CHAGEの裏側: LevelDBでの並列化用の最適化
2020年01月23日 木曜日
CONTENTS
CHAGE開発者のヒラマツです。
CHAGEの紹介と並行して、CHAGEの中が気になる人に、CHAGEで使われている技術をちょっと濃い目に解説するという企画の4回目です。
本編がSeller紹介な記事なので、その中の一つ、LDB Seller(LevelDBを利用するSeller)を取り上げます。
並列処理とKVSの組み合わせによる性能問題と、その対策を説明し、その後、対策の実例として、LDB Sellerでの最適化方法を紹介します。
目指すのは、実例を通して、プログラムの最適化でも「システム全体を意識することが重要なことを感じてもらう」ところです。
以下の知識を前提にしているので、ご了承ください。
- レイテンシの影響の大きさ
- レイテンシがとても大きい話は、前回のCHAGEの裏側に書いてあるので、省略します。
- KVS(Key-Value Store)
- 選ぶのに困るぐらい種類があります。
- Redis、memcached、LevelDB、RocksDB、Berkeley DB、CDBなど
- 選ぶのに困るぐらい種類があります。
- LevelDBの概要
- LevelDBはGoogle製のライブラリとして使うKVSです。LSM-Treeな構造で、Writeの速さが特徴的です。
- google/leveldb@GitHub
- LevelDB Benchmarks
- シリアライズ(直列化、Serialization、Marshalling)/デシリアライズの概念
- ネットワークやストレージで扱えるように、アプリケーションのデータとバイト列を相互変換する処理のことです。
- CHAGEでは主にMessagePackを使ってます。
- 負荷集中時の性能劣化の概要
- 負荷が高すぎると、無駄が増えて負荷以上に遅くなります。
- ネットワークが輻輳で使えなくなるとか
- 1つのファイルを同時にアクセスしたためにプログラムが固まるとか
- 大量プロセス起動でシェルが入力に反応しなくなったりとか
- 負荷が高すぎると、無駄が増えて負荷以上に遅くなります。
この文章で利用する略語について説明します。
CHAGEでは、アプリケーションとしてKey-Valueを扱っていて、その中で、KVSでのKey-Valueの話が混在すると、どちらか区別できなくなります。
そこで、この2種類のKeyとValueを区別するために、以下のように略します。
- アプリケーション上の論理的なKeyをAP-Key
