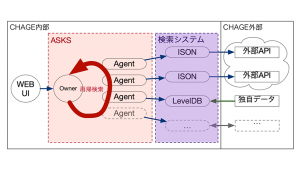
“CHAGE” の大切な要素
2020年02月07日 金曜日
CONTENTS
こんにちは、CHAGE 開発メンバーの くまさか です。
今回は 5つ目の記事で、CHAGE 紹介シリーズ最後の記事です。
今まで 4つの記事にわたり、CHAGE や ASKS、 連携させる MPPP や、データソースのISONについて紹介してきました。
今回は、これらの中身をうまく連携し、利用者のOSINT支援を行うための最も大切な要素を紹介します。
最も大切な要素
最も大切な要素は、全ての構造と関わっているので、実は既に、何度も何度も登場しています。
その要素は、key valueのデータ構造です。
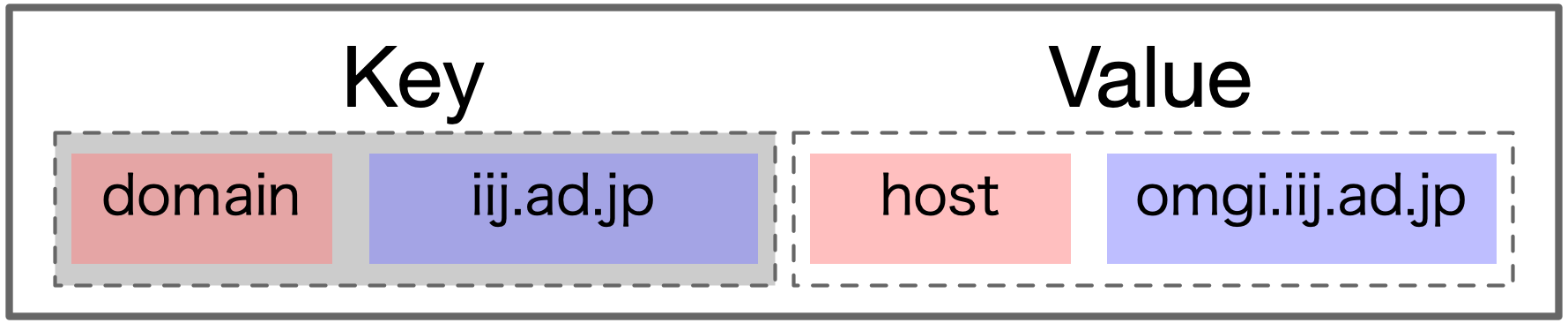
多くの工夫をしている CHAGE の構造で、最も大切な要素がシンプルな key value とは、意外ではないでしょうか。
このシンプルなkey valueを用い、高速に検索し関係性を持たせるためのポイントは 2つあります。
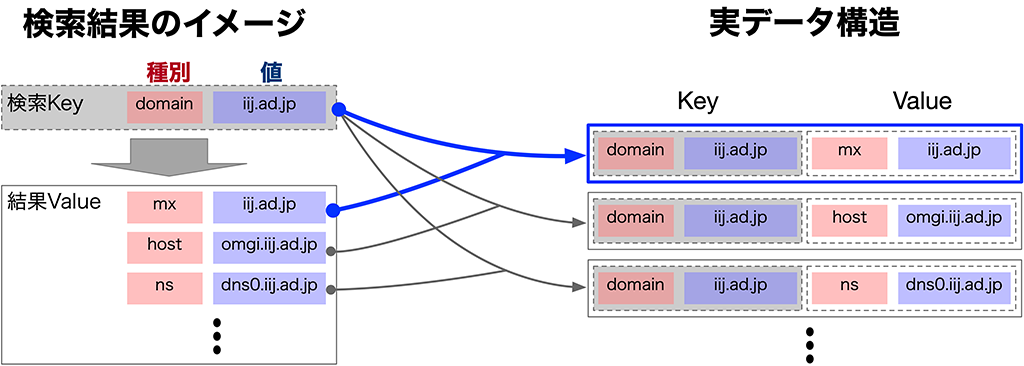
1. key valueのvalueをkeyとして検索できる
既に、CHAGE の動き で紹介している通りです。
「検索Key」から取得できる「結果Value」をそのまま「検索Key」としても利用できます。

2. 「key value」と他の「key value」は独立している
ISON や ASKS Seller で紹介した通り、格納されているデータは、単純な key valueです。
検索Keyに対して検索結果のValueが複数存在する場合も、単純な key value を複数個扱う構造にしています。
そのため、同じ検索Keyの結果同士も、データ構造は独立します。
この2つのポイントにより、key valueは、CHAGE にとって外せない大切な要素となります。
どのようなメリットを与えているかは、この記事では紹介し切れないほど挙げられます。
- データソースを分散型にしやすい
