CHAGE の動き
2019年10月29日 火曜日
CONTENTS
こんにちは、CHAGE 開発メンバーのくまさかです。
前回の IIJ内製調査ツール “CHAGE” のご紹介 に引き続き、CHAGE の紹介を行ないます。
今回は、CHAGE の中身をざっくりと紹介しつつ、その一部であるISONについても紹介していこうと思います。
CHAGE の中身
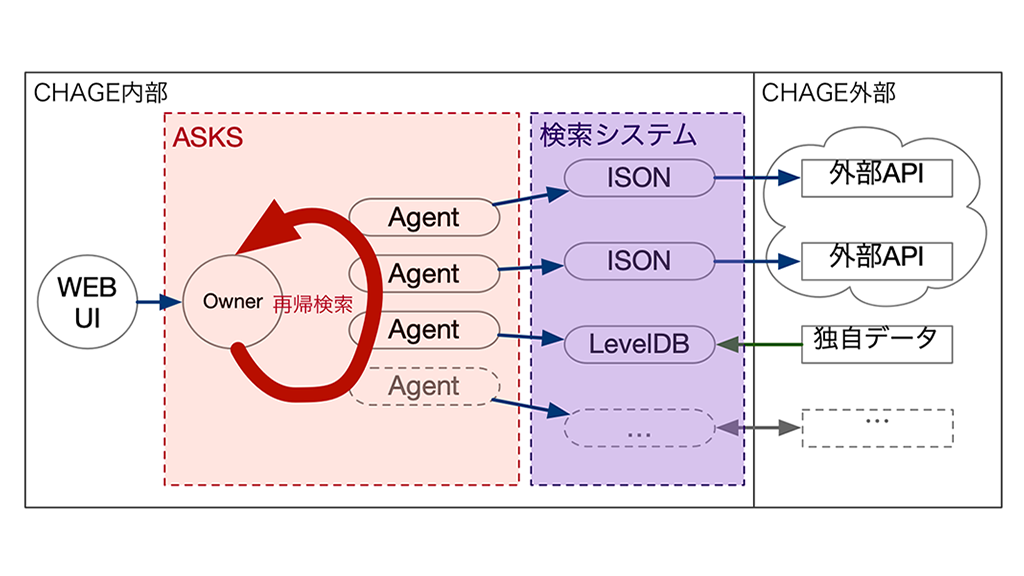
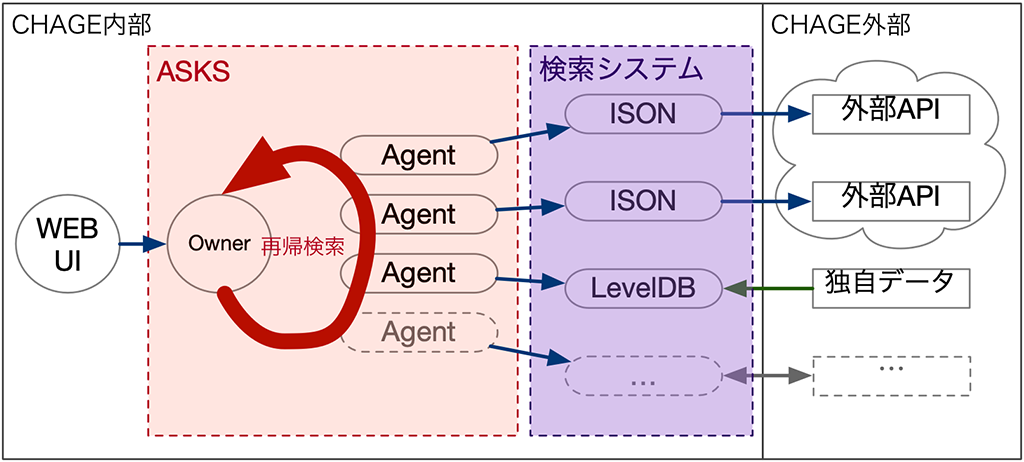
CHAGEは高速に検索をおこなうシステムなので、中身は高速検索システムが存在しています。
高速検索システムの役割は非常にシンプルで、keyを渡したら、いっぱいいっぱいvalueを応答する事です。
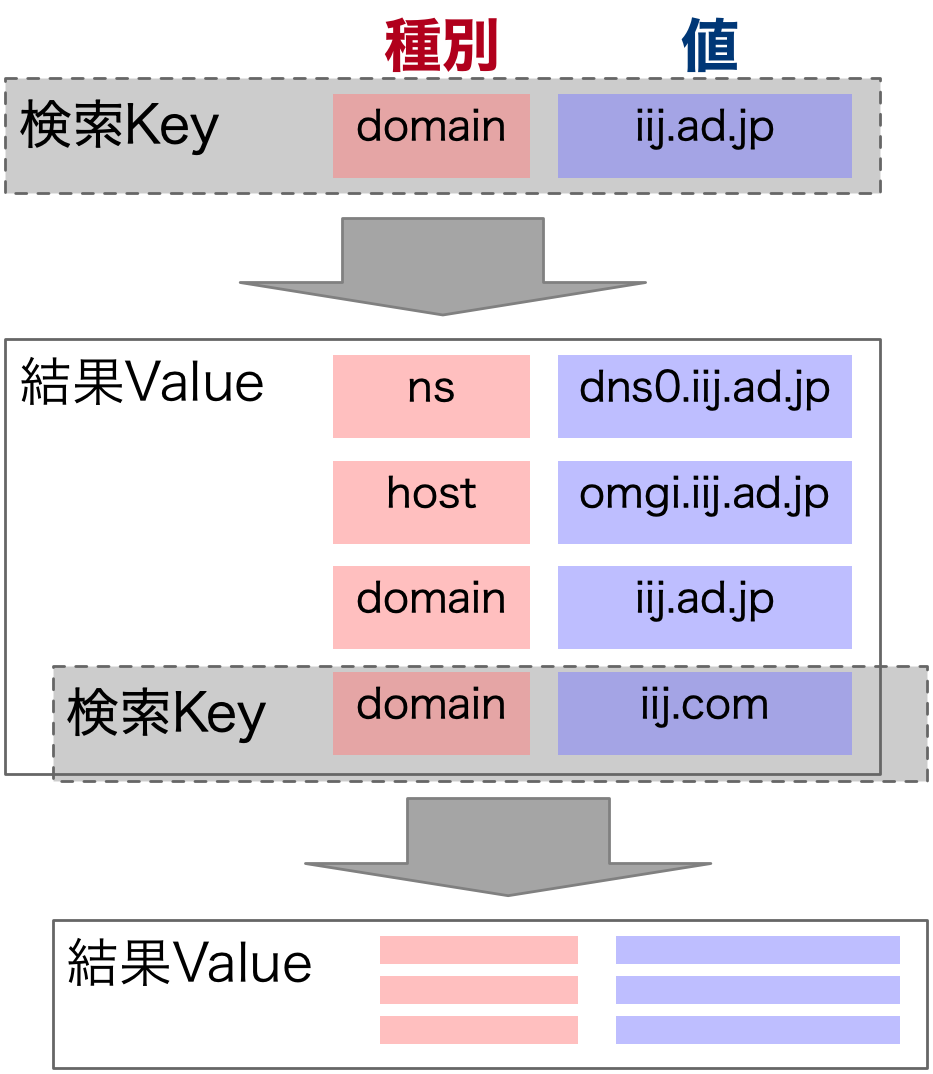
具体的には、domain iij.ad.jpと検索した場合、mx iij.ad.jpや、ns dns0.iij.ad.jp等といった情報をいっぱいいっぱい応答する事です。
具体例からわかるように、CHAGEのkey と value は同一フォーマット (種別 値形式) で、正引き逆引きから関連付け可能なデータ構造になっています。
加えてこのデータ構造は、検索結果をそのまま検索に用いることができるので、再帰検索を軽くする事にも1役かっています。
その名は ASKS
前回の記事で、こういったことを伝えました。
CHAGE の検索は、検索結果をさらに検索し、さらに検索し、、、、と再帰的に行われます。
その検索は`domain iij.ad.jp`の例でも示した通り、1度の検索で数10万件単位です。
これらを20秒程度で表示させる為に、データを集める検索は10秒程度で完了しています。
10秒で数10万件単位の検索結果を応答させる為には、ポピュラーなRDBシステムでは、圧倒的に速度が不足します。
ポピュラーなRDBシステムであっても、10秒で数10万件の応答が返せると思った方、データの扱い方によっては、その通りです。
ただ、CHAGE のデータの扱い方では、圧倒的に速度が不足してしまうのです。
CHAGE は、複数種類の購入した外部APIサービスやIIJ独自の調査データを元に検索を行なっています。
それらの1つ1つのデータの扱いや応答時間は異なり、足並みを揃え、求められる速度を満たしつつ応答させることはとても難しい課題になってしまいます。
これに加え、再帰的検索も求められるため、叶えるべき課題は以下のようにいくつも存在します。
- 書き込み元や読み出し先の応答時間や求められる量はバラバラですが、一定以上の速度で応答が必要です
