ローカルLLMの受け入れ文字数を増やすことで起きる影響
2024年10月10日 木曜日
CONTENTS
こんにちわ。九州のとみーです。
前回の記事では、初めてファインチューニングの記事を載せました。
今回はそんな検証のさなかにふと気づいて取り組んだ検証のお話になります。
LLMの受け入れ文字数⇒コンテキストサイズ
ローカルLLMに限らず、LLMには1つのメッセージのやり取りで使用可能な受け入れ文字数というのがあります。
厳密に言うと、入力文字を数値化した「トークン」という単位にはなるのですが、この長さの制限として「最大コンテキストサイズ」というものがあります。例えば
- Google Gemma-2モデルは全般的に8,192トークン
- OpenAI GPT-3.5-Turboモデルは16,384トークン
- OpenAI GPT-4 omniモデルは131,072トークン
というように決まっています。この長さは
「想定される入力の最大トークン数」+「想定される出力の最大トークン数」
として扱われ、特に入力トークン長が制限を超過した場合はエラーとなったり、先頭のトークンが切り捨てられたりします。
何故入力だけでなく出力まで気にする必要があるのか?というと、LLMはメッセージ出力をする際、以下のような処理の繰り返しを行うためです。
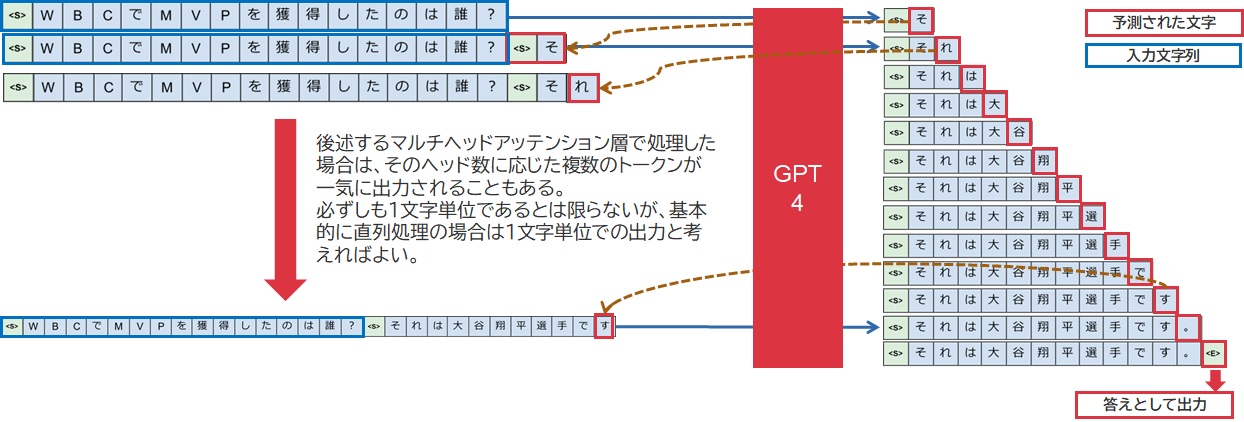
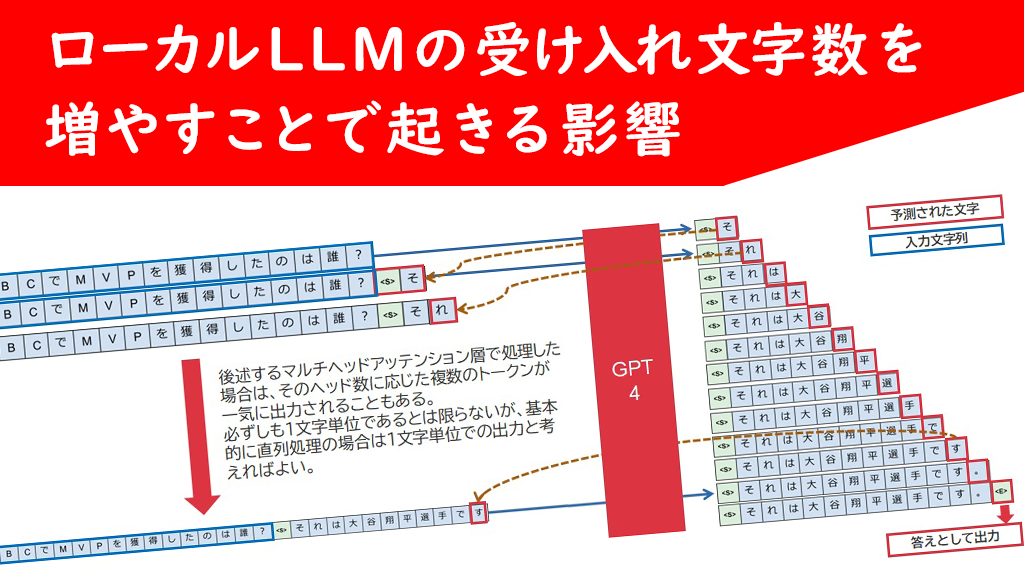
推論処理の流れ
これは過去に自身で作成した資料の一部を切り取ったものなのですが、よく図示されるニューラルネットワークの一介の処理で出力されるのは、実は1トークンであり、それを質問として入力したコンテキストの末尾に結合した文字列を繰り返し投入することによって回答文全文を出力していく・・という仕組みになっています。つまり、回答文の終端を示す<EOS>というトークン(EOS:End of Strings)を出力するころには、入力コンテキスト領域の中には、入力文と出力文ほぼ全てが入り込んでいるのです。
故に、OpenAIライブラリなどでは入力コンテキストのトークン数だけでなく、そこで指定される最大応答トークン数の値を合算して最大コンテキストを超過しないかどうかが確認され、推論基盤側で超過が認められるとエラー応答が返ってくる仕組みになっています。GPT-3.5-TurboやGPT-4の初期版などを使用していたころは、この仕様にかなりやきもきさせられました。
