9,573個ものRFCドキュメントをDifyで全部取り込んでみた話
2025年07月18日 金曜日

CONTENTS
はじめに
こんにちは、IIJ九州支社のとみーです。先日、本社の人から
作りたいものあるんですけど。
今手元のRFC全文のテキストファイルがあるんですけど。全部で9573個のファイルです。
これ全部ベクトルDB化してRAGで検索する方法って作れちゃったりしますか?
という話がありまして。動機を伺ったのですが「IIJらしいんじゃないかなーと(笑)。」とのこと。
こういう取り組み、私はとっても「大好きだし面白そう」と思いまして、ほぼ脊髄反射的に「Sounds good, let’s do it!(いいね、やろうやろう!)」と返事して取り組んだのが今回のネタです。
RFC全文をすべてDifyのナレッジDBへ組み込む試み
実は割とこの手のアプリケーション試作をした方はそれなりにいらっしゃるようで、ざっとWeb上を検索するだけでも
とかあるようでして。ただ、コードの内容を拝見する限り、これらはRFCドキュメントをWebグラウンディングを行って情報を引っ張ってくる仕組みのようでして、ちょっと今回のやり方とは異なるやり方でした。(ホントはWebグラウンディングで探索した方が絶対いいんだろうなってのは私も思います。)
九州支社・社内向けAIアプリ開発基盤の紹介
さて、以前の投稿でも申したように、2024年頃からIIJ九州支社ではAIを活用したツールづくりにDify Community Edition を活用しています。ユーザ数23、アプリ数119のそれなりな大所帯な、内部利用だからこそ取り組めることを盛り込みまくった魔改造テナントです。(もちろん、ライセンス抵触しないようにEnterprise Featureは使用していません。)
- プロキシ配下で正常に動作するようにdocker-compose.ymlを独自に組みなおしています。
- コンテナはスケールさせて動作(DifyバックエンドはPythonベースであり、その並列度を向上させることが目的)
- 特にPlugin_daemonは背後でクラスタウェアが動いてるので、比較的大きなサイズへスケールアウトさせることが可能です
- プラグインはソース精査したうえでがっつり取り込んでいます。必要に応じて独自プラグインも作って実装しています。
- あまりプラグインを仕込み過ぎるとメモリ要求量が増加しますのでご注意を・・・
- 周辺に複数のMCP-SSEサーバを構成(Dify Agentノードから利用するには基本的にSSE/StreamableHTTPが必要になります)
- Nginx/API/Worker/Sandbox/PostgreSQLも巨大化を想定してパラメータチューニング済(これをおろそかにすると多分色々厳しいです)
これ以外にも、全社的にはユーザ数100を超えるDifyテナントもあったりしますが、使い込み度・魔改造度は多分こちらの方が上です。
Difyでは本来、日本語の全文検索はほぼ機能しませんが、Phenexテナントでは事前にWeaviateに「GSE」というアジア言語向けのトークナイザを仕込んで(https://github.com/langgenius/dify/pull/12258)います。これにより、デフォルト設定では単語処理ができていなかったものを実用的な状態に改善し、ヒット精度を向上させています。
(実は、WeaviateにはKagome-jaという日本語に特化したトークナイザにも対応しているのですが、Dify内部でJiebaというGSEの元になるトークナイザが動作していることから、これらの連携を考慮して一定の全文検索能力はGSEでも向上可能であろうと判断し、これを採用しています。)
とあるWebアプリ開発風景
取り込み対象のデータ:全部テキスト形式の英文、9573個のRFCドキュメント(rfc0001-9779)
今回挑むのは、RFC全文をDifyのRAG用データとして全取り込みする・・・というやり方であり、自分自身どんなことが起こるのか興味津々なところがあり、思い切って全突っ込みしてみることにしたのが今回の全容です。
今回扱ったデータの規模:
- ファイル数:9,573個
- ファイル容量:496MB(ZIP圧縮後132MB)
このマンモス級のビッグデータ、突っ込んでRAGを実行してもちゃんと処理できるんでしょうか?
