文字起こしAI Whisperモデルの更なる活用形 ~ 「負の遺産」とならないために
2025年03月18日 火曜日

CONTENTS
書き起こしツール「月読」という社内ツール
OpenAI Whisper に追加学習をさせる試みという記事を書いてから気づけば2年と2か月ちょっとが経過したようです。
この時作成した社内向け議事書き起こしツール「月読」というツールがあります。現在もぼちぼち稼働しています。
多分色んな界隈でこの天津神の名称は使われているかと思うのですが、こちら、一切そうしたところとは関連ございませんで、予めご了承ください。
コンセプトとしては、ICレコーダーで聞き返しても聞き取りづらい言葉を、月明かりに照らすぐらいには読みやすくしてくれるツールという意味合いがあって、ゼロからつけた名称になります。当初は目が光る怖い人の顔だったのを、さすがに不気味すぎるということで差し替えたのが今のロゴになっています。初期の頃の月読ロゴ

SlurmはGPU排他制御で必要になってくるもので、これによりそれぞれ実行された履歴はジョブとして管理することができる点がうれしいポイントです。
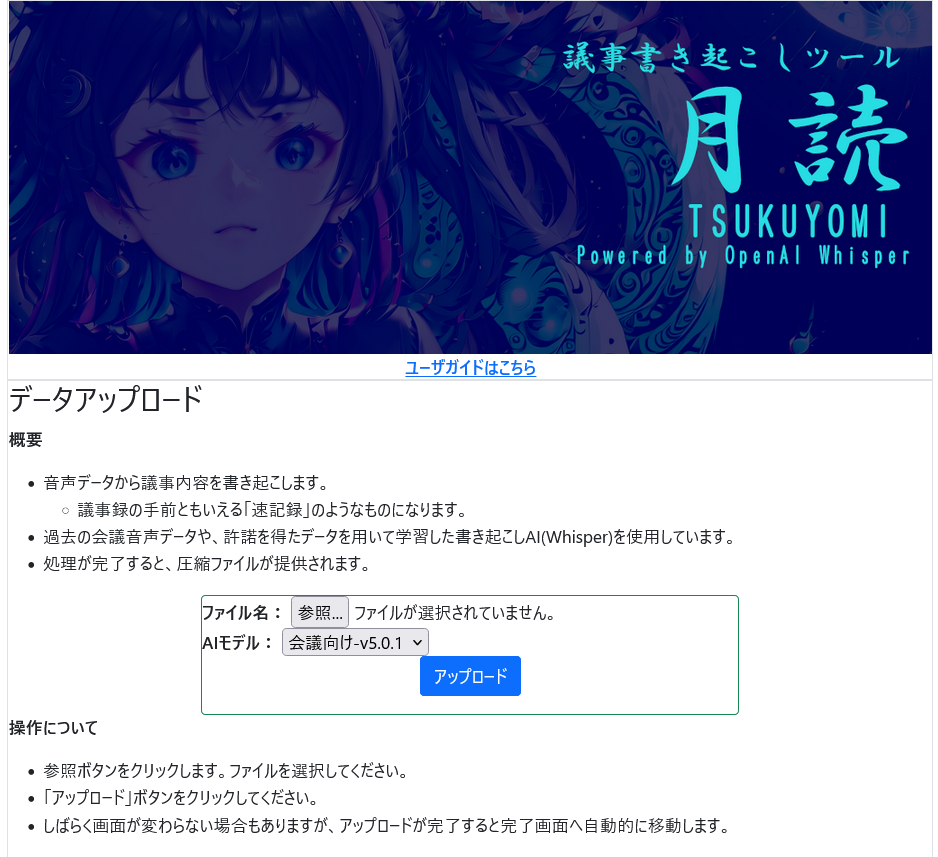
現在の月読のインタフェース画面
内部で動作するモデルはOpenAI/Whisperです。Whisperがリリースされたときは大変な盛り上がりを見せてたなぁというのをいまだ覚えてまして、このモデルに私もかじりついて一生懸命内部構造を調べてたりしたなーと。
今やすっかりクローズなイメージが固定してしまったOpenAIですが、当時はその境目の時代ということもあり、DALL-E2で使われてたCLIPや書き起こしモデルWhisperはオープンモデルとして、かの有名なGPT-3や画像生成モデル本体であるDALL-E2はクローズドモデルとして道を分かれた時期でもありました。
早速これをいち早く取り込んで社内業務を少しでも楽にしよう!と言いながら作ったものの、なかなか当時AIに懐疑的な人が多い中で受け入れられず。色々藻掻いてました。一度試して「ふーん」で終わったり、楽であっても「楽するのは●●」みたいな論調があってその後リピーターが来なかったり。結局ちゃんと使ってる人って私自身か、ごくまれに数名の興味を持った人の一回きりの実行ぐらいなもんで、「私、いったい何のためにこれ作ったんかな?」とか思ったり。
Whisper-Large-v3モデルがリリースされたときにも、そのリリースされたモデルをベースにファインチューニングをせっせと行って淡々と実装しましたけれど、心の奥底ではいつこのシステムを廃止してしまおうかって割と悩んでました。
そんな日陰者のこのツールが社内にそれなりに知られるようになったのは昨年10月ごろからで、とある事業部の中でそこそこ活用される時期がありまして。
特に社内用語に対してそれなりの品質を保てる書き起こしができるということで、単なる議事録作成用のツールとしてのみならず、プレゼン評価をする際のツールとしても活用されたようです。
今となっては「癖ツヨ」ツールでもある「月読」
さて、この「月読」なんですけど、私がまだHuggingfaceという便利サイトとTransformersという便利ライブラリの存在を知らない頃に、たまたま見たブログのサンプルプログラムなどを見ながらベタにOpenAI製のWhisperライブラリとPytorch Lightningを使って作り上げた代物です。
まずはベースモデルとなっているWhisper-large-v3のおさらいから。
そのアーキテクチャは純粋にTransformerをベースとして作られてます。それ故にDecoderオンリーのGPTシリーズと違い、ちゃんとEncoderが備わっています。
当時のモデルサイズとしては比較的大きかったようにも思いますが、今となっては非常に小さいモデルに分類される1.54Bパラメータで構成されています。
v3のリリースと共に、パラメータのデータ型やメルスペクトログラムのチャネル数を変更しており、v3登場当初、だいぶこの辺りの仕様の変化に慌てた記憶があります。

私が現在このツールに対して提供する最新となるモデルには、以下のような独自コーパスを使用してファインチューニングを施しています。