- データソースは自分の担当範囲だけを知っていればよい
- 複数の検索結果を1つずつ処理できる
- 同時に複数の検索 (並列処理) を行いやすい
- データのみで、関係性を表すことができる
- …
1つだけ詳しく紹介します。
データのみで、関係性を表すことができる
これは、key valueのポイント1つ目の「key valueのvalueをkeyとして検索できる」が強く支えています。
valueをkeyとして検索できるということは、valueが関係性を持つべき先を指し示すことができるということです。
この構造により、後から検索結果 (データ) のみで、関係性を表すことができます。
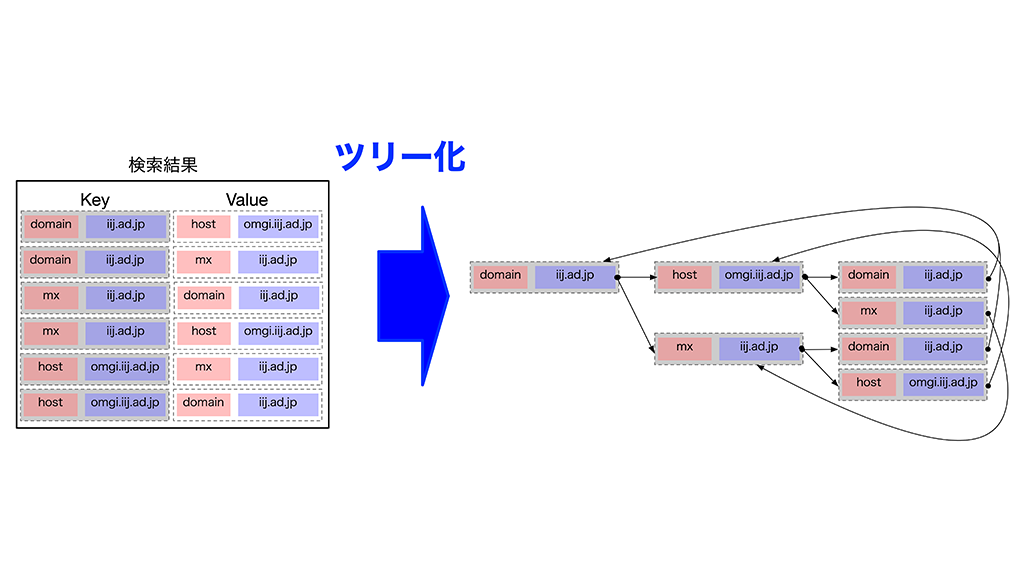
IIJ内製調査システム CHAGE のご紹介 で紹介しているようなツリー化も、一列に並んだ検索結果から関係性を表しています。
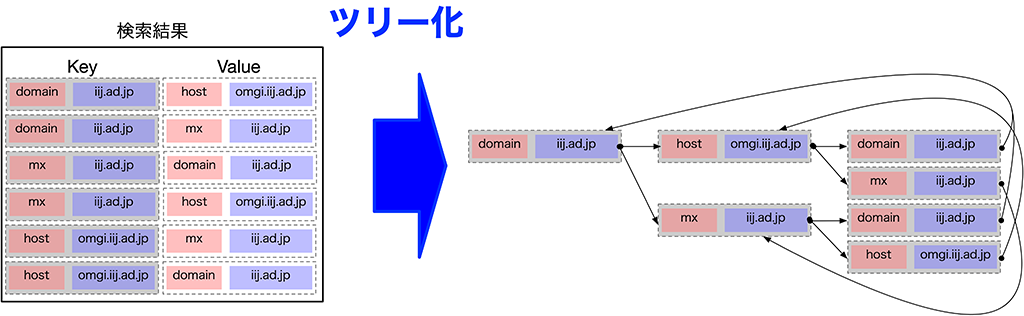
そして、後から関係性を表せるので、検索中は関係性を意識せず、1つ1つの検索に集中できます。
検索が関係性を意識しないことで、データ間の依存度が下がり、CHAGE の並列処理や分散構造を支えています。
例えば、CHAGE の動き で例に挙げた、「再起検索の順序がわからない。」という問題の解決にも一役かいます。
どんな順番で返ってきたとしても、とりあえずデータをため込んで次の検索にいけば良い。 というシンプルな動作を繰り返しても、データは依存していないので、既存の(他の) 検索結果を侵害することがありません。
(検索効率で既に検索したデータを検索しないといった工夫があるので、全く意識しないわけではありません)
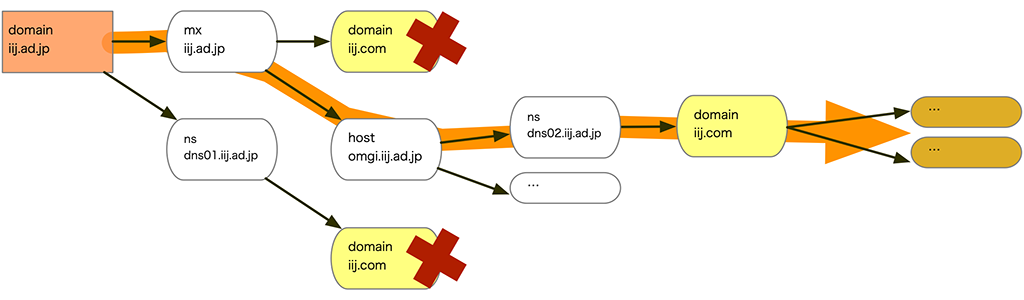
このように、key valueは、シンプルながらもCHAGE の動作効率化や安定性を支え、データに関係性を持たせることも行っています。
そのため、CHAGE の構造を大きく支えている大切な要素です。
Relational Database (RDB) ではない理由