親子チャンクという選択
今回採用したのは、Difyでおそらく最もよく使われる「親子チャンク」という構造です。Dify 0.x系最後のメジャーバージョンであった0.15で登場したチャンク方式です。
親子チャンクとは?
親子チャンクは、ドキュメントから切り出した一塊の段落として「親チャンク」を設定し、さらにそこから短文や単語などの「子チャンク」を切り分ける手法です。

とあるRFC文書を取り込ませた場合の親子チャンク構成例
処理の流れ:
- 子チャンクがベクトル化される単位として処理される
- 子チャンクの類似度によって親チャンクの類似度が決定される
- 最終的にLLMには文脈豊富な親チャンクが渡される
なぜ親子チャンクなのか?
今回のDifyナレッジ設定
親チャンク分割設定
親子チャンクの設定として以下の通りにしています。親チャンクは文書全体と段落単位の2種類の分割方法を選択できます。
文書全体を指定すると、ドキュメントによっては想定以上の膨大な量になることがあり、うまくコンテキストに含められなくなる可能性があります。そこで、今回は段落単位方式を採用、しかしながら最大トークン長は定義可能な最大文字列数として、極力長文をしっかり確保できるように構成しました。
子チャンク分割設定
逆に子チャンクは「\n」だけを区切り文字とすることで、テーブル化した情報や行単位で要素として出力されたものをきれいに文章としてキャッチすることを目的としました。こちらも親チャンクほど長い文章は要求しませんが、極力包括的なベクトル検索を行いたかったこともあり、最大長を2048トークンに設定しています。
ベクトルモデル選定
ベクトルモデルは、本社内の推論基盤でも使用されている snowflake-arctic-embed-l-v2.0 というモデルを使用します。
このモデルはXLM-RoBERTaというモデルをベースにしたEmbeddingモデルです。XLM-RoBERTa自体が元々マルチリンガル性能が高い上に、コンテキスト長最大8,192まで対応しており、加えて次元数は1,024となっていて、非常にパフォーマンスが高いことが特徴となっているモデルです。これをローカルGPUで駆動させている当方の推論基盤にアクセスして利用します。
設定まとめ
親チャンク:極力大きな区切りで文章を取得する
- 親チャンク分割単位:段落
- 最大トークン長:4,000
- 区切り文字:
\n\n\n
子チャンク:極力小さな区切りで文章を取得する
- 最大トークン長:2,048
- 区切り文字:
\n
ベクトルモデル:ローカルSLMを使用し、次元数が低めのEmbeddingモデルを適用
- 九州支社内推論基盤:
snowflake-arctic-embed-l-v2.0を使用- トークン長8,192対応のローカルSLM
- 次元数:1,024(軽量かつ高品質)
- llama.cpp側の設定で同時接続4つまで対応
- Vibe Coding での挑戦、APIゲートウェイの制作で紹介した経路を通じて非同期処理
検索方式
検索方式については、「ハイブリッド検索」を採用しました。
以前からRAGに取り組む人々からよく言われていたことではあるのですが、ベクトル検索だけでは求める単語がマッチしないこともあります。
2023年ごろではベクトル検索でマッチする確率は凡そ60-70%程度と言われており、実際に業務で検証したときも同程度の精度にとどまっていたことを経験則で知っています。
これを補足してくれるのが「全文検索」という仕組みです。全文検索とは、BM25というアルゴリズムを使用して検索する仕組みのことで、単語の出現度や文章の長さからその妥当性を判断する仕組みです。この仕組みを併用することにより、精度を90%前後まで引き上げることが可能と言われており、今回の設定もこちらを採用しています。
とは言え、実は当時使用していたEmbeddingモデルは text-embedding-2-ada であり、現在使用可能なEmbeddingモデルも非常に性能向上を果たしていることから、当時低かったベクトル検索のみの構成でも現在では比較的高いレベルの精度を実現させていると考えられます。
また、プロダクト更新運用の煩雑さが発生するため、GSEの採用はあくまでこの基盤に限定させているという事情があったりもします。