以前は、ローカルLLMだとこの最大コンテキストサイズが1k(1,024)から4k(4,096)だったり、長くても32k(32,768)だったりしたのですが、最近Llama-3.1系ですと128k(131,072)トークンという長いコンテキストサイズにも対応できるものが増えてきました。特に長いのがMistralAIがリリースしているMistral-Nemo-Instruct-2407ではなんとGoogle Gemini系と同様の1M(1,024,000)を受け入れ可能であったりとかなり進化して来ました。
コンテキスト領域はメモリを消費する
そうして私の造語ですが「超コンテキスト長対応LLM(32k以上のコンテキスト長を持つモデル)」を使うことでプログラムソースを丸々投入し、その動作概要を求めたりとか言うようなこともできるようになってきましたし、ログメッセージを眺めに採取してこれを投入することで、よりトラブルシュートに効果的な情報を得やすくなってきたりもしました。これは非常に便利な機能です。
しかし、実はこのコンテキスト領域、メモリをかなり消費することが分かりました。メインメモリではありません。GPU上のVRAMです。
現在私の所属する技術推進課の検証サーバのVRAM使用状況は以下の通りとなっています。
Wed Sep 18 11:13:33 2024 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 3060 On | 00000000:17:00.0 Off | N/A | | 37% 34C P8 15W / 170W | 11MiB / 12288MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ | 1 NVIDIA L4 On | 00000000:4E:00.0 Off | 0 | | N/A 51C P0 23W / 72W | 20223MiB / 23034MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ | 2 Tesla P100-PCIE-16GB On | 00000000:85:00.0 Off | Off | | N/A 38C P0 32W / 250W | 15014MiB / 16384MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | 0 N/A N/A 1738 G /usr/lib/xorg/Xorg 4MiB | | 1 N/A N/A 1738 G /usr/lib/xorg/Xorg 4MiB | | 1 N/A N/A 516409 C /opt/llama.cpp/bin/llama-server 8974MiB | | 1 N/A N/A 516413 C /opt/llama.cpp/bin/llama-server 8886MiB | | 1 N/A N/A 