- 音声データは以下2種類を使用
- 株式会社Laboro.AIさんが無償公開しているLaboro-ASVという音声データ集から5,965件(v4.0から)
- このデータが日本語文法としてより自然になるよう品質を向上させる役割を持ってます。
- 過去に当社内で行われたいくつかのミーティング録音データから1,027件(v1.00から)
- このデータが社内の独特な専門用語を認識させるための辞書的な役割を持っています。
- 株式会社Laboro.AIさんが無償公開しているLaboro-ASVという音声データ集から5,965件(v4.0から)
- 対応するテキストはまず、従来モデル(今使ってるモデルの過去バージョン)を使用して一次書き起こしを、続いて人間の手を借りて修正(二次書き起こし)して対応付けさせています。
- 社内文書のコーパス作成は私自身が手掛けますが、Laboro-ASVのコーパス作成は私以外の2人の仲間の手を借りて1か月ほどの間、合間合間で時間を作りながら徐々に作り上げていったコーパスデータを用いています。
- ファインチューニングに使用したGPUはNVIDIA Tesla P100(VRAM16GB)を使用
- 5epochs(およそ30,000ステップ)学習実行。学習時間は凡そ2日間ぐらい。
- 音声区間は30秒固定
コーパスデータにそれなりの社内用語を含んでいますので、そうした固有名詞にきちんと反応できる点がウリです。
ですが、いかんせんAI始めた頃でしたので、見様見真似で取り組んで作り上げ、その後、DeepLearningの知識理解を深めていくにつれて徐々に仕組みを変えながら更新してきた者であったので、精度は上がってくれたんですが、とにかく今のトレンド技術に対する互換性が皆無というなかなか癖強々な作りになってしまいました。
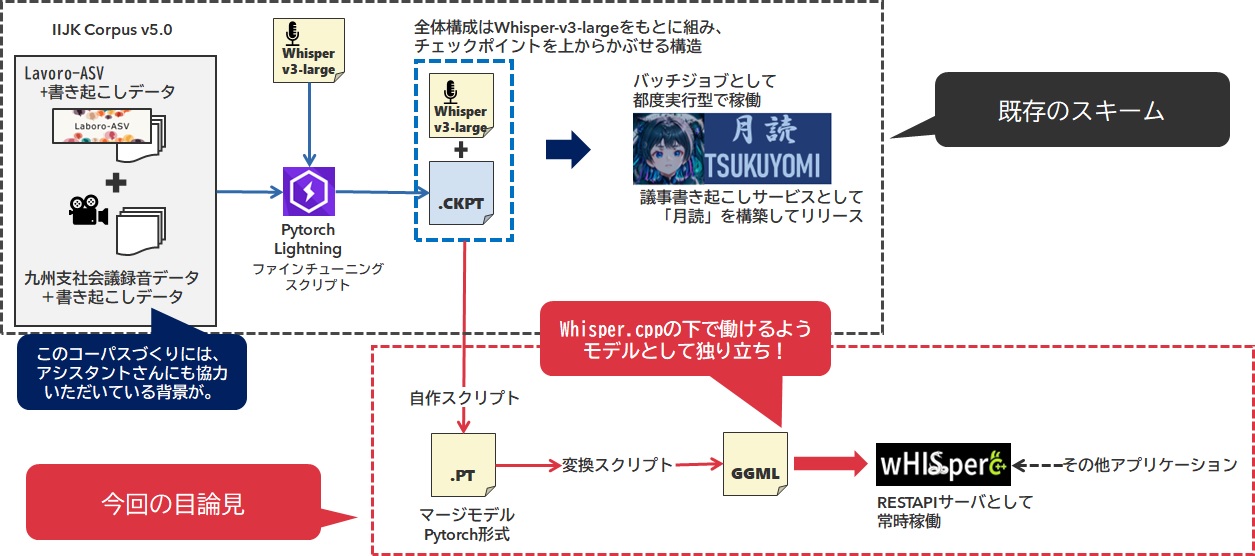
それ故に、Huggingfaceから得られるモデルとは互換性もなく(ベースモデル自体がOpenAIから直接供給されてるもの)、どうやったらこのトレンドとなっている技術スタックに載せられるのか、他のプロダクトに載せられるのかもよくわからないまま2年2か月の時が過ぎたわけです。このままだと、本当に「これしかできない」って感じのツールになり下がりかねない・・そんな危機感から今回モデルの他形式変換に挑むことにしたのです。
今回のゴール設定
狙った目標としては以下の通りです。
- 現在の「月読」は完全にバッチ型でしか動作しないので、llama.cppのように常駐型プロセス上に実装し、REST API化させたい
- 現在同時にDifyについても取り組み始めているので、これと連携できるようにしたい。モデルプロバイダとして実装できるのがベスト。
- なお、余談ではあるんですが同じく九州支社の末よりこの辺りの話をまとめた記事が https://www.itmedia.co.jp/aiplus/articles/2503/14/news062.html にて公開されてましたのでリンクを併せて貼っておきます。
丁度、llama.cppについて過去かなり調べていたこともあり、今回常駐プロセスとして動かすためのエンジンとして、llama.cppの作者が作ったWhisper向けサーバを実行可能な「Whisper.cpp」をその実装先として選定しました。現在はもっと進んだサーバソフトウェアもあるようなのですが、仕組みの理解をまずは優先させました。
常駐プロセスとして動かすための土台作り
Whisper.cppをビルドする
Whisper.cppのビルドですが、リポジトリは https://github.com/ggerganov/whisper.cpp にあります。ここからgit cloneコマンドを用いてクローンを作成し、其処へカレントディレクトリを映したうえで以下のようにCUDAを有効化する引数をもってビルドすることで、各種バイナリファイル含めて作成ができます。
cmake -B build -DGGML_CUDA=1 cmake --build build -j --config Release
この時、事前にCUDA Toolkitをインストールすることをお忘れなく。