さらに、ハイブリッド検索時は全文検索・ベクトル検索の利用比率を固定設定する方法と、Rerankerと呼ばれるモデルを使用する方法がありますけれども、当方の環境では「Reranker利用」を採用しました。Rerankerモデルには BAAI/bge-reranker-v2-m3 を使用しています。
処理フローの詳細解析
今回の取り組みで、Difyの内部処理フローが明確になりました:
以下はドキュメントを受領してからすべての子チャンクがベクトル化されるまでの過程を描いたものです。
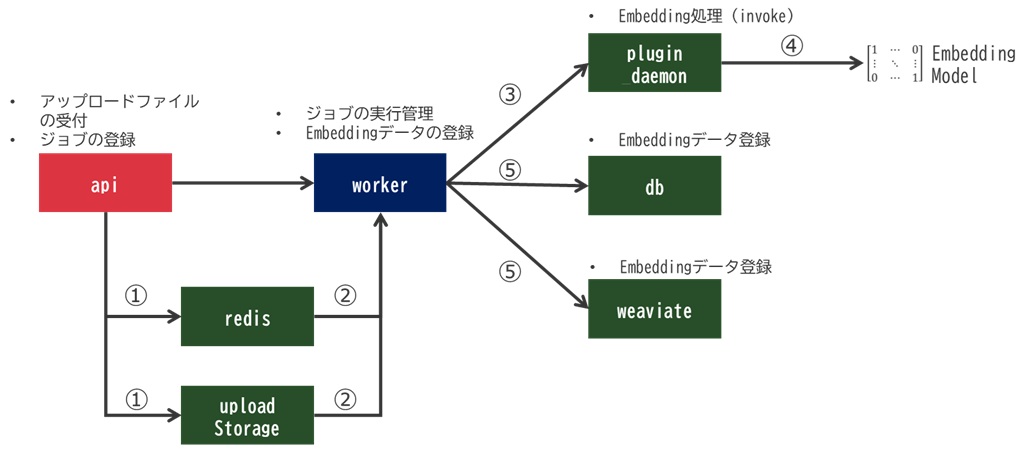
- ファイルアップロード〜ジョブ投入
- ユーザがファイルをアップロード
- APIがアップロードストレージにファイルを保管
- 指定されたチャンク長に文章を区切り、Embedding準備
- Redisにジョブを配置(チャンク、ファイル、Embeddingモデル指定等)
-
- Worker処理
- WorkerがRedisをポーリングしてジョブを受け取り
- アップロードファイルを確認し、Plugin_daemonにジョブを構成
- Plugin_daemonが指定されたEmbeddingモデルで処理開始
- 処理結果として、Embeddingモデルは1024個の配列データを生成してPlugin_daemon→Workerへ返す
- Workerはベクトル情報を受け取り、構成DBやベクトルDBにデータ登録
- 全ての処理対象が完了するまで繰り返し実行
1ジョブは1ドキュメント単位で、Worker処理は逐次実行ではなく、指定値に基づいたミニバッチサイズで実行されています。
今回の環境では、ミニバッチサイズはデフォルト値の5を適用しています。
実際の挙動をログで追いかける
以下はファイルがアップロードされ、それがapiコンテナへ伝送される際のログです。apiが管轄するdatasets(ナレッジ処理)に関わるところへファイルがアップロードされています。
Jun 25 15:46:25 ********** 1afa96a884df[1292]: 172.19.0.1 - - [25/Jun/2025:06:46:25 +0000] "GET /console/api/datasets/90f2776f-**********2ab6a0d5/documents?page=8&limit=10&keyword=rfc97 HTTP/1.1" 200 972 "https://**********/datasets/90f2776f-**********2ab6a0d5/documents" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36" "**********"
以下はWorkerコンテナ側のログに出力される、チャンク処理開始を示すものです。ミニバッチサイズである5という設定値に従い、スタート時点は処理が5並列で開始されていることを確認しています。
2025-06-24 09:45:38.000 INFO [Dummy-9] [document_indexing_task.py:63] - Start process document: eb2ba77f-3db4-44d4-9581-97ac0cc35ee8 2025-06-24 09:45:38.001 INFO [Dummy-9] [document_indexing_task.py:63] - Start process document: ff08e175-c69e-4a80-912d-8cd1217cf572 2025-06-24 09:45:38.002 INFO [Dummy-9] [document_indexing_task.py:63] - Start process document: d81807b1-8a1a-46d7-91e4-cb13963e031c 2025-06-24 09:45:38.003 INFO [Dummy-9] [document_indexing_task.py:63] - Start process document: 96f412f4-2ad7-4b18-a14a-5442d5770ac5 2025-06-24 09:45:38.005 INFO [Dummy-9] [document_indexing_task.py:63] - Start process document: 53fed2f5-7934-4ac6-ae17-5e769f86415b