516434 C .../miniconda3/envs/fastapi/bin/python 2332MiB | | 2 N/A N/A 1738 G /usr/lib/xorg/Xorg 4MiB | | 2 N/A N/A 1766 C ...miniconda3/envs/seamless/bin/python 2952MiB | | 2 N/A N/A 516411 C /opt/llama.cpp/bin/llama-server 12056MiB | +-----------------------------------------------------------------------------------------+
色々なLLMをllama.cppを用いて動かしているのですが、その中でGPUID2番となっているNVIDIA P100で動いてるllama-serverプロセスのVRAM使用量は12,056MiBとなっています。実はここで動かしてるモデルはLlama-3.1-8B-EZO-1.1-it-Q4_K_M.ggufというGGUFモデルで、AXCXEPT社がLlama-3.1-8Bをチューニングしたものに、私の方で4ビット量子化したものになります。
このモデルのサイズ自体はそれほど大きくなく、4.6GiBとなっています。最低限このサイズ分の領域は確保される上にワーク領域で10%ほど消費されることから、5-6GiB程度のVRAM使用は想定してるわけですが、現実には12GiB近く消費しているということで。実はこれ、128kのコンテキストを受付可能なモデルではありますが、そのまま実装しようとするとメモリ不足で実行できませんで、実際の設定では40k(40,960)に制限してこの値となっているのです。それだけ、コンテキスト領域確保のために多くのメモリが必要なようです。
その他、ここで以前に動いてたモデル含めてまとめてみるとこんな風になりました。いずれも、モデルファイルサイズよりも思ったより多くのメモリを消費していることが分かります。

ローカルLLMのモデルサイズと実際の消費量
というわけで、ぶっちゃけコンテキストサイズを拡張することにより、消費するVRAMはどう増加するのか?という所を検証しました。
検証方法
今回、何かしらの方法でローカルLLMを様々なコンテキスト長で動かし、その結果をnvidia-smiで採取して確認するということを行いました。LLMを動かす方式としては、お得意のllama.cppに含まれるllama-serverを使用しました。これには理由がありまして、
- llama.cppの仕組みはメモリを全量事前に確保する仕様であるため
- vLLMも設定次第で同様のことは可能だが、追加設定が必要な上にメモリリークの問題があり、うまくメモリ使用量が測定できない