うまく構築できますと、以下のように build/bin 配下にアプリケーションが構築できます。今回主に使うアプリケーションはこの中の
- whisper-cli
- whisper-server
- quantize
の3つですね。
aiuser@bdae02:~/whisper.cpp/build/bin$ ls -al total 1560 drwxrwxr-x 2 aiuser aiuser 4096 Feb 23 11:06 . drwxrwxr-x 7 aiuser aiuser 4096 Feb 23 11:01 .. -rwxrwxr-x 1 aiuser aiuser 17384 Feb 23 11:02 bench -rwxrwxr-x 1 aiuser aiuser 17384 Feb 23 11:02 command -rwxrwxr-x 1 aiuser aiuser 17384 Feb 23 11:02 main -rwxrwxr-x 1 aiuser aiuser 205152 Feb 23 11:06 quantize -rwxrwxr-x 1 aiuser aiuser 17384 Feb 23 11:02 stream -rwxrwxr-x 1 aiuser aiuser 26176 Feb 23 11:06 whisper-bench -rwxrwxr-x 1 aiuser aiuser 489288 Feb 23 11:06 whisper-cli -rwxrwxr-x 1 aiuser aiuser 774888 Feb 23 11:06 whisper-server
チェックポイントファイルを変換する
まずは.ckptから.ptへ、無駄をそぎ落とす
実はこの「月読」なんですが、チェックポイントデータをそのままモデルとして適用して利用しています。
そのため、推論時は以下の手順を踏んで推論可能な状態にして、書き起こし処理をするようになっています。
- Whisperライブラリから、WhisperModelModuleというクラスを作る。
- その中でwhisper.load_modelを呼び出してバニラモデルを作成する(今回はlarge-v3)
- バニラモデルをCPU上に展開する
- チェックポイントデータから、state_dictを呼び出す
- 呼び出したState_dictをバニラモデルに上被せする
- GPUへ移動させ、推論モードへ切り替え、torch.compileをして推論処理を開始する
チェックポイントデータの中にはチェックポイント状態というデータも含まれており、これが非常に無駄ですので、この推論の処理を流用して純粋なState_Dictのファイルを構成することにしました。これがいわゆる純粋なモデルデータってやつですね。
#ライブラリのインポート
from pathlib import Path
import os
import sys
import numpy as np
import torch
from torch import nn
import whisper
from lightning.pytorch import LightningModule
from lightning.pytorch import seed_everything
import argparse
import json
import datetime
# 定数の定義
SEED = 3407
# ディレクトリの定義
LOGDIR = "/var/log/whisper/"
CHKPOINTDIR = "/home/aiuser/whisper/whisper-data/content/artifacts/checkpoint/"
DATADIR = "/home/aiuser/whisper/whisper-data/"
# モデルの配置先はまずCPUにセットするため、元の記述はコメントアウトする。
DEVICE = "cpu"
seed_everything(SEED, workers=True)
parser=argparse.ArgumentParser(description="Transition learning scripts using OpenAI Whisper.")