- クエリは怒涛のごとく、どんどん実施され、どんどん応答してほしい
- とあるクエリは他のクエリに依存する場合や依存しない場合があるので、順序を良い感じに返答してほしい
- 余計な待ち時間を最小限にして欲しい
- 元となるデータのフォーマットはバラバラなので、共通フォーマットで応答をしてほしい
- ナドナド。。。。
それらを叶えてくれるデータベース構造はなかなか見当たらず、あったとしてもチューニングがとても難しいです。
なので、CHAGEは、それを叶える構造を作っちゃいました。
その名も ASKS(ASsociated Keywords Salvage)です。
ASKSは、データを持たず、”各データ都合に合わせた検索システム” と連携し、高速に再帰検索を行う仕組みです。
ASKSを用いることで、データ都合ごとに最適化した検索システムを開発することが実現でき、かつ それらを効率的に連携させることが叶っています。
ざっくりとした構成図とすると以下のような感じになります。
ASKS は、どんどん課題を解決しています
ASKSは、検索システムへどんどん検索を連携する事。検索システムの応答結果を再度検索システムへどんどん検索を行います。
検索システムは、自身のデータの特性に合わせた最適な動作を行い、高速に応答だけをします。
これらは連携の際、検索システムは検索結果をどんどん返却し、ASKSは再帰検索をどんどん行うことができる、というとても待ちの少ない基本構造です。
さらっと「どんどん検索」とか言っていますが、ASKSはどんどん検索する際に、返すべき依存関係を解決する必要や優先的に返却すべきものを制御しなくてはいけない状況が生まれます。
例えば、domain iij.ad.jpを検索した結果内のdomain iij.comに対して再帰検索が行われた場合、ざっくり想定しても以下の2つのパターンどちらで動くかわからないので、それらを制御してくれる機能が必要です。
mx iij.ad.jp、host omgi.iij.ad.jpと続き、domain iij.comの検索が行われる場合
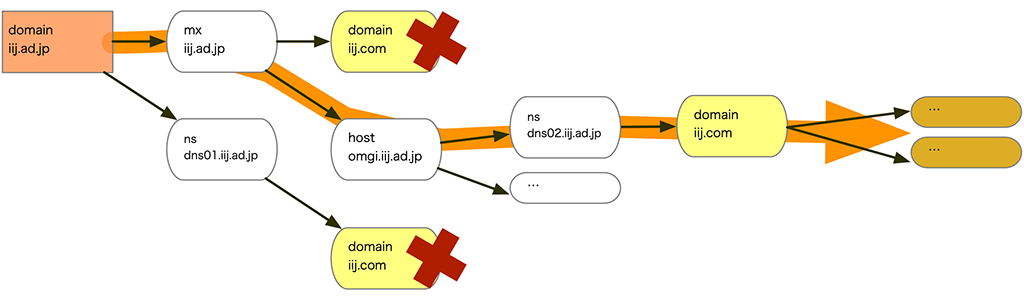
- 最初の検索である、
domain iij.ad.jpの結果からすぐ近くで、domain iij.comの検索が行われる場合

階層の浅いところから順番に検索するようなシステムであれば、必ず、後者のような動きになるので、動きの予想が容易です。
しかしASKSは、応答があり次第「どんどん検索」を行うので、階層の浅い深いは関係がなく、応答が返った順に「どんどん検索」が行われます。