そして以下は処理が完了したことを示すログです。それぞれの処理に関して、成功したか失敗したか、処理にかかる時間はどの程度であったかを示しています。
2025-06-25 00:55:55.633 INFO [Dummy-21] [trace.py:128] - Task tasks.retry_document_indexing_task.retry_document_indexing_task[b9e2fbbd-432c-4826-b89a-c2f0d8d04482] succeeded in 47.713665023999056s: None 2025-06-25 01:54:30.829 INFO [Dummy-22] [trace.py:128] - Task tasks.retry_document_indexing_task.retry_document_indexing_task[8d898f23-909f-4a3c-80bc-87b2f2764ee0] succeeded in 15.301617569988593s: None 2025-06-25 02:15:05.462 INFO [Dummy-23] [trace.py:128] - Task tasks.document_indexing_task.document_indexing_task[9a7676af-9d8a-4f3f-9e2a-5c70334864d2] succeeded in 32.586590607999824s: None 2025-06-25 02:20:17.606 INFO [Dummy-14] [trace.py:128] - Task tasks.document_indexing_task.document_indexing_task[ab224017-6445-418f-9bf7-2e6c66f5b711] succeeded in 8261.202724258008s: None 2025-06-25 02:33:39.886 INFO [Dummy-24] [trace.py:128] - Task tasks.batch_clean_document_task.batch_clean_document_task[ea57d93d-1590-493f-8b09-85c9b5c9b32f] succeeded in 3.9740077469905373s: None 2025-06-25 02:37:05.021 INFO [Dummy-25] [trace.py:128] - Task tasks.recover_document_indexing_task.recover_document_indexing_task[033195ca-cc03-4e0d-8bfb-735766add16f] succeeded in 10.095585725008277s: None 2025-06-25 02:38:22.673 INFO [Dummy-26] [trace.py:128] - Task tasks.recover_document_indexing_task.recover_document_indexing_task[f5bb0073-f0b5-46e0-b0c0-2b107679255c] succeeded in 6.326359754020814s: None 2025-06-25 02:39:03.797 INFO [Dummy-27] [trace.py:128] - Task tasks.batch_clean_document_task.batch_clean_document_task[1a099581-f59d-433e-8061-c30029aeae89] succeeded in 1.0931832040078007s: None 2025-06-25 02:39:11.434 INFO [Dummy-28] [trace.py:128] - Task tasks.batch_clean_document_task.batch_clean_document_task[02b86aa1-5d00-4bb2-824c-e7421097246d] succeeded in 0.036155017995042726s: None 2025-06-25 02:41:27.079 INFO [Dummy-29] [trace.py:128] - Task tasks.batch_clean_document_task.batch_clean_document_task[4942f6fd-e5e3-4e5d-bce9-0c1c6eaaf9b3] succeeded in 0.03778155901818536s: None