parser.add_argument('-m','--model',dest="model",help='Checkpointの指定',type=str,required)
parser.add_argument('-b','--basemodel',dest="base",help='Whisperベースモデルの指定',type=str,default="large-v3")
parser.add_argument('-o','--output_model',dest="output",help='出力モデルデータの指定',type=str,default="./merged.pt")
args=parser.parse_args()
#Whisper ModelのpytorchLightning用モジュール。使用しない関数は削除。
class WhisperModelModule(LightningModule):
def __init__(self, model_name="large-v1", lang="ja", train_dataset=[], eval_dataset=[]) -> None:
super().__init__()
# モデルやトークナイザーの設定です。
self.options = whisper.DecodingOptions(language="ja", without_timestamps=True)
self.model = whisper.load_model(model_name)
self.tokenizer = whisper.tokenizer.get_tokenizer(True, language="ja", task=self.options.task)
#標準出力にログ出力をする
def log_stdout(msg_txt):
dt_now = datetime.datetime.now()
print(str(dt_now.strftime('%Y-%m-%d %H:%M:%S')) + " " +msg_txt)
def main():
#チェックポイント及び内容のロード(weightとbias)
#まずはDRAM上に呼び出し、CPU上の処理でモデルに書き込めるようにする。
if args.model != "":
checkpoint_path = CHKPOINTDIR + args.model
state_dict = torch.load(checkpoint_path,map_location='cpu')
state_dict = state_dict['state_dict']
log_stdout("ckpt data loaded.")
else:
log_stdout("no selected add-on model. use vanilla large model.")
log_stdout("merge_model :" + args.output)
#重みデータを載せるためのベースとなるWhisperベースモデルを作成する
#この時点では、CPU上にモデルを構築・配置をする。
log_stdout("Start Recreate WhisperModelModule.")
whisper_model = WhisperModelModule(model_name=args.base)
#事前にロードした重み情報(チェックポイント上の)をモデルに上書きする
if args.model != "":
log_stdout("Base model created. Start load state_dict..")
whisper_model.load_state_dict(state_dict)
#モデルを推論モードに切り替える
whisper_model.eval()
log_stdout("Complete locked all parameters.")
#モデルをコンパイルします。
whisper_model = torch.compile(whisper_model)
log_stdout("Complete compiled all parameters.")
#モデルを保存する
torch.save(whisper_model.state_dict(),args.output)
log_stdout("Complete saved all parameters.")