加えてこれらは並列処理なので、どちらのパターンでdomain iij.comの検索を行うかは、スレッドの動作状態やなんらかの待ち状態によって異なります。
要は、どう動くかわかりません。
どう動くかわからないので、状況に応じて、軽いもの(動けるもの) に検索を行わせていく仕組みが必要です。そういった仕組みが無ければ、どこかで検索が滞ってしまいます。
どこかで検索が滞れば、もちろん「どんどん検索」は叶いません。
こういった問題を解決するために、「Owner」が利用する仕組みに、「どんどん検索」を支える工夫がされています。
他にもこういったような課題はいくつかあり、それらを解決するためにASKSは多くの工夫がされています。
今回の記事では、ASKSについてはここまでしか触れず、次回に取っておきたいと思います。
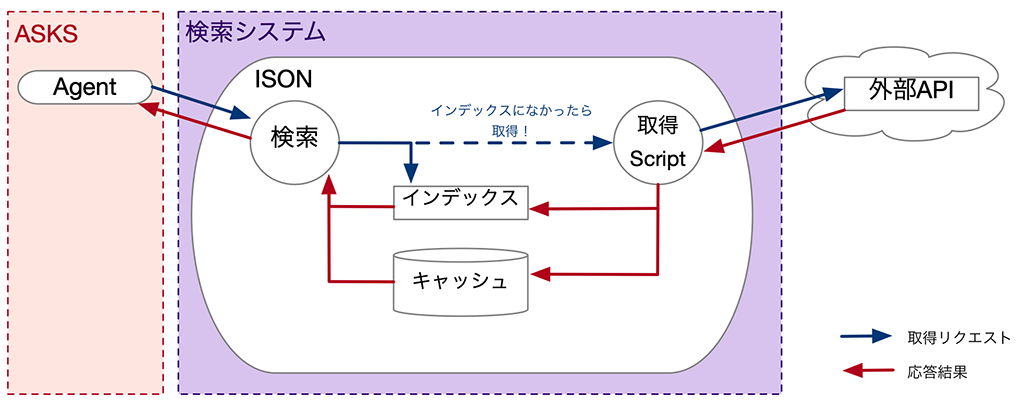
ISON
今回の記事の後半部分では、ASKSが何を連携させるべきなのかというところについて知ってもらうために、検索システムの中で最も工夫されているISONについて具体的に紹介させてもらいます。
ISON (Indexed JSON cache system) は、外部APIサービスに問い合わせを行う役割を持った高速キャッシュ応答システムです。
名前にもある通り、「インデックス」と「キャッシング」が、高速応答と並行処理を支えています。
キャッシング
キャッシュによる高速応答支援
CHAGEの検索は1つでも、一度ASKSの再帰的検索システムに乗っかれば、リクエスト数は数万件単位になります。
外部APIに対して、数秒で数万件のリクエストを行う事は現実的ではありません。
そのため、ISONでは、過去の結果を高速にアクセス可能なキャッシュとして保管し、キャッシュがある場合はキャッシュを返すことで、CHAGEの求める速度で応答することを支えています。
魚拓
これに加え、実はISONのキャッシング機能はCHAGE に価値のあるデータを返すことにも1役かっています。
ここで指し示す価値のあるデータとは、過去の問い合わせ結果です。 この時点までは、この情報があった。といった情報もアナリストが判断する情報として活用できるので、CHAGEにとって価値がある情報です。
それを叶えるために、ISONのキャッシュは有効期限のきれたキャッシュの結果を持ち続けており、あえて古い情報を応答する場合もあります。
保管すべきキャッシュは1リクエスト数世代の保管と、データ量が多いので、ディレクトリエントリ数を下げるため、多階層のディレクトリ構造で、データを保管しています。
この階層は検索しつつ、ディレクトリを辿れるようにするため、インデックスを活用したディレクトリ構造となっています。
