LLM 推論のフォールトトレランス
2024年12月23日 月曜日

CONTENTS
【IIJ 2024 TECHアドベントカレンダー 12/23の記事です】
※この記事は、原文「Fault-Tolerance for LLM Inference」の和訳です
はじめに
大規模言語モデル (LLM) は、チャットボット、コンテンツ生成 (テキスト、画像、動画)、翻訳など、さまざまなタスクでますます人気が高まっています。
LLM ユーザは、プロンプト (要求を説明するテキスト) を送信して、このようなシステムと対話します。次に、LLM は、推論 と呼ばれるプロセスで GPU セットを活用して回答を生成し、その後、ユーザに回答を返します。
以前の機械学習システムと比較すると、最先端の LLM には数百 GB の GPU メモリが必要ですが、NVIDIA A100 などのハイエンド GPU には 80 GB の RAM しかありません。そのため、モデルを複数の GPU に分割する必要があります。
残念ながら、大規模な GPU の導入は失敗しがちです。これは、Eisenman らと Patel らによって実証されています。
推論中に障害が発生すると、ユーザリクエストを最初から再計算する必要があり、追加のレイテンシと計算が発生します。そのため、一部の研究者は LLM 推論をフォールト トレラントにしています。
この投稿では、LLM 推論のメカニズムについて詳しく説明し、A100 GPU で行われたいくつかの実験を紹介し、最後にフォールト トレラント LLM 推論用の DéjàVu システムについて説明します。
LLM 推論の概要
LLM 推論は、ユーザが「東京は」というプロンプトを送信している下の図に示すように、複数のフェーズから成るプロセスです。
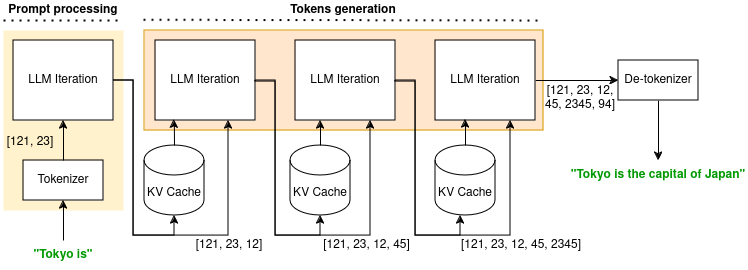
