/A
■例のA100環境
GPU0 GPU1 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X PHB 0-11 0 N/A
GPU1 PHB X 0-11 0 N/A
■GPU間の接続形態
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
モデル並列化に伴い、ばらされたモデル間をつなぐ接続は上記表示で確認することが出来ます。
GPU内部で処理する場合と比べて当然メモリ帯域は減少しますので、そこがボトルネックとなり速度劣化となる可能性はあるのかなと思います。「例の」環境の場合、NVLinkでつなぐとどうなるんだろうかなーというのは別途内部でも話してますが、そうそう簡単に繋ぎ変えができない環境下にありますので、そのあたり今後の検証の中で確認していくのかもしれないです。
Stable-Diffusionには通用しない
これってもしかしてStable-Diffusionにも通用するんだろうか?と思って挑んでみたらこうなりました。

というわけで、基本的に適用できるのはLLMぐらい(つまりはTransformersを使った処理)であろうと考えて使ったほうがよさそうです。
Stable-Diffusionのような、所謂Diffusersライブラリを使用するようなモデルについては、別途並列の処理に関する記述があり、そこでは学習時に使われるような分散処理の方法が記述されていたことから、こういう動きはあまり想定されてないのかもしれないです(単純に私が調べ切れてないというのも十二分にあり得るんですけどね。)
device_map設定の意味
先述したHugging Faceサイトの記述に『device_map=”auto”にしとけばとりあえず十分だよ』とあり、実際そうすればかなり効率的に動作することが分かっているので、特にそれ以上気にする必要はないのですが、やっぱりそこを深堀したく、もう少しこの意味を調べてみることにしました。
そもそもこの設定は何をしてるのでしょうか?
実はこの設定は transformers ライブラリが持ってる機能ではなく、間接的に accelerate ライブラリが呼び出されています。こちらもHugging Faceが提供しているライブラリ群の一つです。本来は、GPUにおける並列処理を目的として使用され、データ分散化であったり、DeepSpeedとの連携であったりを対応してくれるとても便利なツールでありライブラリです。なので、これのソースを眺めつつ確認を進めてみることにしました。
accelerateライブラリ内部で行われていること
accelerateのライブラリはこちら。
load_checkpoint_and_dispatchという関数
実はモデル呼び出し時のdevice_map設定が存在する場合、transformers ライブラリは間接的にaccelerate ライブラリ内の load_checkpoint_and_dispatch という関数を呼び出しています。まずはこの load_checkpoint_and_dispatch というものが何者かを確認してみます。
この関数は src/accelerate/big_modeling.py 内にあります。498行目に以下のような記述から開始されています。
def load_checkpoint_and_dispatch(
model: nn.Module,
checkpoint: Union[str, os.PathLike],
device_map: Optional[Union[str, Dict[str, Union[int, str, torch.device]]]] = None,
max_memory: Optional[Dict[Union[int, str], Union[int, str]]] = None,
no_split_module_classes: Optional[List[str]] = None,
offload_folder: Optional[Union[str, os.PathLike]] = None,
offload_buffers: bool = False,
dtype: Optional[Union[str, torch.dtype]] = None,
offload_state_dict: Optional[bool] = None,
skip_keys: Optional[Union[str, List[str]]] = None,
preload_module_classes: Optional[List[str]] = None,
force_hooks: bool = False,
strict: bool = False,
):
引数に目を向けると下表のようになってました。
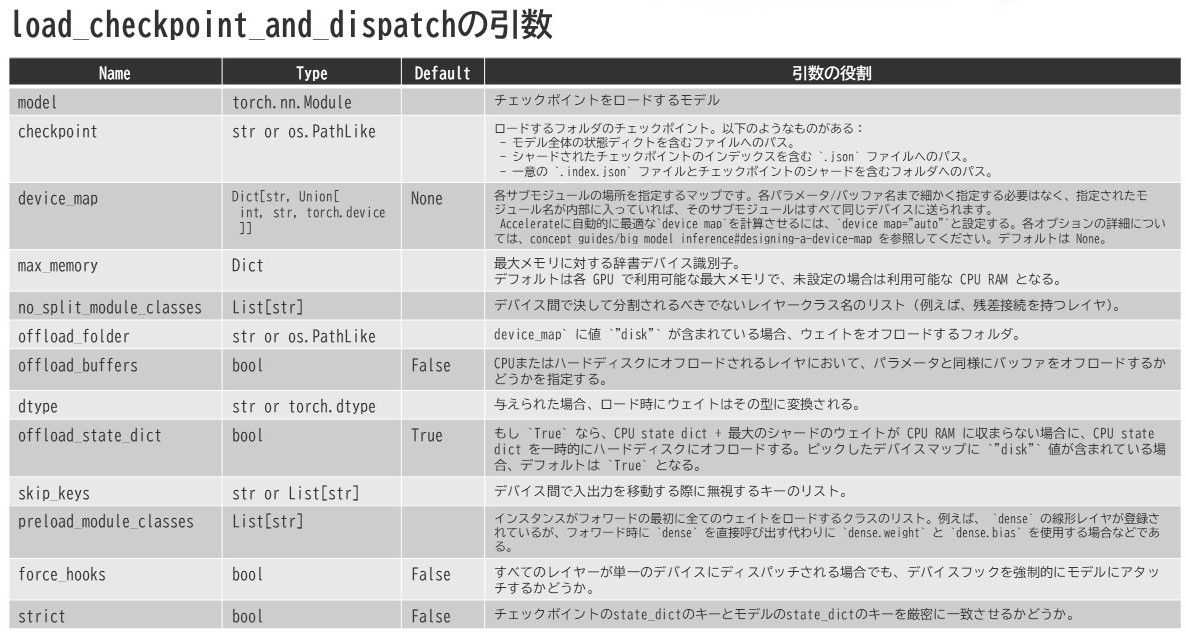 ここでdevice_mapというものが登場していますが、実はこのdevice_mapというのは大きく分けて4種類あるようです。
ここでdevice_mapというものが登場していますが、実はこのdevice_mapというのは大きく分けて4種類あるようです。
- auto
- balanced
- balanced_low_0
- sequential
ここでautoが選ばれており、先述した関数はこのdevice_map設定を受け取ってその後のモデル内分割を処理してるように見えます。ちょっとそのあたりを眺めてみようと思います。この関数が処理を受け取った時に最初に行う処理を見てみると、device_mapの定義によって分岐してる処理が見受けられました。589行目から開始される以下の記述ですね。