- アプリケーション上の論理的なValueをAP-Value
- KVSに保存される物理的なバイト列のKeyをDB-Key
- KVSに保存される物理的なバイト列のValueをDB-Value
並列化で起きる問題
まずは、最適化の要因になった、並列処理とKVSの組み合わせによる性能問題について、段階的に説明していきます。
ふつうにKey-Valueする方法
前提となる、最適化される対象の、KVSへKey-Valueなデータを入れる方法についての話です。
KVSはシンプルな仕様であることが多いので、KVSのDB-KeyとDB-Valueが1:1な関係になってることも多いです。 (LevelDBもDB-KeyとDB-Valueが1:1な関係になってます。)
でも、アプリケーションでは、ふつうに1:Nな関係のデータを扱いますし、状況によっては、N:Mな関係のデータも出てきます。 (CHAGEのかなり単純なデータ構造でも、AP-KeyとAP-Valueが1:Nな関係になってます。)
KVSを使うために、アプリケーションで、1:1な関係のデータしか扱わないというのは、かなり無理な話です。
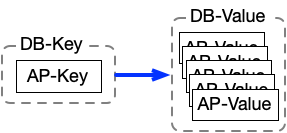
ということは、しばしば、KVSとアプリケーションで、以下の図のように構造が一致しません。
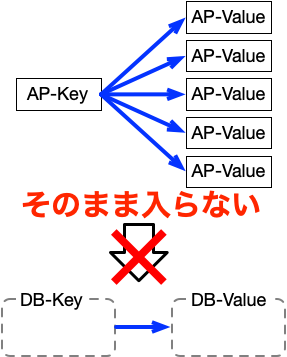
この状態だと、アプリケーションのデータは、そのままでは、KVSに入りません。
しかし、シリアライズを使えば、複雑なデータを1つのバイナリデータへ変換できます。
ということは、以下のように1つのDB-Valueに複数のAP-Valueが入ります。
このシリアライズを使う方法で、AP-Keyを使ってAP-Valueを取り出す処理の流れが以下の図です。
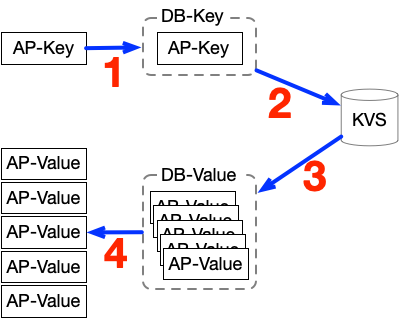
図の中で番号をつけた各工程は、以下のような内容です。
- AP-KeyをDB-Keyにシリアライズする
- DB-KeyでKVSを検索する
- 検索結果としてDB-Valueを受け取る
- DB-Valueをデシリアライズして、複数のAP-Valueに変換する
この方法ならば、KVSの入出力前後でシリアライズ処理を入れるだけなので、シンプルに実装できます。
とても一般的ですし、わかりやすい簡素な方法でもあるので、以降、この方法を簡素方式と略します。
簡素方式の負荷