この中には
- 単純に処理が開始され、完了したケース
- 失敗したインデックスに対するリトライあるいはインデックス化の再実行を行い、無事完了したケース
- 処理完了後のタスククリーン処理
が含まれています。例えば再度リトライを実行するものの、うまく処理がリトライできない場合がありますけれども、その場合はファイルを再投入して実行させることがあります。この時、全部を一気に処理することはせずに、重複した・成功した文書については処理をスキップしていくことが確認できています。
そして最終的に運ばれる記録先であるWeaviateに登録をされると以下のようなログが出力されます。Weaviateもまた、その探索方法にHNSW(Hierarchical Navigable Small Worlds: 詳細は「GPTチャットボットの賢さを引き上げる試み」にて)を使用していることがそのログの内容から見て分かります。この根本的な方針などについては、2年経過してもあまり変わってないですね。評価値はコサイン近似を使用しているようです。
Jun 25 22:17:41 ******************* 8ac03ff1276c[1292]: {"action":"hnsw_condensing_complete","build_git_commit":"9069628","build_go_version":"go1.22.10","build_image_tag":"v1.28.0","build_wv_version":"1.28.0","level":"info","msg":"completed hnsw condensing","time":"2025-06-25T13:17:41Z"}
片や、PostgreSQLを使用する構成DB側には成功時はログ出力がなかったんですが、キーのDuplicate等の事由によりエラーが出力されている場合は記録が残っていました。以下のケースについては、どうやら「処理が一度失敗したと誤認し、再試行(リトライ)した結果、成功していた最初のデータと重複した。」という事のようです。
Jun 25 22:17:49 ************************* be89a6bb3f18[1292]: 2025-06-25 13:17:49.203 UTC [674709] ERROR: duplicate key value violates unique constraint "embedding_hash_idx"
Jun 25 22:17:49 ************************* be89a6bb3f18[1292]: 2025-06-25 13:17:49.203 UTC [674709] DETAIL: Key (model_name, hash, provider_name)=(snowflake-arctic-embed-l-v2.0-unicorn, 04ae193d6b13546cb7b536ec559da9094d8af3ffaac93358ec1594e612a5e7b3, langgenius/openai_api_compatible/openai_api_compatible) already exists.
Jun 25 22:17:49************************* be89a6bb3f18[1292]: 2025-06-25 13:17:49.203 UTC [674709] STATEMENT: INSERT INTO embeddings (model_name, hash, embedding, provider_name) VALUES ('snowflake-arctic-embed-l-v2.0-unicorn', '04ae19...9d14652e'::bytea, 'langgenius/openai_api_compatible/openai_api_compatible') RETURNING embeddings.id, embeddings.created_at