という所が挙げられます。特にllama.cppでは長時間サーバプロセスを起動してもメモリ消費量が微動だにしないことをこれまでの動作実績で確認していて、一番ブレが少ないんじゃないかなという所がハマりました。
確認方法としては以下の通りとしています。

準備したGGUFファイルは以下の通りとしました。
- Reflection-Llama-3.1-70b.Q4_K_L.gguf
- Llama-3.1-70B-EZO-1.1-it-Q4_K_M.gguf
- Llama-3.1-8B-Ezo-1.1-it.gguf (bfloat16)
- Llama-3.1-8B-Ezo-1.1-it-Q4_K_M.gguf
本当は16ビットサイズの70Bモデルも試したいところですが、今回使用しているNVIDIA L40S x2の構成でもとてもメモリが足りないため、4ビット量子化モデルを別々のチューンドモデルから用意し、チューニング内容の際による違いとかが取り出せたらおもしろいかなぁという感覚で準備しています。
8Bモデルに関してはちゃんと16ビットモデルも取り扱えますので、量子化する・しないの違いをキャッチしようとしました。
結果
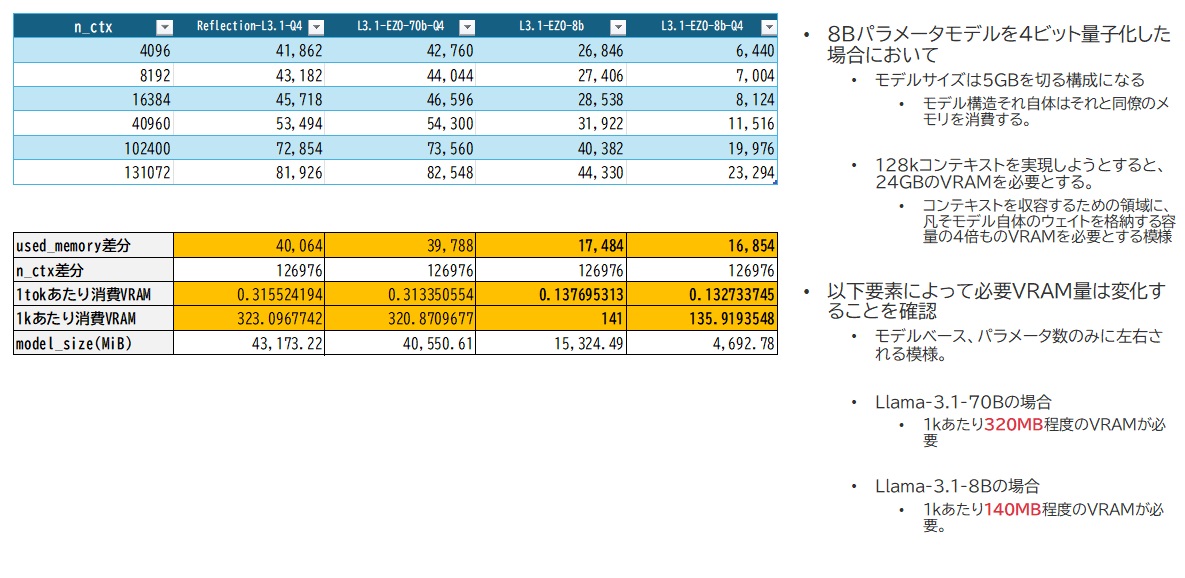
モデル毎でのVRAM消費量
結果としては面白いものになりました。
- パラメータ規模によってコンテキストサイズによるメモリ使用量は変化する
- 70bモデル同士を比較すると分かりやすいのですが、グラフの線がほぼ一致しています。
- 量子化する・しないによるコンテキストサイズによるメモリ使用量はほぼ変化しない
- ぱっと見、Llama-3.1-EZO-8bモデルにおいては4ビット量子化のものよりもメモリが多いような感じがしますが、これはあくまでモデル情報を取り込んだ直後のサイズが異なるだけで、その増加量は同じです。それは、グラフが並行していることからわかるかと思います。
グラフにしてみるとさらにこれが分かりやすくなりました。
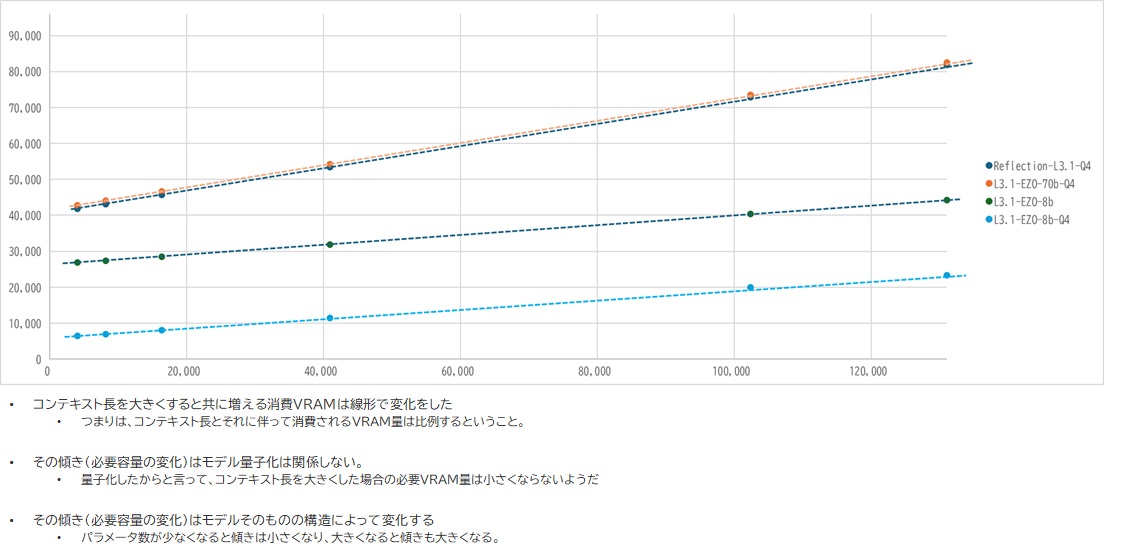
コンテキストサイズに伴うVRAM消費量の推移
その増加量は「比例」することが分かりまして、どこかのタイミングで急激増加するわけじゃないんだなということもわかりました。
それ故、トークンあたりのVRAM消費量が算出できたわけなんですよね。128kコンテキスト長を実現するには、8Bモデルを量子化したとしても24GB程度のVRAMがないとこれを実現することは難しいのだなと理解できました。思ったより超ロングコンテキストというものに対するハードルは高そうです。
コンテキスト長の要素がメモリを食う要因とは?