簡素方式は、構造上、処理がすべて終わるまでAP-Valueを送信せず、処理終了後にまとめて送信します。 この送信処理の特性から、AP-Valueの数が増えるに伴って以下のような変化をします。
- 処理の時間が増えて、レイテンシが増加
- 一度に送信されるデータ量が増えて、通信負荷が増加
この処理と負荷の関係を、シリアライズの「プロセス」、KVSの「ストレージ」、「通信」に分類して、簡易な図にすると以下のようになります。
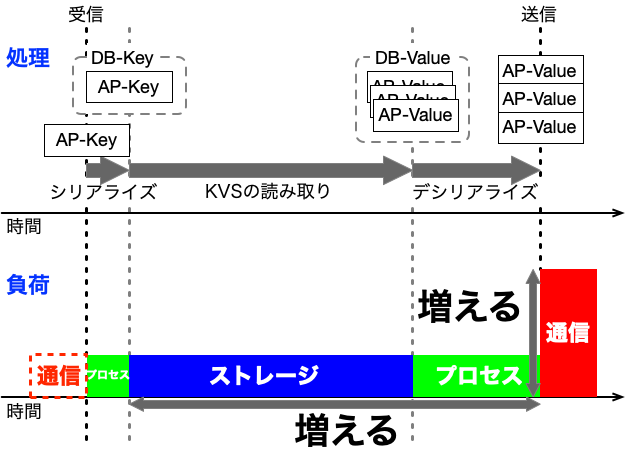
この負荷の関係を通信の影響について整理すると、以下のようになります。
- AP-Valueが増えると、送信データが増える
- AP-Valueが増えると、処理時間が長くなって、送信タイミングが遅れる
影響とは言っても、データ量に比例して通信も処理も遅くなるという当たり前のことです。
構造がわかりやすいことを考慮すると、一般的には、簡素方式は好ましいと言えます。
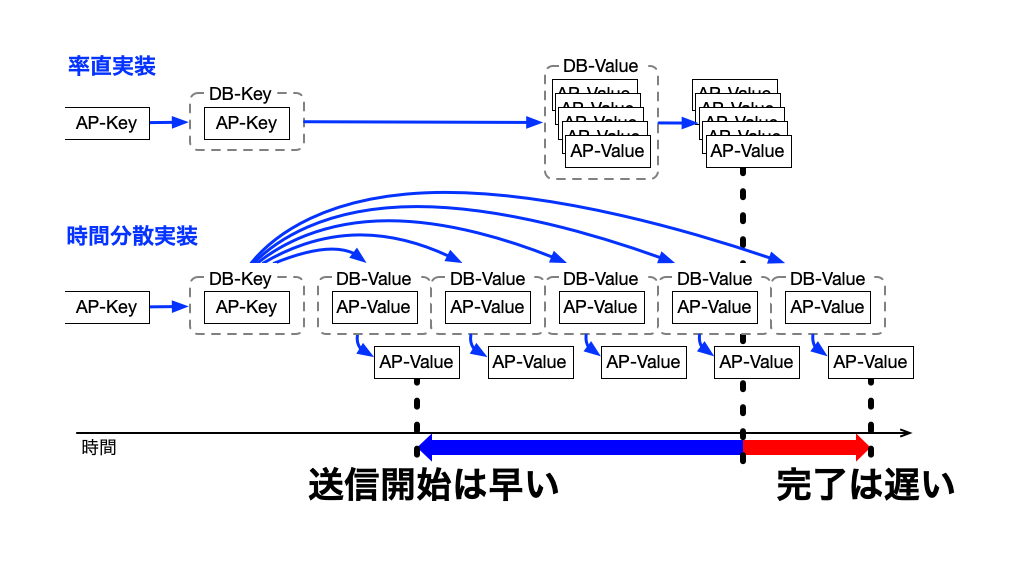
簡素方式を並列化した場合
好ましかったはずの簡素方式ですが、並列化すると、条件によってはひどい性能劣化を起こします。
この性能劣化は、簡素方式の特性に起因しているので、簡素方式の特性と性能劣化の関係について、説明します。
先ほどの負荷の関係の図から、通信負荷だけ取り出すと以下の図のようになります。

この通信負荷の形が原因となって、問題が起こります。
原因となる様子をわかりやすくするために、単純な「AP-Valueを3つ送信する処理を、再帰的に3回ほど実行する」状況で、並列化した時の負荷を考えます。
この時の動作は、以下のような内容になります。
- 入力された1つのAP-Keyで変換処理が実行される。3つのAP-Valueが作られる。
- 3つのAP-ValueをAP-Keyとして、変換処理が3並列で実行される。9つのAP-Valueが作られる。
- 9つのAP-ValueをAP-Keyとして、変換処理が9並列で実行される。27つのAP-Valueが作られる。
この動作の通信負荷を単純に足し合わせた図が、以下のものです。
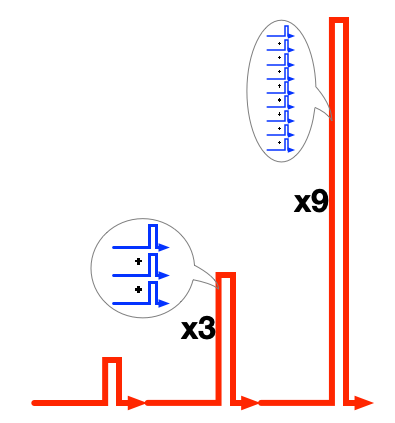
この図だけでも負荷の酷さは伝わりそうですが、このような負荷の集中が起きてしまう理由は、結果が一斉送信されることで、次の処理のタイミングまで揃うからです。
処理のタイミングが揃ってしまうので、3回の繰り返しで、局所的な負荷が9倍に、繰り返しをさらに1回増やすと、27倍もの負荷になります。