ところで、関係性を持たせたデータを格納するのであれば、RDB システムを用いれば良いとは思いませんか。
第一弾の記事で、「ポピュラーなRDBシステムでは、圧倒的に速度が不足する」と簡単に表現しましたが、速度以外にも問題があります。
具体的に 3つほど紹介します。
- 無制限Join 問題
- 追加 問題
- 無謀な超分散システム
無制限Join 問題
CHAGE は、関係性をどんどん追いかけるシステムです。
追いかけるべき関係性は、利用者の調査次第なので、「どの深さで再起的に検索を行いたいか。」「どの程度関係性をつなげたいか。」は、開発時にはわかりません。
その為、RDBを用いる場合、検索の際に中間テーブルを生成しつづけ、ひたすらにJoinを繰り返さなくてはいけない状況が生まれます。
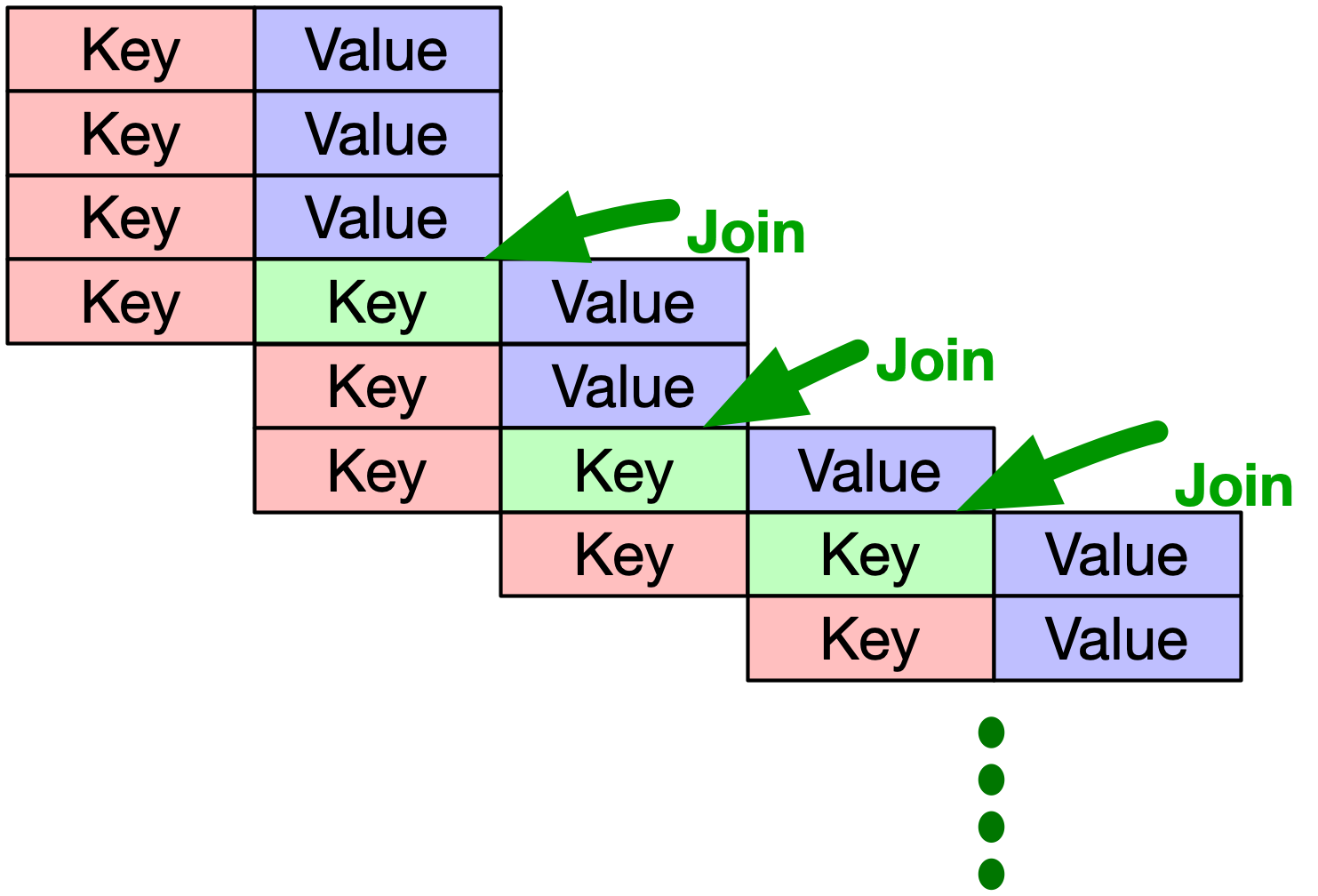
人間が知り合いを辿るだけであれば、6階層もあれば十分と言われています。
そのため、もし CHAGE が、「知人調査システム」であれば、大きな問題にはなりません。
しかし、組み合わされるドメイン名やアドレスは未知数なので、そうもいきません。
予測不可能なとても大きい回数のJoinなど、RDBで実現することはとても難しいです。
さらには、繰り返す度に生成される中間テーブルが大きくなってしまうので、再起回数に比例して、検索のレイテンシ低下や、消費するリソースの増加が懸念できます。
無制限にメモリが使えて、1つの検索に10年ぐらい待てるシステムであれば、何も問題ありません。
しかし、CHAGE が活用される場面では、それほど待つことはできません。
追加 問題
CHAGE は、今まで蓄積したデータと、新しく取得できる外部APIや内製データを混ぜながら、検索結果を構築していくシステムです。
もちろん CHAGE では、新しく取得したデータの関係性も検索します。
新しく取得したデータの関係性を RDBで表す場合、データが追加される度に関係性を再構築する必要が生まれます。
仮に、特定の検索結果中に、新しいデータが Insert (追加) されたとします。