モデルは最初にそれをトークン化し、モデルのみが理解できる トークン と呼ばれる数値のセットを出力します。次に、トークンは LLM によって 1 回の反復で処理されます。これらの 2 つの計算は、プロンプト処理フェーズ を定義します。このフェーズでは、キー値キャッシュ (KV キャッシュ) に保存された コンテキスト と新しいトークンの両方が出力されます。
推論の 2 番目のフェーズは トークン生成フェーズ で、回答の残りのすべてのトークンが計算されます。1 回の LLM 反復で、以前のコンテキスト (KV キャッシュに保存) とトークンを入力として、1 つの新しいトークンが計算されます。KV キャッシュに保存される新しいコンテキストと新しいトークンが出力されます。
最後に、LLM は、ルックアップ テーブルにアクセスするのと同様のプロセスで、トークンを人間が読める出力に変換します。この出力 (上の図では「東京は日本の首都です」) は、クライアントに返されます。
障害を許容するための 1 つのアイデアは、KV キャッシュを永続化して、リクエストを最初からではなく、障害前の最新の状態から再計算できるようにすることです。
私たちの実験
私たちは、OPT-13B モデルを使用して、2 つの A100 GPU (それぞれ 80 GB の RAM を搭載) でいくつかの実験を実行しました。モデルをロードすると、GPU ごとに 40 GB のメモリが割り当てられます。バッチ サイズは 8 に設定されています。目標は、永続的な KV キャッシュを実装することで、潜在的なレイテンシ ゲインを評価することです。
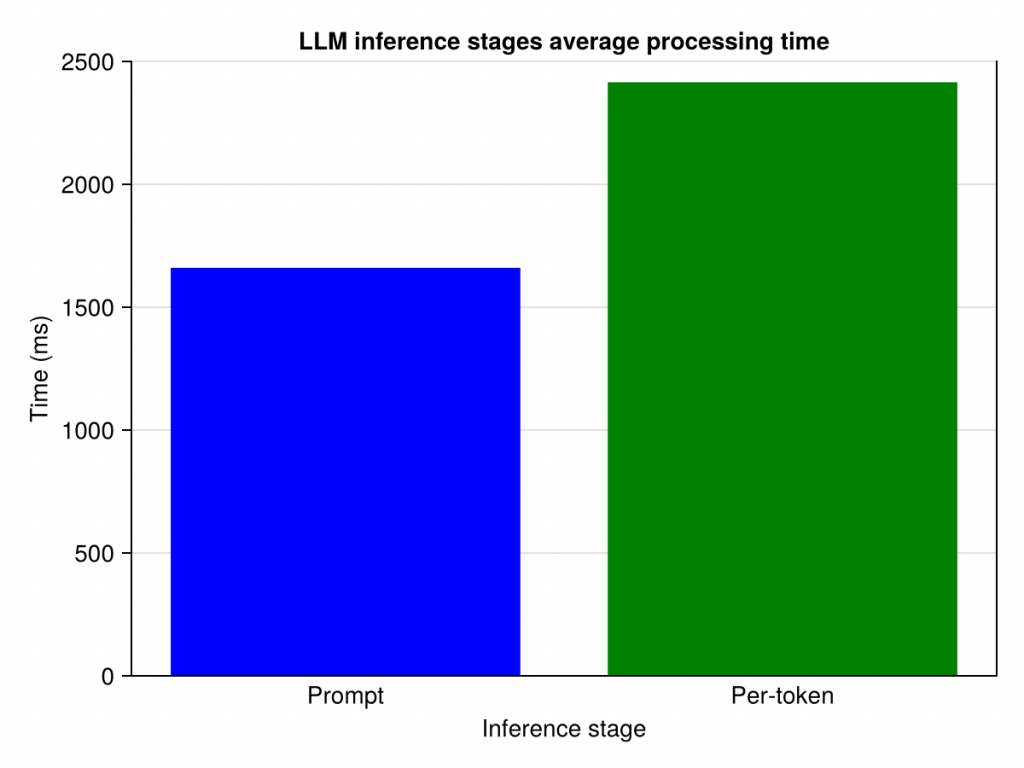
最初の実験では、各推論段階の平均処理時間を測定します。実験は、合計 2000 トークン (プロンプトの 40 トークンを含む) を生成した後に停止します。下の図からわかるように、プロンプトの処理には 1.7 秒かかりますが、1 つのトークン生成には 2.4 秒かかります。したがって、推論中に 1 回失敗すると、数秒の遅延が発生します。
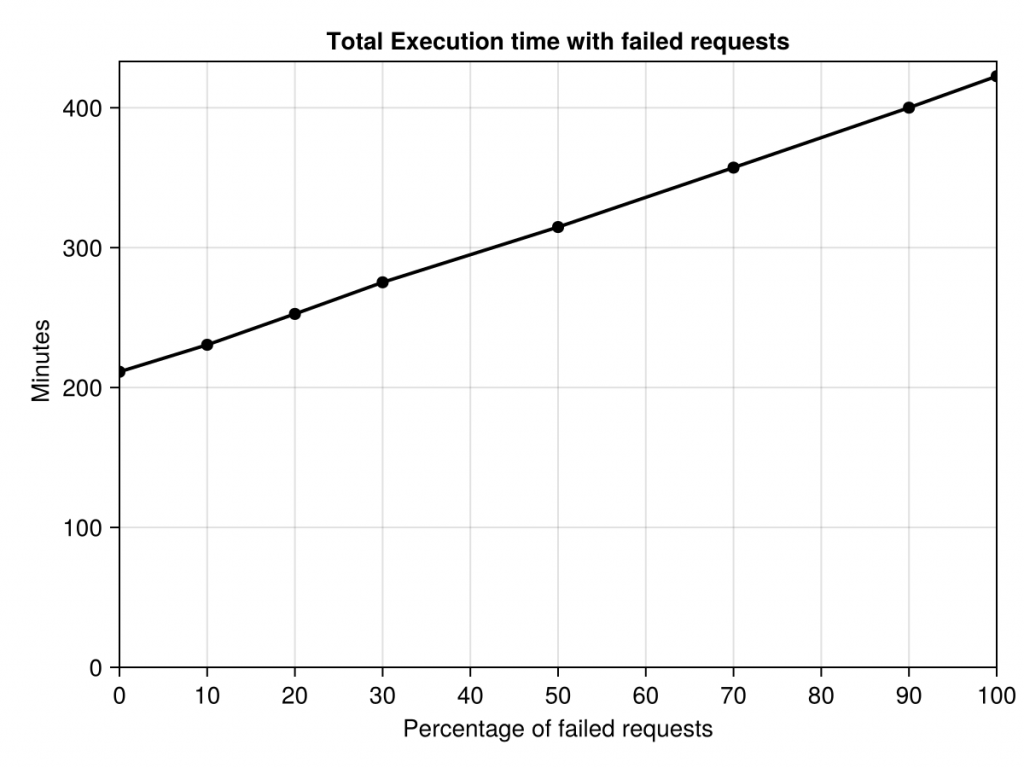