(ちなみに、CHAGEでは、AP-Keyに対するAP-Valueが100個以上あることも普通なので、もっと厳しい負荷になります。)
そして、この通信負荷がきっかけで、通信負荷以上の性能劣化の問題が起こります。 それは、以下のような状況の連鎖が発生するからです。
- 複数の結果が一斉に送信される。
- 受信のタイミングも揃うので、受信後の処理が同時に動作する。
- 複数の処理が同時に動作するので、複数処理分の送信が同時に行われる。
- 2,3の繰り返しで、同じタイミングに処理が重複していくので、通信負荷が加速的に集中していく。
- 先ほどの通信負荷を足し合わせた図のような状態
- 通信と受信処理は連動するので、通信以外の負荷も集中していく。
- 4,5の組み合わせで、いろいろな負荷が加速的に集中していく。
- 波打つようなムラがある負荷になる
- 集中した負荷の前後は、逆に暇がある
- 加速的な負荷の集中により、何かしらのリソースで、すぐ限界を超えて、局所的な過負荷状態になる。
- 局所的でも過負荷状態ではあるので、処理効率が大きく低下する。
このような状況の連鎖が起こるので、簡素方式は、並列化した場合に「余力を残したまま、性能が限界に達する」という無駄が多い状況を起こしやすいのです。
そして、これが、並列処理とKVSの組み合わせによる性能問題になります。
最適化の方針
性能問題を説明したので、次にその問題への対策について説明します。
簡素方式で性能が伸びなくなるのは、そもそも、複数のAP-Valueをまとめて処理することが原因です。 逆に言えば、AP-Valueをまとめて処理しなければ回避できます。
要するに、「複数あるAP-Valueを1つずつ読み取りながら、順次にさっさと送信」すれば、改善できます。
この改善策を図すると以下のようになります。
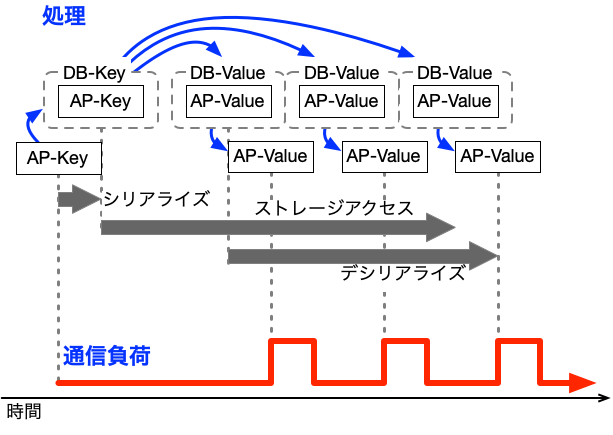
以降、この方式を時間分散方式と略します。
そして、この時間分散方式の効果(メリット)は、負荷が分散することも含めて、以下のように複数あります。
- 負荷が時間で分散する
- 次の処理が早まる
- 負荷を自動調整する
わかりにくいので、これらの3つの効果を順番に説明します。
1. 負荷が時間で分散する
簡素方式で起きていた問題は、分散したのですから解決するわけですが、どのように改善したかを一応確認します。
時間分散方式で「AP-Valueを常に3つ送信する処理」を繰り返した場合について、通信負荷を合成してみると、以下の図のようになります。(繰り返し回数を増やすとわかりにくくなるので、2回分だけの重ね合わせです。)