インデックス
インデックスの生成
ISON では、価値のあるデータを高速に返答するために、インデックスを有しています。
インデックスとは、本の索引のように欲しいデータの存在する場所を簡単に探すことができる仕組みです。
インデックスから参照できる結果はjson自体と種別 値形式の結果のいずれかを指します。
ISON は、検索結果がキャッシュ上に存在しない場合、キャッシュを保管するだけではなく、同時にインデックスの生成も行なっています。
これにより、ISONは、検索リクエストを受けた際にインデックスを参照し、価値のあるデータを高速に返答する事を支えています。
素早い応答のために
インデックスの検索すら時間が勿体無い
多くのシステムでのインデックスは、インデックスの検索、データへのアクセスという2ステップが取られています。
しかしこれ、インデックスの検索している間は、データへのアクセスを行いませんし、データへのアクセスを行う間は、インデックスの検索を行うわけではありません。
片方の動作が終わるまでもう片方を待つのは、時間が勿体無いです。
より素早く応答するためには、インデックスを検索しつつ、データへのアクセスを行えるような構造が求められてきます。
なので、ISONは、ハッシュインデックスの工夫した活用と、多段ブルームフィルタを用いることで、インデックスを検索しつつ、データ(キャッシュ) へのアクセスが行える構造を開発しました。
多段ブルームフィルタや、高速アクセスについては、CHAGEの裏側: ブルームフィルタとISONの逆引き高速化をご覧ください。
待ち時間の有効活用
ISON は、並列に動作し、待ち時間を無駄にしないように動作しています。
ISONの待ち時間とは何でしょうか。
それは、外部APIへのネットワークI/O待ちと、キャッシュへのディスクI/O待ちが挙げられます。
それらの時間を無駄にしないために、ISONはどんどんリクエストを受け、応答できるものからどんどん応答できる構造になっています。
よく考えられていないシステムの場合、1つの検索を開始し、キャッシュが確認や、外部APIにリクエストの実行と応答待ち、、、と順に処理を行なっていき全てが完了してから、次の検索を行なっていくかと思います。
この、外部APIにリクエストを実行しているネットワークI/O待ちの時間が、大変勿体無いのです。
ISON では検索スレッドを並行処理させることで、ネットワークI/O待ちになったスレッドはコンテキストスイッチされ、キャッシュが存在する対象を読み込ませる時間に活用したりします。
そのため、どんどんリクエストを受け、どんどんスレッドに焚べていき、どんどん応答できるような構造を取っています。