その場合、生成済みの中間テーブルがどれだけ関係性が構築できていようが、再度関係性の構築を行わなくてはいけないので、全てやり直しが発生します。
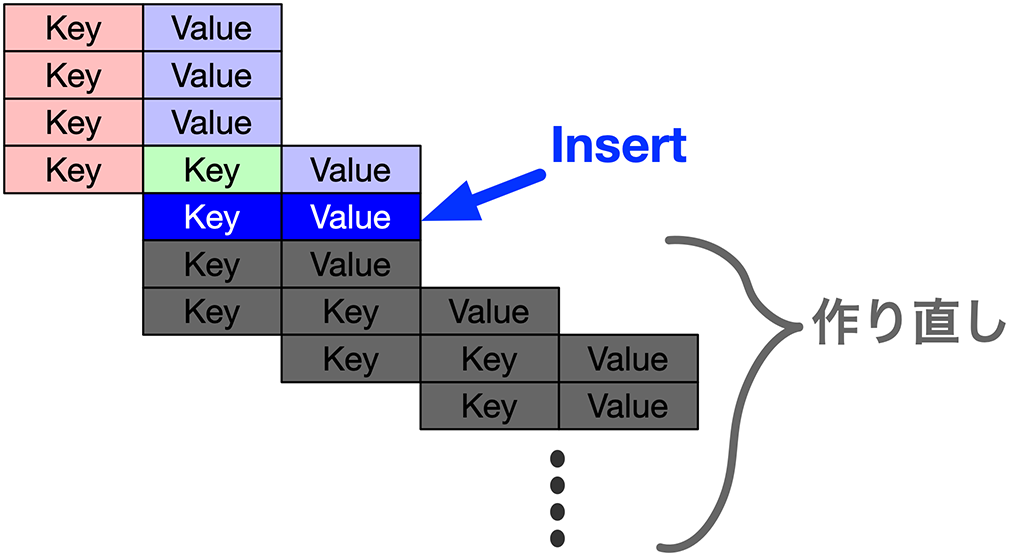
そして、「データの再構築」と「データの追加」は、同期的に行われるので、莫大な時間が必要となります。
人が grep する方が早いのであれば、CHAGE を活用する意味がなくなってしまいます。
無謀な超分散システム
今紹介した、「無制限Join」と「追加」問題に対する RDB での対策があります。
密な関係性を持つデータや、追加されやすい単位でRDBを分けてしまうことです。
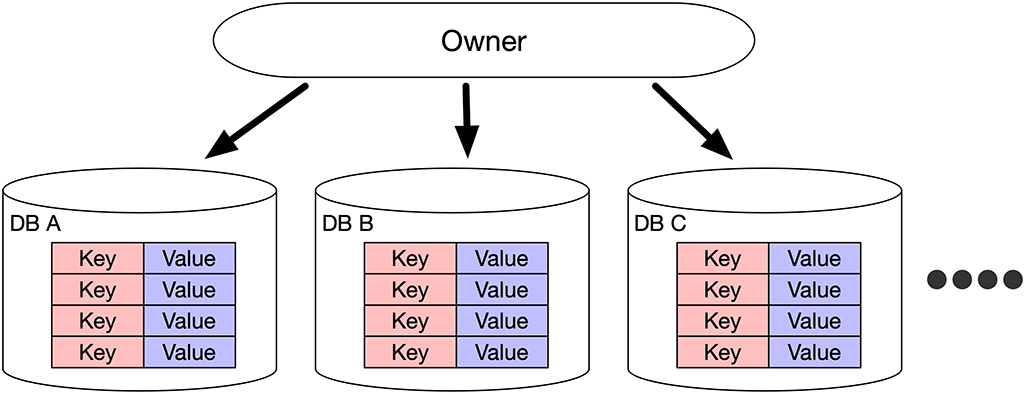
ただ、このような構造にした場合、分けたRDBから出てくるデータの関係性を整理する Ownerが必要となったり、RDB毎の無制限のメモリなどの膨大なリソースが必要となってしまいます。
我々が普段活用するようなコンピュータのリソースは、資金や人の理由で限りがあります。
実現するには、膨大な資金が必要となってしまいます。
紹介したような問題点から、実在するコンピュータで動作させる為には、
- 個々のデータが独立している
- 検索後のデータの関係性を後から構築できる
というようなデータ構造や仕組みが必要でした。
その為、key value のポイントは、問題を解消したデータ構造を設計することにも一役かっています。
CHAGE
さて、今までの記事で様々な CHAGE の構造を紹介し、今回流れるデータがそれらを適切に動作させるための大切な要素であることを紹介しました。
振り返ると、これだけいくつもの工夫された構造が挙げられます。
- IIJ内製調査システム CHAGE のご紹介
- ぱっとみて関係性がわかるツリー の CHAGE WEB UI
- CHAGE の動き
- データソースの1つ。高速に外部APIを活用できる仕組みの ISON
- どんどん検索を行う仕組み ASKS
- “ASKS” の働き
- 再帰検索を支援する仕組み ASKS Buyer