if __name__=="__main__":main()
プログラムを動かしてプログラムを実行します。書式は以下の通りとなります。
python merge_model.py -m <チェックポイントファイル名>.ckpt -b large-v3 -o ./<変換後のファイル名>.pt
これをさらに、常駐型プロセスとして動かすwhisper.cpp用に加工します。
.ptファイルをGGML形式へ
whisper.cppは、バイナリに変換したモデルファイルであるGGML形式のファイルを使用します。
GGML形式に変換することにより、ある意味月読モデルは「独り立ち」する形になります。それ自体でモデルとして必要な要素を含んだ状態になるためそう形容しました。なお、llama.cppではこのフォーマットをさらに進化させたGGUF形式のファイルを使用することがメジャーになっています。
ところが困ったことに、この変換を行う convert-pt-to-ggml.py スクリプトがうまく動作しないことに気づきまして。
参考にしたのは GitHubのwhisper.cppリポジトリ内、Discussions上のスレッドになります。
Convert pt with a fine-tuned state_dict
https://github.com/ggerganov/whisper.cpp/discussions/2117
やってる内容は以下の通りです。
- チェックポイントから取り出したパラメータ名に、余計なPrefixがついているのでこれを除去する処理
- 全てをfloat16にするのではなく、float32とすべきパラメータはfloat32のままとする処理
加えて、ハイパーパラメータが取得できない状況も見受けられたため、今回実行するのは large-v3 前提とするところもあり、これを固定的に割り当てる処理を加えました。結果、以下のようなコードになります(余計な行は削除しました。ハイライト表示している箇所が改修個所です。)
# Convert Whisper transformer model from PyTorch to ggml format
#
# Usage: python convert-pt-to-ggml.py ~/.cache/whisper/medium.pt ~/path/to/repo/whisper/ ./models/whisper-medium
#
# You need to clone the original repo in ~/path/to/repo/whisper/
#
# git clone https://github.com/openai/whisper ~/path/to/repo/whisper/
#
# - hparams
# - mel filters
# - tokenizer vocab
# - model variables
#
# For each variable, write the following:
#
# - Number of dimensions (int)
# - Name length (int)
# - Dimensions (int[n_dims])
# - Name (char[name_length])
# - Data (float[n_dims])
#
import io
import os
import sys
import struct
import json
import code
import torch
import numpy as np
import base64
from pathlib import Path
def bytes_to_unicode():
"""
Returns list of utf-8 byte and a corresponding list of unicode strings.
The reversible bpe codes work on unicode strings.
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
This is a signficant percentage of your normal, say, 32K bpe vocab.
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
And avoids mapping to whitespace/control characters the bpe code barfs on.
"""
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("!"), ord("¬")+1))+list(range(ord("R"), ord("y")+1))
cs = bs[:]
n = 0
for b in range(2**8):
if b not in bs:
bs.append(b)
cs.append(2**8+n)
n += 1
cs = [chr(n) for n in cs]
return dict(zip(bs, cs))
if len(sys.argv) < 4:
print("Usage: convert-pt-to-ggml.py model.pt path-to-whisper-repo dir-output [use-f32]\n")
sys.exit(1)
fname_inp = Path(sys.argv[1])
dir_whisper = Path(sys.argv[2])
dir_out = Path(sys.argv[3])
try:
model_bytes = open(fname_inp, "rb").read()
with io.BytesIO(model_bytes) as fp:
checkpoint = torch.load(fp, map_location="cpu")
except Exception:
print("Error: failed to load PyTorch model file:" , fname_inp)
sys.exit(1)
#hparams = checkpoint["dims"]
hparams = {
'n_mels': 128,
'n_vocab': 51866,
'n_audio_ctx': 1500,
'n_audio_state': 1280,
'n_audio_head': 20,
'n_audio_layer': 32,
'n_text_ctx': 448,
'n_text_state': 1280,
'n_text_head': 20,
'n_text_layer': 32
}
print("hparams:", hparams)
new_state_dict = {k.partition('model.')[2]: v for k,v in checkpoint.items()}
checkpoint["model_state_dict"] = new_state_dict
list_vars = checkpoint["model_state_dict"]
# load mel filters
n_mels = hparams["n_mels"]
with np.load(dir_whisper / "whisper" / "assets" / "mel_filters.npz") as f:
filters = torch.from_numpy(f[f"mel_{n_mels}"])
multilingual = hparams["n_vocab"] >= 51865
tokenizer = dir_whisper / "whisper" / "assets" / (multilingual and "multilingual.tiktoken" or "gpt2.tiktoken")
tokenizer_type = "tiktoken"
if not tokenizer.is_file():
tokenizer = dir_whisper / "whisper" / "assets" / (multilingual and "multilingual" or "gpt2") / "vocab.json"
tokenizer_type = "hf_transformers"
if not tokenizer.is_file():
print("Error: failed to find either tiktoken or hf_transformers tokenizer file:", tokenizer)
sys.exit(1)
byte_encoder = bytes_to_unicode()
byte_decoder = {v:k for k, v in byte_encoder.items()}