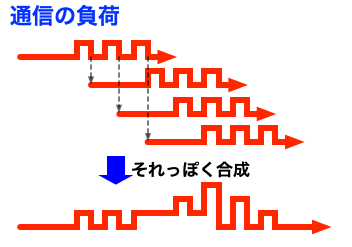
このように、負荷が時間方向に分散することで、負荷のピークが低くなります。もちろん、繰り返せば負荷は増えますが、簡素方式と比べ、その増え方もかなり緩やかです。
この効果で、システム全体での負荷の限界が高くなります。
2. 次の処理が早まる
簡素方式と時間分散方式の送信処理を、比べるために並べたのが以下の図です。
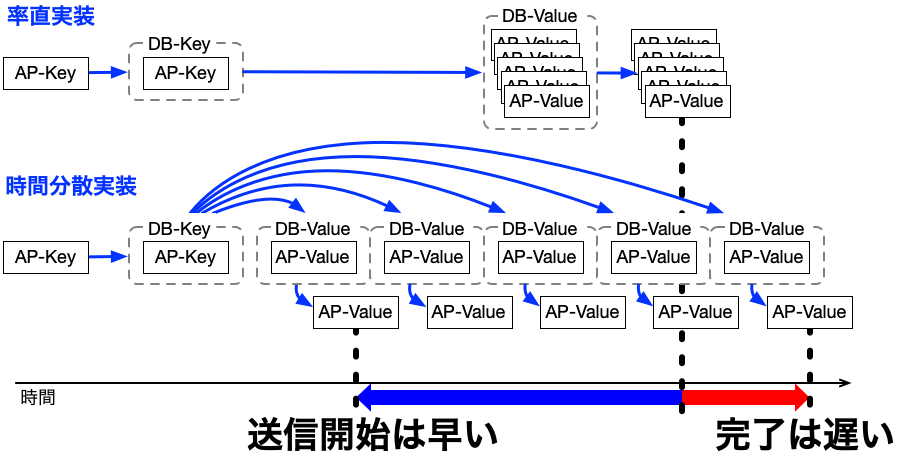
図からもわかりますが、簡素方式を時間分散方式に変えると、以下のような違いが生まれます。
- 送信タイミングは早くなる
- 最初のAP-Valueだけでなく、平均の送信タイミングも早くなる。(おそらく半分以上が早くなるので)
- 処理の工程は増える。結果的に処理も長くなる
- 処理が細かく分かれるので、手順が増えて、プログラム単体では遅くなります
まずは、送信タイミングが早まるので、次の処理の着手が早くなり、システムの反応も良くなります。
この効果で、レイテンシが短くなります。
その上、動作タイミングが早まると、簡素方式では使えなかったリソースが活用されるようになります。
この効果で、高負荷時は、リソースの利用効率が上がって、スループットが増えます。
3. 負荷を自動調整する
時間分散方式は、負荷の変動に連動して、送信間隔が以下の図のように変わります。
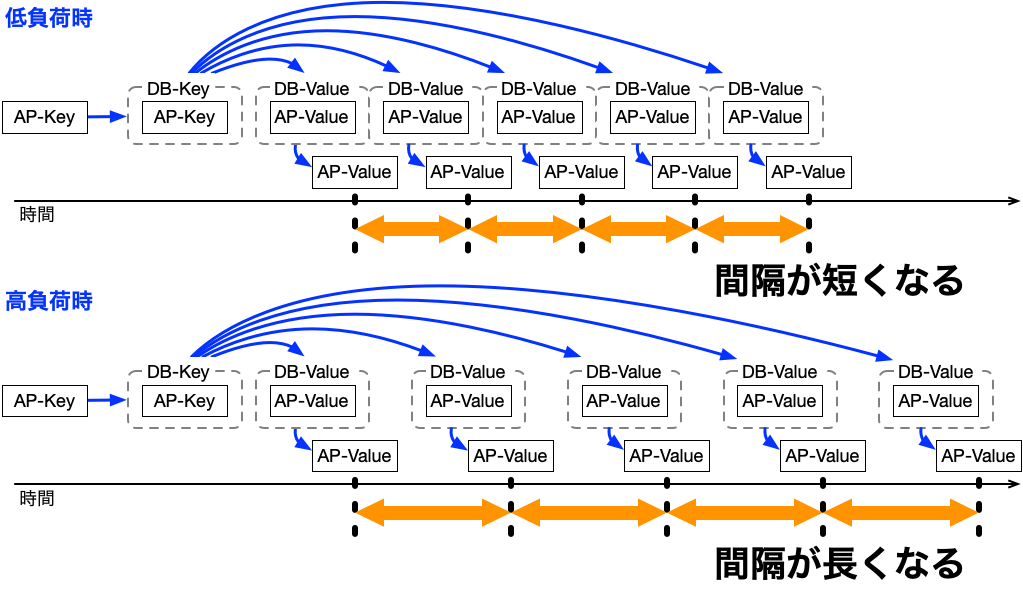
負荷が増えると送信間隔が伸び、負荷が減ると送信間隔が短くなります。
送信は次の処理を呼び出すので、次の処理の実行頻度も変化するので、以下のようなことを起こします。
- 負荷が高い → 次の処理の呼び出しが減る → 後の処理での負荷が減る
- 負荷が低い → 次の処理の呼び出しが増える → 後の処理での負荷が増える
この反対向きの動きは、システムが限界に近いと負荷を減らし、余裕だと負荷を増やす働きをします。 この働きは、過剰な負荷を抑え、効率的な負荷を維持する動きになるので、結果的に負荷を自動調整するように機能します。
そして、この効果で、システムの過負荷や負荷のムラが軽減するので、負荷変動による処理効率の低下が抑えられます。
時間分散方式の効果
時間分散方式の3つの効果を説明しましたが、高負荷時に限定すると都合が良いものばかりでした。
その結果、高負荷時は、負荷の限界が上がり、レイテンシが短くなり、スループットも増えて、処理効率の低下も抑えるので、システム全体の性能が上がります。