このように、Dockerコンテナのログ、あるいはDockerデーモン側でsyslogへの転送などを設定しておくとその処理の流れを確認することができますので、Dockerを使用している人はぜひぜひ。
学んだ教訓と注意点
巨大ファイル一括投入は悪手
最初、全RFCを単一ファイルにまとめて処理しようとしました。そして見事に失敗しました。
以下のような問題が起きました。
問題点:
- Plugin_daemonに長時間ジョブを実行させたことで、応答できないPlugin_daemonが出来てしまった。
- 当方の環境は、Docker-Compose環境でコンテナをスケーリングして動かしている(Kubernetesで言うReplicaSetと同等のことができるのです)。
- この時はPlugin_daemonを5個体制で動かしている。(応答性能引き上げ、Pythonスクリプトの並列実行を行うため)
- Dockerのラウンドロビン名前解決により、処理中のPlugin_daemonにジョブが振られると待機時間が発生
- 例えば別のWebAppを使用している人の一部に、「いつまでも応答が返ってこない」という問題が発生した。
- 個々のPlugin_daemon内のプラグインに対する同時処理数は1であるようで、他の処理がキューイング状態になるということを理解してなかった・・
- 具体的には、Azure OpenAI Plugin内の[text-embedding-3-small]をこの時は採用しようとしたんですが、処理してる間 Azure OpenAI Pluginで設定している内容を開くことができなくなりました。LLM応答も停滞していました。
- ところが、違うセッションにおいてはこのプラグインに触れることができました。どうやらこの時は違うPlugin_daemonへアクセスしてたようです。
- そして、情報量が多すぎてPlugin_daemonの処理が破綻し、エラー終了した。
解決策:
ファイルを個別に投入するほうが上策です。複数のPlugin_daemonに負荷分散され、システム全体のスループットが向上したうえ、他のWebAppのリクエストにも柔軟に対応ができるようになりました。
つまりは、Dify全般に言えることなんですが、どうやらPlugin_daemonというコンポーネントは小さなジョブをコツコツ処理させることに意義があるようです。そう考えると、Whisperであまりに長いジョブを処理させるというのはなかなかに厳しい処理なのかもしれません。
途中でデータを削除しないこと
インデックス処理中のデータ削除は厳禁です。
APIコンテナからWorkerコンテナにジョブを送る際、APIは全データを一気に送信し、Workerは全ファイルリストを抱え込みます。途中でファイルが消えると、Difyはステータス報告なしに「ファイルがない」とログに記録し、インデックス処理が停止します。画面上で「ファイルがないからエラー」として次の件にうつってくれればいいのですが、「インデックス化中」のままステータスが動かなくなってしまうので、docker logsコマンドで確認するまでこの状況は分からないままでした。
対策: 必ず全処理完了後にデータ整理を行うか、緊急時はナレッジ全体を削除してください。
リソースは「相当巨大に確保」が必要
親子チャンクの最大の弱点は、ベクトルDBが爆発的に大きくなることです。
データ肥大化の実態:
- 1つの親チャンクに対して20〜50個の子チャンクが生成
- ベクトルデータは
float32形式の1,024個の配列 - 原文テキスト量の40倍〜100倍のデータ量に膨張
実際の結果は下表のとおりです。処理の並列度や処理データの負荷などを考慮した結果、結局3部構成になりました。
| RFC-0001-4000 | 3,903 | 187,287k | 17G |
| RFC-4001-7000 | 2,917 | 171,784k | 15G |
| RFC-7001-9999 | 2,762 | 161,206k | 15G |