if isinstance(device_map, str):
if device_map != "sequential":
max_memory = get_balanced_memory(
model,
max_memory=max_memory,
no_split_module_classes=no_split_module_classes,
dtype=dtype,
low_zero=(device_map == "balanced_low_0"),
)
device_map = infer_auto_device_map(
model,
max_memory=max_memory,
no_split_module_classes=no_split_module_classes,
dtype=dtype,
offload_buffers=offload_buffers,
)
device_mapが「sequential」に設定されていなければ、max_memory変数はget_balanced_memory関数の応答結果に従うように構成されています。
つまり、どの程度のメモリ容量で分割するのか、それ自体はこの関数であらかじめガチっと値を決めてしまうんだなという事が分かります。
get_balanced_memoryという関数
この関数は src/accelerate/utils/modeling.py で定義されており、919行目にこんな記述から開始されています。
def get_balanced_memory(
model: nn.Module,
max_memory: Optional[Dict[Union[int, str], Union[int, str]]] = None,
no_split_module_classes: Optional[List[str]] = None,
dtype: Optional[Union[str, torch.dtype]] = None,
special_dtypes: Optional[Dict[str, Union[str, torch.device]]] = None,
low_zero: bool = False,
):
その先の処理でデバイスの数を数えていますね。955行目~976行目です。今回我々の環境は末尾のelse文まで飛び、CUDAデバイスのカウントが行われます。
NPU/MLUであったりXPUであったりが存在する場合、その手前でカウント処理がなされるようです。併せて、それらの利用可能なメモリ量の確認を行っています。
# Get default / clean up max_memory
user_not_set_max_memory = max_memory is None
max_memory = get_max_memory(max_memory)
if is_npu_available():
num_devices = len([d for d in max_memory if torch.device(d).type == "npu" and max_memory[d] > 0])
elif is_mlu_available():
num_devices = len([d for d in max_memory if torch.device(d).type == "mlu" and max_memory[d] > 0])
elif is_xpu_available():
num_devices = len(
[
d
for d in max_memory
if (
d != "cpu"
and (torch.device(d).type == "xpu" or torch.xpu.get_device_properties(d).dev_type == "gpu")
)
and max_memory[d] > 0
]
)
else:
num_devices = len([d for d in max_memory if torch.device(d).type == "cuda" and max_memory[d] > 0])
モデルレイヤーのパラメータ数やサイズに関する情報は、以下のように compute_module_sizes 関数を使って割り出しています。
これら得られた情報を元にして、割り当て可能な1GPUあたりの最大メモリ容量を割り出していく感じです。ぶっちゃけ単純に割って平均を出していますね。
module_sizes = compute_module_sizes(model, dtype=dtype, special_dtypes=special_dtypes) per_gpu = module_sizes[""] // (num_devices - 1 if low_zero else num_devices)
また、単純に割るだけでは場合によっては「そこで分離してはダメ!」ってなるような層があったりする(例えばLayerNormalize層とか)ので、その指示に基づいてモデルを分析し、バッファサイズとして計上していくというようなことも行っています。ここで変数名に指定されているleavesというのが、モデルのleaf、つまり末端のパラメータを指しており、そこで定義されてる内容を元に情報を集積してバッファサイズを計上しているようです。
# Compute mean of final modules. In the first dict of module sizes, leaves are the parameters
leaves = [n for n in module_sizes if len([p for p in module_sizes if n == "" or p.startswith(n + ".")]) == 0]