どうやらこれは、Self Attention層の処理が影響するようです。
LLMにおいては、現在のアーキテクチャでは大体がDecoder onlyなTransformerの仕組みが採用されています。Encoderがある場合のTransformerはSelf-Attention層とCross-Attention層が構成されるのですが、Decoderだけの構成ではSelf-Attention層だけが構成されます。過去にこの辺りの細かい動きを調べたことがあり、当時は下図の通り図示しています。
Self-Attention層の場合、変換元・変換先のデータに同一のデータを使用します。
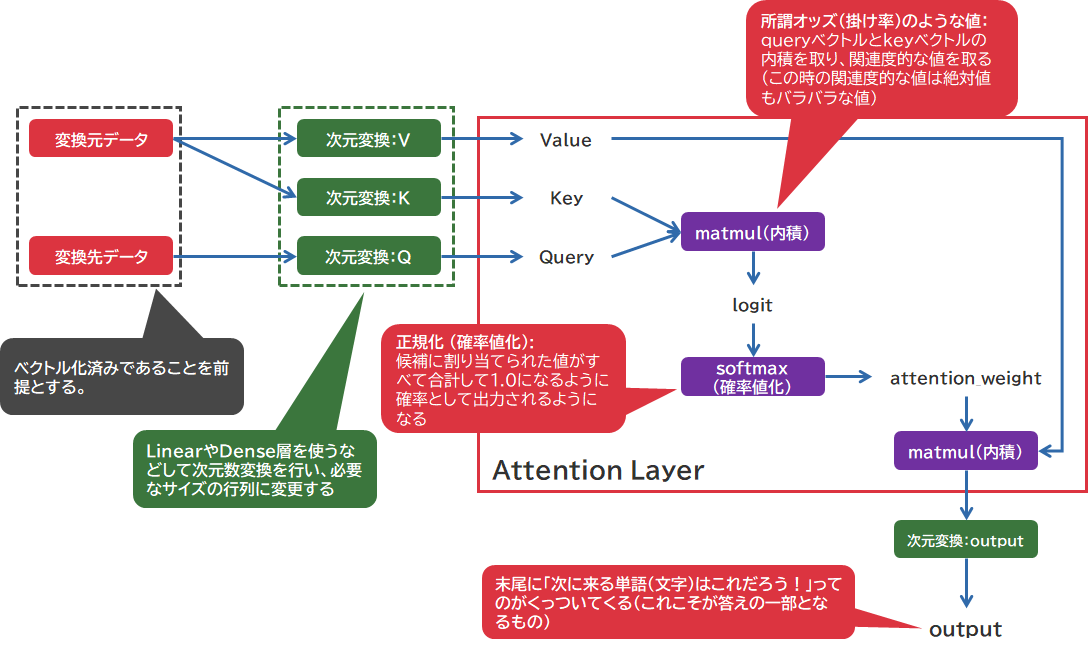
Self-Attention層では以下のような文章における文脈間の関係性を組み上げていきます。
- 主語は何か
- 述語は何か
- 目的語は何を指しているか
- より具体的な表現はどこにあるか
この過程において、途中matmul(内積)処理によってオッズ表的なものを組み上げていくわけですが、Queue/Key同士のトークンに基づく関係性を数値計算によって算出することになります。そのオッズ表計算を行うにあたり、入力文字列にて構成されるトークン全要素を互いに総なめするような確率表を作り出さなければなりません。その際の計算量はオーダーとしておよそコンテキスト長の2乗に相当することになります。これは超ロングコンテキストを実際に流し込んだ時、天文学的な計算量が発生することを意味します。
本来はどんなにコンテキスト長が長く設定されたとしても、実質的にそれだけの長文を流し込まない限りはこの影響は起きません。transformersライブラリやvLLMを使用した場合、通常は入力サイズに合わせてコンテキスト領域のサイズは必要に応じて動的拡張するような仕様になっています。予め全量メモリを押さえることがデフォルト設定になっているのはllama.cppぐらいではないでしょうか。
量子化を施したとしても、Embedding処理で生み出されたイメージの解像度(ベクトルの要素数)は変化なく、あくまでその要素ごとの数値精度が変化するだけであるため、コンテキスト長で要求されるデータ量には大きな差がつかず、結果的にその増加量に差異がなくなってしまったのかなぁと思っていますが、この辺りはまだまだ調べないと分かんないなぁとも。