| 計 | 9,582 | 520,277 | 47G |
私自身、色んな文書やデータをRAG用途にこのDifyへ突っ込んできましたけど、これだけたくさんの単語を登録したものは見たことがありません。(それまで最も多くの語彙を持ったデータとしてはPostgreSQL v15 Documentsの全文でしたが、それでも単語数は1,200万単語ぐらいでした。)
そして実際にはこのベクトルDB情報は構成DBであるPostgreSQLコンテナにも乗っかってきます。そのため当然のことなのですがPostgreSQLコンテナのストレージ使用量及びメモリ使用量も一気に上昇しました。
 上図の6/24より処理を開始しましたが、当初は単一ファイルで処理させようとしたり、周辺システムのキャパシティが低くて処理に失敗したりを繰り返しており、ちゃんと投入できるようになったのが6/25の09:00前後ぐらいだったかと思います。そこから急激に上昇しているところがデータ投入を行っている時間帯です。ちょうど同日23時頃に処理が完了し、それ以降は徐々にメモリ使用量が下がってきていることが分かるかと思います。
上図の6/24より処理を開始しましたが、当初は単一ファイルで処理させようとしたり、周辺システムのキャパシティが低くて処理に失敗したりを繰り返しており、ちゃんと投入できるようになったのが6/25の09:00前後ぐらいだったかと思います。そこから急激に上昇しているところがデータ投入を行っている時間帯です。ちょうど同日23時頃に処理が完了し、それ以降は徐々にメモリ使用量が下がってきていることが分かるかと思います。
故に、Dify Communityに触れる方々は、非常に大規模なデータを投入する際はこのあたりのリソース消費はたとえスパイク的であろうと考慮をする必要が出てくるかと思います。テナント領域の情報量は、投入前の3-4倍程度に膨れ上がり、バックアップ処理の見直しなども必要になってしまいました(とほほ)
メモリ使用量のピーク:
- Weaviateコンテナ:61.08GB
- PostgreSQLコンテナ:34.33GB
- Difyコンテナ群全体のメモリ使用量:最大128GB
驚異的な検索パフォーマンス
これだけの巨大データにもかかわらず、現時点でのknowledge-retrievalタスクの平均応答時間は3.83秒です。
おおよそ3秒~4秒程度の時間でデータが取得できてることを確認出来ました。(この確認はLangfuseというツールを用いています。)
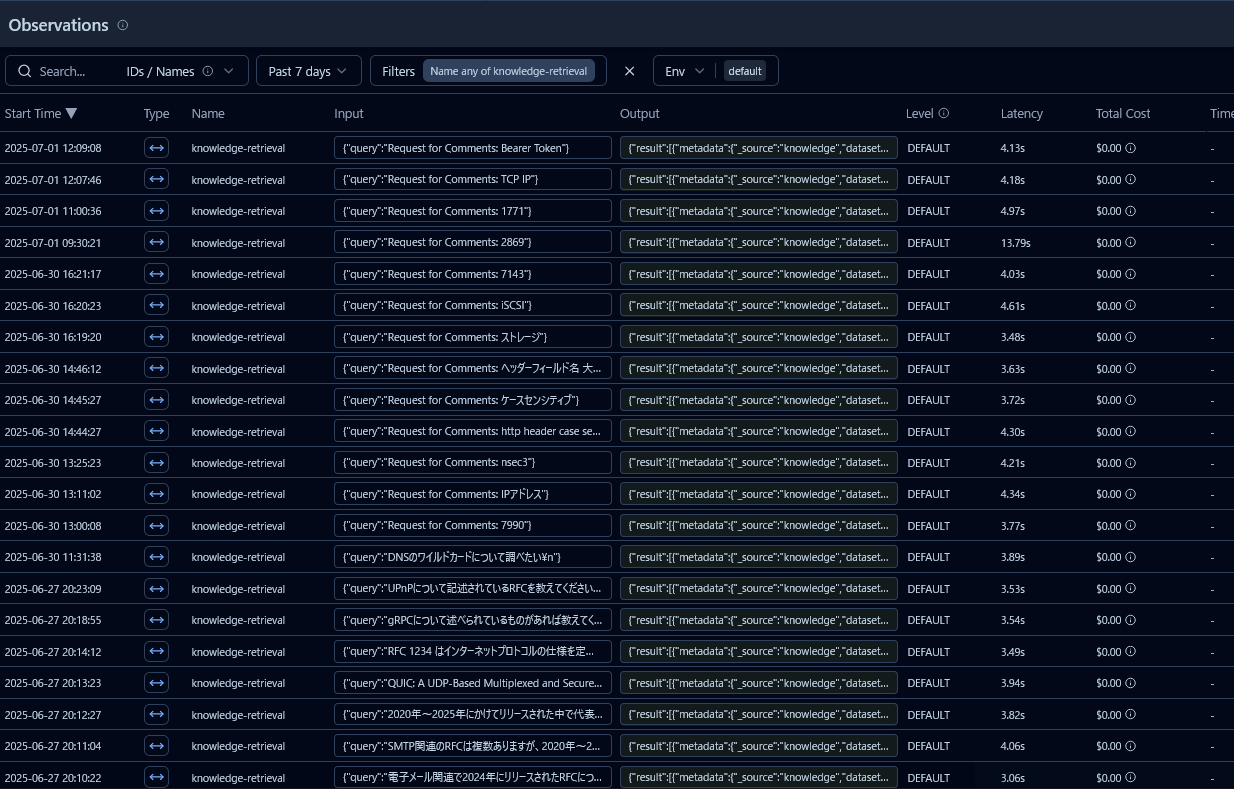
大きな要因の一つには、ローカルSLMを使用したことが大きいかなと感じています。リクエストの平均は以下の通りとなりました。
- リクエスト平均時間: 0.0388sec
リクエスト回数は全量で凡そ3,300,000リクエストであり、それらのリクエストはいずれもステータス200で応答できていました。
低遅延かつQuota知らずで動かしてることで、途中で応答不能になるような状況が発生しにくかったことが挙げられるのかなと私は考えています。
また、選んだ Snowflake-arctic-embed-l-v2の能力の高さも挙げられるのだろうと思っています。正直今回DB容量が50GB近くまで大きくなることはあまり予想していませんでした。これがもしAzureOpenAIで提供される text-embedding-3-large などでしたら容量が3倍となり、メモリも収容が難しくなった可能性があります。サイズ1.5倍のtext-embedding-3-small でさえ少々厳しかったのかもしれません。
低遅延で処理できる環境であるローカルEmbeddingモデル環境があること、低次元出力ながらコンテキスト長が非常に長く性能の高いEmbeddingモデルを選定できたことで、このような巨大ナレッジを組み上げることができたのかなと思います。
実用性の検証
構築したナレッジベースを使用してQAボットを作成し、実際の有効性を検証中です。
- ベクトル検索ワークフロー(GPT-4.1-mini使用)
- RFC回答チャットボット(Gemini 2.5 Flash使用、ワークフローをツールとしてエージェントから利用)
今回、左側のワークフローツール、右側のチャットフローツールの2部構成となっています。