2 番目の実験では、失敗を導入しながら Microsoft Azure コードトレース を再生します。指定された割合のリクエストが失敗すると、GPU は最初から再計算する必要があります。
結果は下の図に示されています。失敗がない場合、トレース全体が 253 分 (4 時間強) で再生されます。失敗を導入すると、この実行時間は増加します。失敗したリクエストが 10% の場合は 277 分、20% の場合は 303 分、というように、失敗したリクエストが 100% の場合は最大 507 分になります (つまり、すべてのリクエストを 2 回実行する必要があります)。これは、9% (失敗が 10%) から 100% (失敗が 100%) への増加を表しています。
DéjàVu
DéjàVu は、LLM 推論システムのフォールト トレラント システムであり、Strati らが第 41 回国際機械学習会議 (2024) で発表したシステムです。以下の図は、研究論文から引用したもので、そのアーキテクチャを示しています。
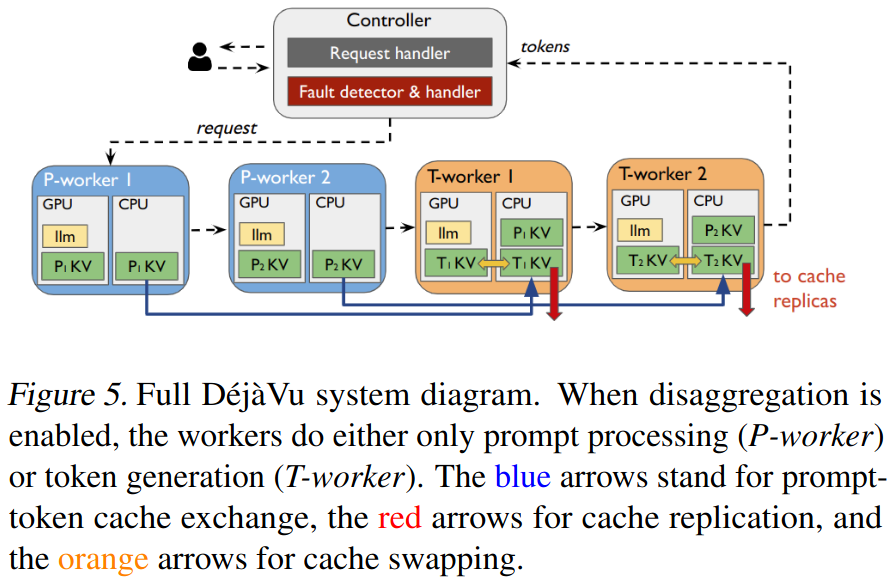
DéjàVu は、永続ストレージまたはメイン メモリに KV キャッシュを複製します。障害が発生した場合、KV キャッシュは最新の利用可能なバックアップから復元できるため、推論をゼロからやり直す必要はありません。
障害を検出できるように、GPU は定期的にハートビート メッセージを中央コントローラ コンポーネントに送信します。一定期間が経過しても特定の GPU からハートビートを受信しない場合、GPU に障害があるものとみなされます。
KV キャッシュをホスト CPU に効率的にストリーミング (つまり送信) するために、DéjàVu は KV キャッシュの更新を GPU メモリの 1 つの連続領域に集約します。これにより、小さく連続していない GPU メモリ領域を 1 つずつ転送する場合と比べて、GPU 帯域幅全体を使用できるため、GPU 転送の効率が向上します。