- 複数のマイクロサービスを適切に経路設計する仕組み ASKS Router
- 低いレイテンシで連携する仕組み MPPP
- “ASKS” と データソースの接続
- 様々なデータソースを容易に ASKS に接続する仕組み ASKS Seller
- ASKS Seller を容易に追加する連携構造の ASKS Agent
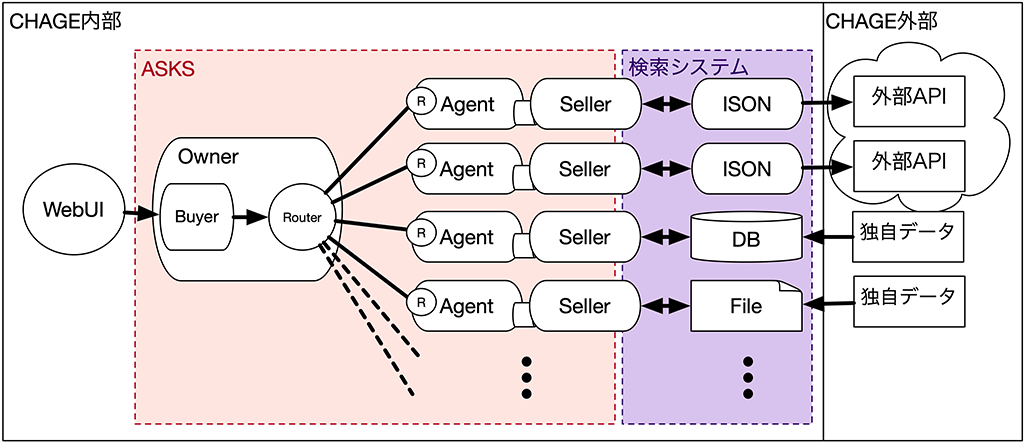
これらの構造は、今までの記事で紹介している通り、バラバラではなく緻密に連携し、動作をしています。
そして、組み合わせでおきるいくつかの問題を、全く同じ key value というデータ構造で解決しています。
複数の問題を1つの構造で解決できるのは、CHAGE が全体を通して設計され、とても精巧な構造となっているからです。
問題の解決を考える際は、問題に近いポイントに目が行ってしまいがちです。
それでは近い範囲のみを解決する方法しか実施できません。
結果、不具合の解決が新たな不具合を生む原因になることや、複数の解決方法の不要な積み上げが発生してしまいます。
CHAGE の設計では、いくつもの問題を全体を通して検討し、最適な解決方法を導き出しています。
その結果、紹介したような多くの問題を1つの構造で解決し、利用者が最も欲しいデータ構造となる結論を導き出せました。
複数の問題解決と、価値のある結果の連携を同じ key valueでおこなっていると考えると、とても精巧に設計 / 開発されたことが感じてもらえるかと思います。
ただ、精巧といっても、必要な機能の効率性を上げることで、汎用的なLinux OS スレッド数の上限にいってしまうまで気がつかないという問題はありましたが(笑) 。。。。
関係性の構築は利用者側に
さて、単純に関係性を持たせられるシステムとして考えると、CHAGE と RDB は比較対象となります。
しかし、「OSINT支援が行えるのか。」という観点では、比較対象にならないことを伝えておきます。
CHAGE は OSINTを支援する仕組みであって、OSINTを勝手に行えたり、白黒出せたりするプログラムではありません。