module_sizes = {n: v for n, v in module_sizes.items() if n not in leaves}
# Once removed, leaves are the final modules.
leaves = [n for n in module_sizes if len([p for p in module_sizes if n == "" or p.startswith(n + ".")]) == 0]
mean_leaves = int(sum([module_sizes[n] for n in leaves]) / max(len(leaves), 1))
buffer = int(1.25 * max(buffer, mean_leaves))
per_gpu += buffer
# Sorted list of GPUs id (we may have some gpu ids not included in the our max_memory list - let's ignore them)
gpus_idx_list = list(
sorted(
device_id for device_id, device_mem in max_memory.items() if isinstance(device_id, int) and device_mem > 0
)
)
最終的にそれをdevice_id順にまとめ、Dict型に成型してmax_memory値が返っていくことになります。
呼び出し元に戻った後の動作概要
その後、呼び出し元の big_modeling.py に戻って次はinfer_auto_device_map へ飛ばされ、デバイスマップとしてどのような割り当てにするかを具体的に計算させるわけですね。メモリの割り当てとしてメインはここまでであり、以降の処理はディスクやCPUへオフロードする場合の処理及び、実際に割り当てられたデバイスマップ設定に従い、モデルの割り振りを行う処理が続いていきます。
こうした動きを見ていくと、先に述べた4種類のdevice_mapのモードは以下のようなものであることが分かります。
- auto…デフォルト設定であり、全自動。balanced_low_0設定に近い。
- balanced…極力均等にメモリ割り当てを行う
- balanced_low_0…balancedに近いが、GPU-0の割り当てパラメータ量を少なめに設定する
- sequential…GPU番号の若い順に詰め込む
それ以外のdevice_map指定の方法
そのほかにもdevice_mapを指定する方法はあります。特に手動割り当てをする場合ですね。Hugging Faceのページで例示されてたのは以下のようなものでした。
 手動で設定する内容としても、かなり細かい設定が可能になっていますね。
手動で設定する内容としても、かなり細かい設定が可能になっていますね。
レイヤー等モデル内部構造単位で記述するのは非常に大変そうな感じではありますが・・・。基本は自動割り当てで行うことが賢明なのでしょうね。
この辺りは例えば、Slurm Workload Managerのようなバッチスケジューラで、GRESという機能と連携させるともっと便利になりそうに思います。特に特定のGPUグループだけを稼働させたいとかGPU単位のON/OFFをするにはそうしたミドルウェアの連携で行わせたほうが楽な印象を受けました。
終わりに
インフラエンジニアとして活動してた時、ここまで調べるケースってほとんどなく、どちらかというとリファレンス頼りにしていたケースが多かったような気がします。どんなに手順書の完成度が低くても、説明が分かりにくくても、最低限そのAPIであったり、周辺モジュールであったりのリファレンス説明だけは大体網羅できてたような印象があるのですが、こうしてPythonプログラムに触れるようになってから、リファレンスそれ自体が全体を網羅しきれてないケースがあったり、情報が散逸されていたりで、結果的にソースを見ないと分からない・・・となることが増えたような。
Hugging Face製ライブラリの品質が悪いというわけでは決してありませんで、むしろソース上にはものすごく丁寧に説明が記述されていたので、そこを読み進めていけば処理の全体は確実に把握できると思います。何なら今だとAPI型LLMに突っ込んでプログラムの解説をさせてみるのもいいかもしれない(一部私もそうしました。すごくわかりやすくGPT-4先生に教えてもらいましたw)。おそらくは、頻繁に更新が為される現状において、もうソースに詳細説明を書いたほうが確実なんじゃないかという所からこういう書き方に至ってるのかな?という気もしております。
これは、インフラエンジニア側が取り扱うものとして、プロプライエタリ製品が圧倒的に多いこと、それ故にブラックボックス化されているところを調べるケースが多いからかな?という気がしますけど、単純にそれだけではないようにも思えます。インフラ側でもOSSプロダクトを使うケースってそれなりにあると思いますし、そうしたときにはもう少し情報の接し方が変わってくるような気もします。(Heartbeat(またの名をPacemakerとも言う)のリソース定義スクリプトとか直に読まないと絶対わかんないですしおすし)
こういう所は開発エンジニアとインフラエンジニア間の価値観の違いに跳ね返ってるのかもしれないですね。すごく勉強になっております。