社内でローカルLLM APIサーバを構築・運用してみた話
2025年02月17日 月曜日

CONTENTS
はじめに
■ 背景
以前の記事「IIJ ✖ AI活用」でも紹介したように、IIJではAI技術の積極的な活用が進んでいます。その中でも特に注目されているのが、大規模言語モデル(LLM)の利活用です。
LLMは自然言語処理の分野で飛躍的な進歩を遂げており、さまざまな業務においてその可能性が広がっています。
LLMを利用する手段の一つにAzure OpenAIをはじめとしたSaaSを活用する方法があります。しかし、その多くは従量課金制であり、「気軽に遊んでもらいたい」という要望に応えるのは少々難しいという課題があります。
また、SaaSのAIが扱えるデータは社外秘情報までであり、機密情報や顧客情報を含むデータは扱えないという課題もありました。
■ ローカル LLM API サーバ導入の狙い
上記の課題を踏まえ、IIJ の社内ネットワーク内にローカル LLM API サーバを構築・運用するプロジェクトを開始しました。このプロジェクトの目的は以下の 3 点です。
- データセキュリティ: 社内ネットワーク内での運用により、機密情報や顧客情報の外部流出リスクを最小限に抑え、安全な環境で LLM を活用できるようにする。
- 安定した運用環境の構築: 外部サービスへの依存を排除し、安定したパフォーマンスと可用性を実現することで、信頼性の高い LLM 運用基盤を確立する。
- AI 活用促進とイノベーション: 社員全員が気軽に LLM を利用できる環境を整備することで、AI 活用を促進し、新たなビジネス機会の創出や業務効率の向上を目指す。社内文化として AI 活用を醸成することも狙いのひとつ。
システム要件
プロジェクト成功のために、以下の要件を満たすシステムを構築しました。
- 完全ローカル動作: インターネット接続を必要とせず、全ての処理が社内ネットワーク内で完結すること。
- 全社員アクセス可能: 社内ネットワークに接続している全ての社員が利用可能であること。
- 高パフォーマンス: 実用的な応答速度を確保し、ストレスなく利用できる環境を提供すること。
プロジェクト発足時には IIJ 社員だけでも 2000 人以上いたため、本当に実現できるかなぁとちょっと不安でした(笑)
全体構成の概要
■ システム構成図
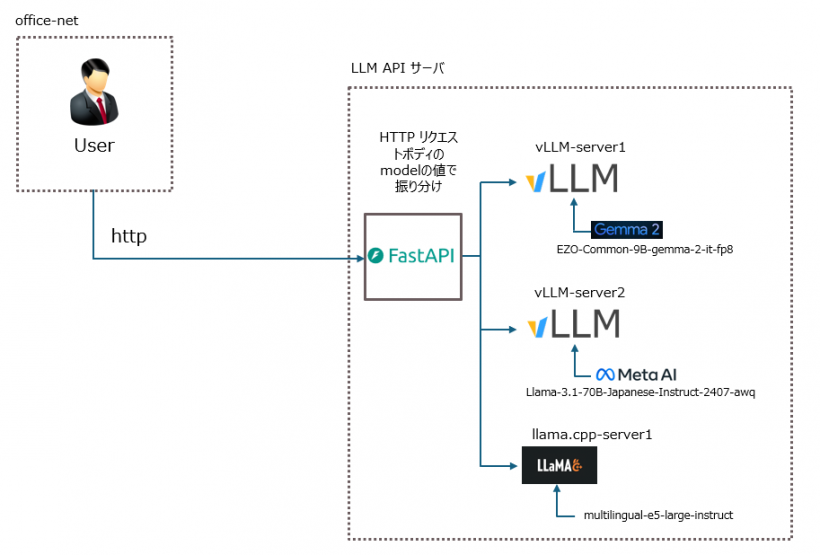
■ 各コンポーネントの説明
- FastAPI: ユーザからのHTTPリクエストをmodelパラメータに基づいて適切なバックエンドサーバ(vLLM サーバ または llama.cpp サーバ)にルーティングします。これにより、クライアントは単一のエンドポイントで複数の LLM や単語埋め込みモデルを利用できます。
- vLLM サーバ群: LLM の推論処理を担当します。vLLM を用いることで、高速かつ効率的な推論を実現しています。複数のサーバを立て、それぞれ異なる LLM をロードしています。
- EZO-Common-9B-gemma-2-it: Google の Gemma-2 というモデルを、 Axcxept株式会社が日本語チューニングしたモデル。
- Llama-3.1-70B-Japanese-Instruct-2407: Meta の Llama-3.1 というモデルを、株式会社サイバーエージェントが日本語チューニングしたモデル。
- llama.cpp サーバ: 単語埋め込みモデルを提供します。llama.cpp のllama-server機能を用いて、multilingual-e5-large-instructを OpenAI API 互換で提供しています。
■ vLLM 採用理由
vLLM を採用した主な理由は以下の 2 点です。
- OpenAI API 互換性: 既存の OpenAI API を利用したコードを最小限の変更でローカル LLM サーバに移行できるため、ユーザ目線での導入のハードルが低くなります。さらに、Dify や Open WebUI といった LLM を活用したフレームワークと相性がいいという点や、トークンのストリーミング表示が容易という点も魅力的でした。
- 高速な推論性能と効率的なリソース利用: Paged Attention、Continuous Batching などの最適化技術により、高速な推論と効率的なリソース利用を実現しています。バッチ処理に強いため、チャットボット以外の活用にも耐えられます。
この構成により、複数の LLM と単語埋め込みモデルを柔軟に利用できる API サーバを構築できました。
■ モデル選定理由と量子化
今回、2つの LLM、EZO-Common-9B-gemma-2-it と Llama-3.1-70B-Japanese-Instruct-2407 を採用しました。選定理由は、出力文章の個人的な好みと、ELYZA-tasks-100 という日本語の指示に基づくタスクを評価するためのデータセットのスコアです。
様々なモデルで実際にプロンプトを入力し、出力結果を比較検討しました。その結果、これらのモデルがバランス良く優れた性能を示し、今回のユースケースには最適であると判断しました。