関係性は利用者が構築するシステムです。関係性を構築する判断や責任は利用者側にあります。
そのため、関係性を持たせる仕組みは、プログラム側ではなく利用者側に位置させる必要があります。
そのような構造にすることで初めて、OSINTを支援するシステムとして動かせます。
RDBは、関係性をプログラム側で構築し、検索効率を支える仕組みです。
そのため、1つのRDBシステムを CHAGE の中身とすることは、とても不適切だったりします。
(既に整ったデータを高速に検索することや、データの関係性を表しておくような使い方ではより良い性能を発揮します。)
つまり、OSINT支援が行えるサービスは、バラバラのデータを利用者がどんどんつなぎ合わせていく事で価値を生み出せます。
これが、CHAGE のデータ構造を 独立した key value としている理由でもあります。
今回は、CHAGE の最も大切な要素を紹介するとともに、大切な要素であるkey valueを紹介しました。
key valueによって、CHAGE や ASKS、ISON を連携する問題点が解消され、利用者へのOSINT支援を実現できていることを知ってもらえたのではないでしょうか。
第一弾の記事で CHAGE という存在を知った時に、入力する「domain iij.ad.jp 」が、CHAGE を精巧に設計したことから決定した入力方法と想定した人は、少ないと思います。
これほど隅々まで設計が行き届いているシステムが、 CHAGE なのです。
本記事をもって、CHAGE の紹介シリーズは、全て終了となります。
このシリーズを通して、精巧に設計 / 開発された CHAGE の魅力を知っていただけたらありがたいです。
ご愛読ありがとうございました。
本シリーズと、技術をちょっと濃い目に紹介する企画「CHAGE の裏側」シリーズ は、chage のタグ に格納されています。
関連記事
- IIJ内製調査システム CHAGE のご紹介
- CHAGE の動き
- “ASKS” の働き
- “ASKS” と データソースの接続
- “CHAGE” の大切な要素(本記事です)