DéjàVu は、プロンプト処理とトークン生成を異なる GPU セットで実行して、これら 2 つのタスク間の競合を回避するなどの他の最適化を提案します。
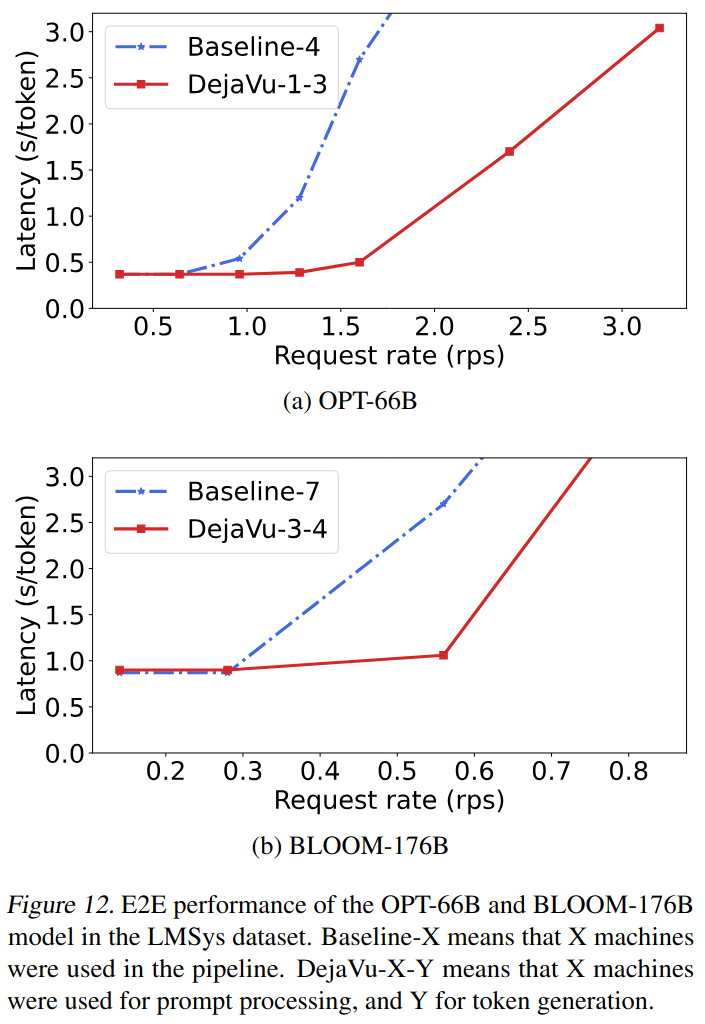
DéjàVu は、A100 GPU を搭載した実際のハードウェアで評価されています。著者らは、障害のないケースでは、低レイテンシを実現しながら FasterTransformer (ベースライン) の 2 倍のパフォーマンスを発揮することを示しています (下記参照)。
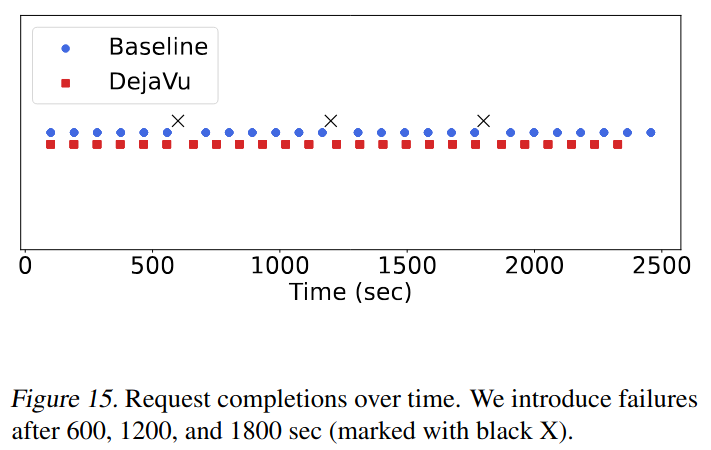
障害のあるケースでは、DéjàVu はフォールト トレラントな複製 KV キャッシュのおかげで、ベースラインよりも 16% 速く実行を完了できます (下記図参照)。
結論
この記事では、LLM 推論プロセス中の障害が問題であると主張しました。リクエストをゼロから再実行する必要があり、クライアントが認識するレイテンシが増加するためです。
2 つの A100 GPU でいくつかの実験を実行し、障害のあるリクエスト (つまり、再実行が必要なリクエスト) の割合を増やしました。10% などの低い障害の割合は、リクエストのセット全体を実行するのに 10% 長い時間がかかることを意味します。
最後に、KV キャッシュをスマートに複製し、LLM 推論プロセスの中間状態を保存することで、LLM 推論にフォールト トレランスをもたらすシステムである DéjàVu を紹介しました。その結果、リクエストはゼロからではなく、GPU 障害に近いポイントから再開できます。
謝辞
GPU へのアクセスを許可してくださった IIJ クラウド部門に感謝します。

Xのフォロー&条件付きツイートで、「IoT米」と「バリーくんシール」のセットを抽選でプレゼント!
応募期間は2024/12/02~2024/12/31まで。詳細はこちらをご覧ください。
今すぐポストするならこちら→![]() フォローもお忘れなく!
フォローもお忘れなく!