しかし、Llama-3.1-70B-Japanese-Instruct-2407 はパラメータ数が多く、高精度な出力が期待できる一方、GPU 上の VRAM 使用量も大きいため、bfloat16 のままでは運用が困難でした。そこで、AWQ (Activation-Aware Weight Quantization) という手法を用いて INT4 に量子化を行いました。これにより、限られたリソース環境でも 70B モデルの運用を可能にしました。
一方、EZO-Common-9B-gemma-2-it は、比較的軽量ながらも高い性能を持つモデルです。こちらも bfloat16 のままだと VRAM 使用量が大きかったため、FP8 に量子化を行いました。
これらの量子化手法により、VRAM 使用量を大幅に削減し、複数の LLM を同一サーバ上で並行稼働させることを可能にしました。
運用開始後の効果
ローカル LLM API サーバの運用開始後、社内での AI 活用に少しだけ変化が見られました。様々な活用事例が社内ブログで紹介され、AI 活用を促進する好循環が生まれています。
■ 効果 1:多様な業務への適用
コーディング支援、ドキュメント要約、機器ログの解説など、多様な業務シーンでの活用事例が社内で共有されています。いくつか例を紹介すると、
- コーディング支援: コードの自動生成やバグ修正、コードレビューに LLM を活用し、開発効率を向上させています。
- ドキュメント要約: サービス運用ドキュメントや議事録などを要約することで、情報収集にかかる時間を削減しました。
- 機器ログの解説: 複雑な機器ログを LLM が解析し、分かりやすい言葉で解説することで、トラブル原因の究明にかかる時間を削減しました。
これらの事例は、LLM が単なる「便利なツール」ではなく、様々な業務における課題解決に役立つ「強力なパートナー」になり得ることを示しています。
■ 効果 2:LLM フレームワークとの高い親和性
Dify 等の LLM フレームワークとの連携事例も報告されており、OpenAI API 互換で API を提供するという当初の設計方針が正しかったことが証明されました。Dify のようなツールと組み合わせることで、ノーコードで LLM アプリケーションを開発できるようになり、さらに広範な活用が期待できます。例えば、
- 社内 FAQ チャットボットの構築
- 特定業務に特化した文章生成ツールの作成
などが容易に実現可能になりました。
■ 効果 3:ストレスフリーなレスポンス速度
トークン生成スピードは Llama-3.1が平均 25Token/sec 、Gemma-2 が平均 35Token/sec を維持できており、チャットボットのようなリアルタイム性を求められる用途でもストレスなく利用できています。これは vLLM による高速な推論処理と、適切なモデルの量子化による最適化の成果です。また、トークン生成のストリーミング表示が簡単に実現可能なこともユーザ体験の向上につながっていると推測されます。
運用の課題
一定の効果が得られた一方で、いくつかの課題も明らかになりました。
- 生成における不安定性: INT4に 量子化した Llama-3.1 で、特定条件下において単語ループが発生します。パラメータ調整である程度抑制できますが、根本的な解決策は見つかっていません。

- 社員全員への利活用推進: 現状は一部の社員による利用が中心となっています。より多くの社員に利用してもらうために、ユースケースの作成・紹介、ハンズオンセミナーの実施、フィードバック収集などが必要になると思われます。
- リソース不足: VRAMがいくらあっても足りません(笑)。70B とパラメータが大きい LLM を運用するには、膨大な VRAM が必要となります。現状でも、安定稼働のためには、モデルサイズの 1.5 倍以上 VRAM が必要となっており、リソースに余裕があるとは言えません。先ほど述べた生成における不安定性もあり、Llama-3.1-70B-Japanese-Instruct-2407 を FP8 で運用したいところですが、VRAM が 120GB ほど必要になってしまうため、導入が困難です。今後のモデルサイズの大型化も想定すると、VRAM 不足は深刻な課題となります。
まとめ
IIJ の社内ネットワークにローカル LLM API サーバを構築・運用した事例を紹介させていただきました。OpenAI API 互換のインターフェースを採用することで、既存資産や LLM アプリケーションフレームワークとの連携をスムーズに実現し、多様な業務における LLM 活用を促進することができました。コーディング支援やドキュメント要約など、既に複数の業務で効果を発揮しており、社員の生産性向上に貢献しています。vLLM の採用により高速な推論処理を実現し、ストレスフリーなレスポンス速度を達成している点も大きな成果です。
これらの取り組みを通じて、LLM の安定運用と更なる活用促進を実現し、ひいては会社全体の生産性向上と新たな価値創造に繋げていきたいと考えています。また、今回の取り組みで得られた知見やノウハウがローカル LLM 導入を検討している方々の参考になれば幸いです。
今回のプロジェクトで使用させていただいているLLM
今回のプロジェクトで使用させていただいているLLMについて、以下にご紹介いたします。
特に日本語チューニングに関しては、その言語特有の難しさから非常に多くの労力を要するものですが、それにもかかわらず、オープンな形で公開していただいていることに、心より感謝申し上げます。