if tokenizer_type == "tiktoken":
with open(tokenizer, "rb") as f:
contents = f.read()
tokens = {base64.b64decode(token): int(rank) for token, rank in (line.split() for line in contents.splitlines() if line)}
elif tokenizer_type == "hf_transformers":
with open(tokenizer, "r", encoding="utf8") as f:
_tokens_raw = json.load(f)
if '<|endoftext|>' in _tokens_raw:
# ensures exact same model as tokenizer_type == tiktoken
# details: https://github.com/ggerganov/whisper.cpp/pull/725
del _tokens_raw['<|endoftext|>']
tokens = {bytes([byte_decoder[c] for c in token]): int(idx) for token, idx in _tokens_raw.items()}
# output in the same directory as the model
fname_out = dir_out / "ggml-model.bin"
# use 16-bit or 32-bit floats
use_f16 = True
if len(sys.argv) > 4:
use_f16 = False
fname_out = dir_out / "ggml-model-f32.bin"
fout = fname_out.open("wb")
fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex
fout.write(struct.pack("i", hparams["n_vocab"]))
fout.write(struct.pack("i", hparams["n_audio_ctx"]))
fout.write(struct.pack("i", hparams["n_audio_state"]))
fout.write(struct.pack("i", hparams["n_audio_head"]))
fout.write(struct.pack("i", hparams["n_audio_layer"]))
fout.write(struct.pack("i", hparams["n_text_ctx"]))
fout.write(struct.pack("i", hparams["n_text_state"]))
fout.write(struct.pack("i", hparams["n_text_head"]))
fout.write(struct.pack("i", hparams["n_text_layer"]))
fout.write(struct.pack("i", hparams["n_mels"]))
fout.write(struct.pack("i", use_f16))
# write mel filters
fout.write(struct.pack("i", filters.shape[0]))
fout.write(struct.pack("i", filters.shape[1]))
for i in range(filters.shape[0]):
for j in range(filters.shape[1]):
fout.write(struct.pack("f", filters[i][j]))
# write tokenizer
fout.write(struct.pack("i", len(tokens)))
for key in tokens:
fout.write(struct.pack("i", len(key)))
fout.write(key)
for name in list_vars.keys():
data = list_vars[name].squeeze().numpy()
print("Processing variable: " , name , " with shape: ", data.shape)
# reshape conv bias from [n] to [n, 1]
if name in ["encoder.conv1.bias", "encoder.conv2.bias"]:
data = data.reshape(data.shape[0], 1)
print(f" Reshaped variable: {name} to shape: ", data.shape)
n_dims = len(data.shape)
if use_f16:
print("dtype is:", data.dtype)
if n_dims < 2 or \
name == "encoder.conv1.bias" or \
name == "encoder.conv2.bias" or \
name == "encoder.positional_embedding" or \
name == "decoder.positional_embedding":
print(" Converting to float32")
data = data.astype(np.float32)
else:
print(" Converting to float16")
data = data.astype(np.float16)
if data.dtype == np.float16:
ftype = 1
else:
ftype = 0
else:
data = data.astype(np.float32)
ftype = 0
# header
str_ = name.encode('utf-8')
fout.write(struct.pack("iii", n_dims, len(str_), ftype))
for i in range(n_dims):
fout.write(struct.pack("i", data.shape[n_dims - 1 - i]))
fout.write(str_)
# data
data.tofile(fout)
fout.close()
print("Done. Output file: " , fname_out)
print("")
変換する際のコマンドとしては以下の通りになります。
python convert-pt-to-ggml.py <変換前の.pt ファイル> <GithubのWhisperリポジトリをCloneしてるディレクトリ> <出力先ディレクトリ>
2番目の引数で指定するディレクトリなのですが、本家のWhisperリポジトリ( https://github.com/openai/whisper )のクローンを git clone コマンドで作成頂き、そのディレクトリを指定する必要があります。出力先ディレクトリに置かれるファイルは固定名で設定されており、”ggml-model.bin”となります。そのままの名称で使ってもかまいませんし、必要に応じて名称を変えていただいてもよいかと思います。
私はよく「ggml-<コーパス名・バージョン>-<Whisperモデル名>.bin」という命名規則で名称を設定しています。
チェックポイントが凡そ6.2GiB程度のファイルだったのですが、ここまで変換が進むと凡そ3GiBちょっとぐらいのファイルになります。これで、Whisper.cpp上で動作できる所謂「独り立ちしたモデル」になります。
これを図にまとめると以下のような形となります。
whisper-serverを起動する
カレントディレクトリをwhisper.cpp に合わせた状態で
build/bin/whisper-server --host 0.0.0.0 --port <ポート番号> -m models/ggml-model.bin
としてコマンド実行をすると、Whisperモデルを実行するサーバが起動します。するとブラウザで http://xxx.xxx.xxx.xxx:yyyyy へアクセスすると以下のような画面が表示されます。
Webインタフェースの外観
Try it outのセクションにあるところでファイルをアップロードして、その他のフォームを設定して「Submit」をクリックするとしばらく待った後、以下のような画面に変わります。

書き起こし結果(FMラジオの録音データから。VTT形式)
他にも JSONドキュメント、純粋なテキストにも変換できます。
書き起こし速度はいかほどか?