あとメンテナンス性もよいのです
ISONは、内部に外部APIをパースするScriptを持てる構造になっています。そのScriptがキャッシングとインデックス化をISONに則った形で行います。
この構造によって、Scriptを外部APIに合わせて開発するだけで、CHAGEは、特定の外部APIをISON経由で最適に扱えるようにあるので、外部APIの追加コストはとても低いです。
現在、約70種類動作しており、それらは低コストでCHAGEに連携することが叶っています。
ちなみに、ASKSは、ISONと接続するためのASKS Agentが待機しているので、ISONに関連する部分だけで、常時140スレッドほどが稼働している事になります。
さらにこれらはASKS Routerのように何らかの効率化を測るため、パイプライン別スレッドになったりしているので、軽く倍以上のスレッド数が動作していることになります。
これらを効率的に扱うASKSは本当にすごいのです。
これだけ色々考えられているシステムがCHAGEなんですが、一度障害があったんですよ
ISONやASKSのような構造を考え、密に連携させる必要があるため、実装前に問題点を整理しきり、開発、実装しています。
が、思いもよらぬトラブルがあり、CHAGEで障害が発生したことがあります。
CHAGEは、分散型検索システムであり、個々が自由に働けるよう、マルチスレッド化しています。適切なポイントでスレッドをわけ、無駄な待ちを減らし、全力でCPUを働かせています。
常にCPUに働いてもらおうと頑張ったら、32768スレッドを超えていたらしく、新規スレッドが作れなくなり、CHAGEが意図した動作をしなくなりました。
(動作環境でのLinuxは、64Bitなので、デフォルト設定は32768スレッドが上限です。)
デスクトップ環境を動かしたLinuxで300スレッド程度なので、CHAGEがどれだけ切り分けされ、CPUを使いまくろうか努力しているか感じてもらえるかと思います。
ちなみに、現在もチューニングにチューニングを重ね、だいぶ効率化が進んでおり、待機時9511スレッド、検索時13700スレッドほどになっています。全然多いですが。。。。
さて、今回はCHAGEの内部構造をざっくり知っていただき、ISONについても知ってもらうことができたかと思います。
次回は、32768スレッドに分けてまでCPU利用を効率化しようとした、ASKSについて紹介させていただこうと思います。
関連記事
- IIJ内製調査システム CHAGE のご紹介
- CHAGE の動き(本記事です)
- “ASKS” の働き
- “ASKS” と データソースの接続
- “CHAGE” の大切な要素