左側のワークフローツールは以下の構造となっており、単純に知識検索を行い、その情報を整理するだけの処理となっています。

LLMには遂行能力としてちゃんとその趣旨を返すことを重要視するOpenAI GPT-4.1-miniを採用しています。
そしてこの呼び出し元となるチャットフローの構造が以下の通りです。

前段にエージェントノードがあり、ここでワークフローをツールとして動かします。後段にあるLLMノードは内容を取りまとめるだけの存在とし、それぞれに使用するモデルはGemini 2.5 Flashを使用しています。これは、Gemini 2.5 Proを使用すると回答に時間がかかりすぎてしまうためです。
この構造にしたのは、知識検索を行う際、「いい答えが見つかるまで検索クエリを弄りながら繰り返し問い合わせる」ということをさせたかったからです。ベクトル検索処理だけ外に出し、ワークフローを構成することによって、それをツール化してエージェントへの組み込みを可能としています。
以下は応答例の一部です。
- 応答例①:応答完了時間: 32.32sec
- Q:DNSのワイルドカードについて調べたい
- A:DNSのワイルドカードに関しては、以下のような規定や利用例があります。
**基本的なルールと構文** *
ワイルドカード文字「*」は、DNS-IDやCN-IDにおいて、最初のラベル全体でなければなりません。
例えば、「*.example.com」は有効ですが、「smtp*.example.com」や「*smtp.example.com」は有効ではありません。(RFC 7672)
* SMTPクライアントは、参照識別子の最初のラベルに一致するワイルドカードをサポートする必要があります。例えば、DNS-ID「*.example.com」は参照識別子「mx1.example.com」と一致します。(RFC 7672)
**ワイルドカード証明書のチェック (RFC 6125)**
クライアントがワイルドカード証明書をチェックする際には、以下のルールが適用されます。
1. ワイルドカード文字が左端以外のラベルを構成する識別子(例: bar.*.example.net)とは照合すべきではありません。
2. ワイルドカード文字が左端ラベルの唯一の文字である場合(例: *.exam……
- 応答例②:応答完了時間: 26.81sec
- Q:NFSv3について取り扱われているRFCドキュメントについて教えてください
- A:NFSv3について取り扱われているRFCドキュメントは、RFC 1813です。
このドキュメントは「NFS Version 3 Protocol Specification」として知られ、NFSv3のプロトコル仕様を定義しています。
まとめ
今回の挑戦を通じて、以下の重要な知見を得ました:
- 親子チャンクは高精度だが、リソース消費が膨大
- ファイル分割による並列処理が効果的
- 処理中のデータ削除は絶対に避ける
- 適切な設定により、巨大データでも高速検索が可能
親子チャンクという技術は、検索精度向上の強力な手法ですが、その代償としてリソース消費量が劇的に増加します。しかし、適切なインフラと設定があれば、登録単語数500M(5億)超のRFCドキュメントという巨大なナレッジベースでも、実用的な検索性能を実現できることが確認できました。
これは私個人の考えですが、Difyを触り始めた最大の要因はこうしたナレッジ作成機能、ナレッジ管理機能の作りがしっかりしている点が挙げられます。似たような仕組みをPythonベースであれこれ試行錯誤してたことはあります。それこそ「キャラクター付けを目的としたファインチューニング」にて記述した、Llama-Indexに関してはその中でも一番取り組んだものだったりしますが、そうした苦労を吹き飛ばすぐらいの威力がDifyにあり、そこから徐々に扱う範囲を広げて今に至ります。
他のプロダクトと連携させてみたり、或いはWebAppではなくDify-APIを通じて間接的に利用する仕組みを研究してみたりなど様々なことを行っていますが、今回のケースについてはそれらとは全く異なる観点において、ものすごく貴重なケースだったなぁと、検証を終えた後も新たな発見が沢山出てきたような、そんな印象の強い検証でありました。
大規模ナレッジベース構築に挑戦する皆さんの参考になれば幸いです。