また、今回はパラメータ規模によって大きな差が生じていますけれども、これはおそらくSelf-Attention層だけでなく、ニューラルネットワーク全体におけるHidden Dimensionの値の違いにもあるのだろうと推察しています。Embeddingデータに変換されてベクトルになった状態でSelf-Attention層に入力文字列は投入されますけれども、そのベクトルの次元数は単純に計算回数、メモリ領域のサイズに跳ね返ってきます。コンテキスト長と共にその内部処理の次元数もまた、その値の2乗分の計算ループを発生させることになるのです。
途中、コンテキスト長とEmbedding化した状態でのデータ構造があやふやになって調査が進まなかったりすることもあったりで、個々の根本に対する理解を進めるのには本当に苦慮していますが、きちんと進めていきたいなぁーなどと考えているところです。浅慮な記述もありますが予めご了承ください。
まとめ
いずれにしても、今回の検証を通じて、以下のことは明確になりました。
- コンテキスト長の設定は「本当に必要な長さ」を定義すべきと考える
- コンテキスト長が過剰である場合、メモリ容量どころか推論速度自体にも影響を及ぼす
- コンテキスト長に伴う消費リソース量はパラメータ規模に左右される
- 量子化ではコンテキスト長に伴う消費リソース量の削減には至らない
こうした疑問を元に調べてみたことで、意外なリソース消費箇所があるんだなぁというのをいまさら知ったりするわけですが、実測してみたら比例する点などはやっぱり計測してはじめてわかるところも多く、バカにはできないものだなーと思っています。そう考えるとGoogle Geminiの1Mコンテキスト長・・という仕様がいかに化け物じみたものかというのがよくわかりますし、なぜ大手各社があんなにGPUリソースを大量に求めているのかもなんとなくわかる気がします。Googleなどはそれに嫌気がさしてTPUを自ら開発したわけですし、恐らくGPUで今行われているAIソリューションというものは、決して効率的・適切なものではないのでしょう。
しかしながら、昨今そうした現状を打破しようと奮闘するところもたくさん登場してきているわけで、如何にしてコンテキスト長によるオーバーヘッドを軽減すべきかと改良に取り組んでるところもちらほら見かけておりまして、ハードとしてもソフトとしても新しい着想に基づくものが色々登場してきたりはします。こうした面からの革新というのも恐らく、思う以上に速いペースで進んでいくのかもしれないなと感じました。