書き起こし速度なんですが、以下環境で実行しました。
- CPUは6Core/12Thread のXeon-w3プロセッサ
- NVIDIA GeForce RTX 3060 / 12G を使用
- 書き起こしに使用したファイルはとある会議の収録をしたwavファイル:約57分程度(102MBytes)
それまでコードべた書きで推論させた処理が影響したのか、すべてデフォルト状態で行った場合ですと、従来方式の方が遅くなるということが分かりました。何もかもデフォルトですと下図の1行目にあるような結果、ほぼ25分程度かかることが確認できました。
プロセッサ数・スレッド数
ここで調整用パラメータとして登場するのが
- -p:プロセッサ数
- -t:スレッド数
という2つのパラメータです。一番動作に影響するのがプロセッサ数であり、こちらは音声ファイルをプロセッサ数として指定した数分だけ区間後区切り、それぞれにWhisperモデルを並行実行させて処理を行います。Whisperモデルを複数立ち上げる分、リソース消費量は元のプロセッサ数倍になります。
スレッド数はさらにその中の書き起こしタスク内における並列度を記述するものとなります。
モデルの量子化
こちらは最近ですとだいぶなじみ深いものになってきたかと思います。内部ベクトルのデータ型を低精度のものに変換させてモデルサイズ及びVRAM消費量を抑える方法です。こちらは、Whisper.cpp用のコマンドである quantize というコマンドを使用することで変換が可能です。
build/bin/quantize models/<モデル名> models/<量子化済みモデル名> q4_0
末尾に書いている「q4_0」というのが量子化のレベルになります。今回、精度維持限界のレベルである4bit量子化を指定しています。
これを実行することで、モデルサイズは 3GiB程度から849MiBぐらいまでに圧縮できます。モデル起動時のメモリ消費量は4GiB程度だったのが1.4GiBぐらいに抑えられます。計算時間もそれぞれで実行する処理が低精度となることで書き起こし速度は速くなります。上表にも記載していますが、凡そ書き起こし時間は2/3程度に低減します。
Flash Attention
Flash Attentionというのは、NVIDIA GPUにおけるAmpere世代以降のプロセッサに搭載されている機能で、Whisperに使われているTransformerというニューラルネットワークアーキテクチャのAttentionという層に対して行う計算処理回数のオーダーをnの二乗オーダーからnの1乗オーダーに削減する技術です。これにより、計算回数が大幅に削減され、処理速度の向上に役立ちます。
今回、GeForce RTX 3000番台や先頭に「A」とつくGPUはAmpere世代であることを示しており、RTX3060もAmpere世代ですのでこのスイッチが使えます。
whisper-serverの引数ヘルプには記述されてないんですが、ソースコードを眺めると実はこのオプションスイッチを扱っていることが分かりましたので、これを盛り込みます。具体的には –flash-attn というオプションスイッチを加えます。
高速処理設定を加えた結果
これまで説明した設定を加えた結果が以下の通りとなります。すべての設定を加えると、なんと処理時間が75%も削減できることが確認できました。
これでちょうど従来型のものですと、およそ15分弱ほどかかる処理になります。そちらの場合は前処理・後処理ががっつり入っていて、高速化につながるような処理が特に前処理で入っていたことが大きかったんですが、高速化設定を一通り入れるとかなり時間短縮ができそうです。
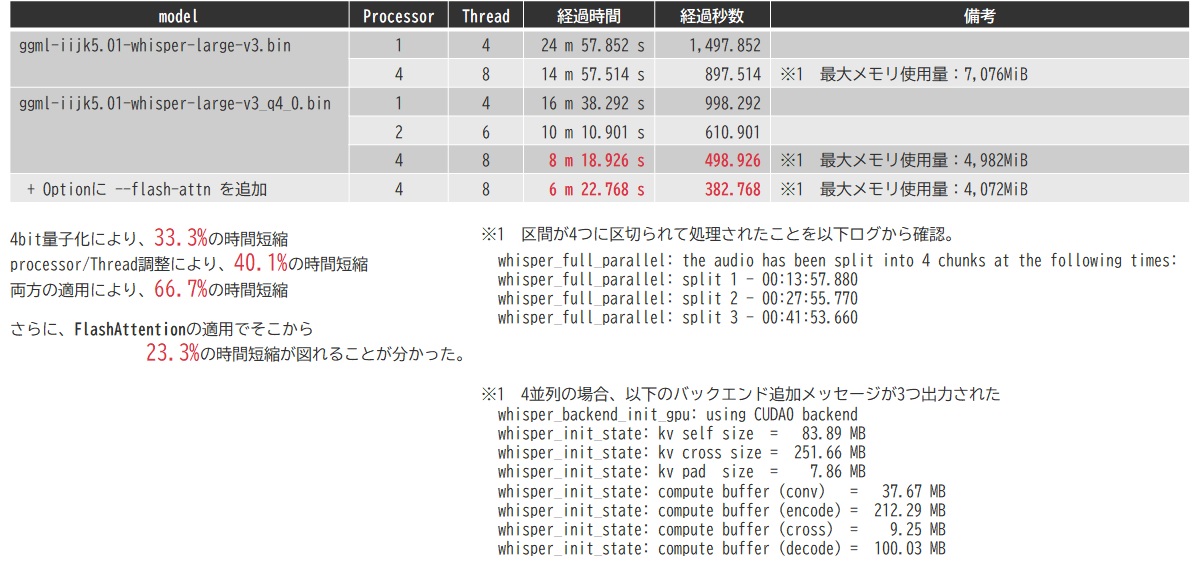
パラメータ変更及び量子化モデルの採用で書き起こし実験をした結果
連携先に考えたいこと
連携先に考えたいプロダクトは、先でも述べましたように、Difyとの連携を狙っています。
この記事がリリースされる頃の状況は想像もつきませんが、執筆時点である2025年2月26日現在においては、メインのバージョンは0.15.3、ここからどうやら1.0.0にバージョンアップをしようとしている時期のようです。
注:見事Difyは2025年2月28日にv1.0.0がリリースされました。3月14日現在ではv1.0.1が最新となっていますね・・・
当方でも社内ツールとして活用すべく、このツールを用いて様々なアプリケーションを作ってみたりしています。その一例をあげると、
- ELYZA-Tasks-100の処理をワークフロー+バッチ処理で楽にやる(ただ、一度実行させたら最後止まらない)
- 簡易的なアイコン作成ツールをつくる(Stable-Diffusionよりも何だかDALL-E3の方がポップで可愛いアイコンが作れる気がする)
- 社内でローカルLLM APIサーバを構築・運用してみた話と連携させて、サービス系情報と絡めてRAGを作って社内サービスの勉強をするためのボットを作って対話する(マニアックすぎるロボットに最近GRPO-Phi4を突っ込んでみたり)
等諸々色々やってます。
WhisperもSPEECH2TEXT的な扱いができるような仕組みが組み込まれており、特にDify上に別途構成しているLLMと連携させて議事録をより精度高く構成できたらいいよねーなどと考えていたりします。以下のように試作品はすぐできるんですが、元々の月読と比べると補正機能がなかったり、形式を複数設定できず、いわゆる「Text」フォーマットで設定が固定されていたりと、単独のツールとしては難しい(というか、物足りない?)ところもそこそこあります。
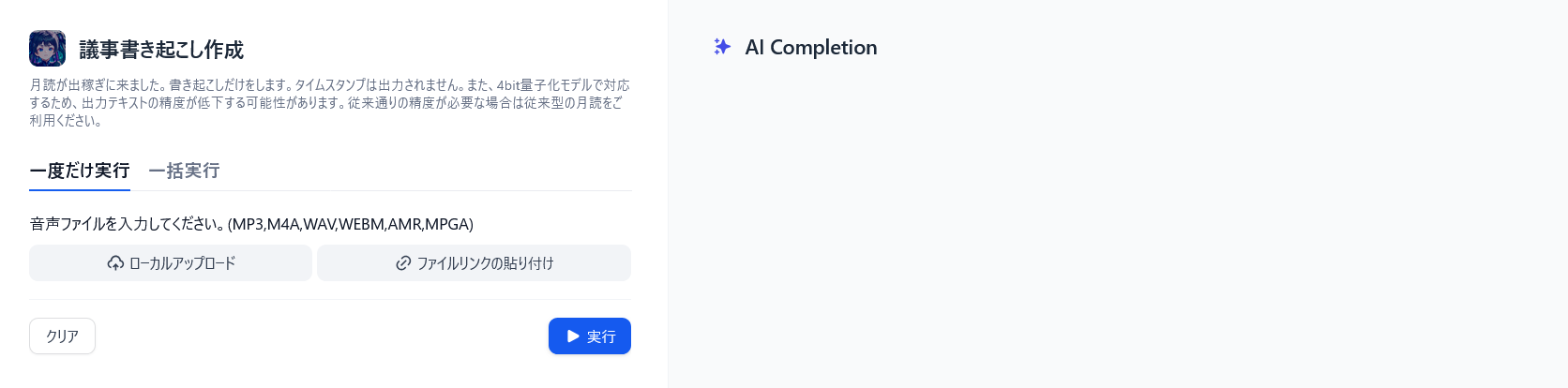
Dify版月読の試作ワークフロー
特に、Difyのアプリ形態の1つである「ワークフロー」は仕組みを作ってそのまま使ってだけでなく、その仕組みを他のWebアプリにフローとして組み込むことができる点に連携の幅が広がる可能性を秘めており、その1プロセスとして組み込むことで、過去に作ったモデルが決して「負の遺産」などと呼ばれることのない、有効な使い方が出てくるであろうと信じながら、様々な試行を行っているところです。