(システム全体で同様な最適化を徹底できると、負荷をかけても、滑らかに動くようになります。)
残る問題は、プログラム単体が遅くなったことによる、低負荷時の性能低下です。 ただ、低負荷だと処理データが少なく、もとの処理時間自体も短いです。
ということは、処理時間が多少伸びても、そもそも大した問題になりません。
このように、時間分散方式は、十分な並列化を前提とすると、デメリットの少ない、高負荷向けの安定感のある最適化になります。
これで、簡素方式で起こる性能問題に対して、時間分散方式が対策になることが説明できました。
そして、並列化しまくってるCHAGEには、とても都合がよい最適化でもあります。
LevelDBでの実現方法
対策については説明できたので、より具体的に、CHAGEでの、LevelDBを使った時間分散方式の実現方法について説明します。
とても都合がよく見える時間分散方式ですが、性能を出すためには、ストレージの特性を活かした「AP-Valueを1つずつ取り出せる仕組み」が必要となります。
このために、LDB Sellerでは、LevelDBに合わせて工夫をすることになるので、その工夫の説明でもあります。
LevelDBの特性
LevelDBは、DB-KeyとDB-Valueの関係が1:1です。 そのため、時間分散方式を実現するには、何かしら工夫が必要となります。
効率がよい最適化にしたいので、工夫を考える前に、まずは、基本的な性能について調べました。
以下は、LevelDBの機能間における速度を比較するために、ベンチマーク結果「Baseline Performance」の測定データからLevelDB分のみで作ったグラフです。
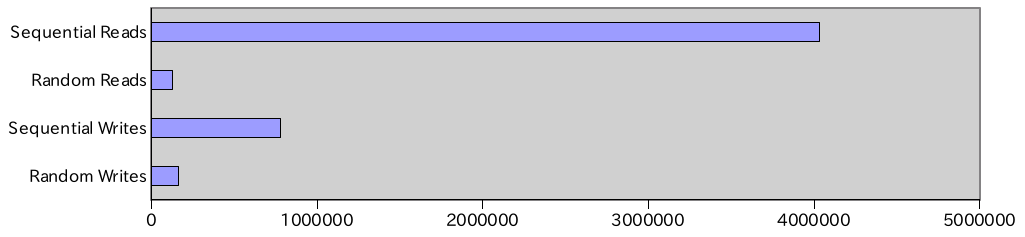
Sequential Readsで飛び抜けて速い結果が出ています。(Random Readsの31倍、Sequential Writesの5倍、Random Writesの24倍ぐらい)
そこで、「Sequential Reads」の処理について、ベンチマークのコード(db_bench.cc)を調べてみると、LevelDBのIteratorの機能が使われていました。(他の項目のベンチマークのコードでは、Get、Putを使っています。)
このIteratorは、DB-KeyとDB-Valueの組み合わせを、DB-Keyのソート順に取り出す機能です。
以下の図は、動きの違いをなんとなくわかってもらうために、連続する要素を取得する処理の、GetとIteratorの動きの違いを大雑把に書いたものです。
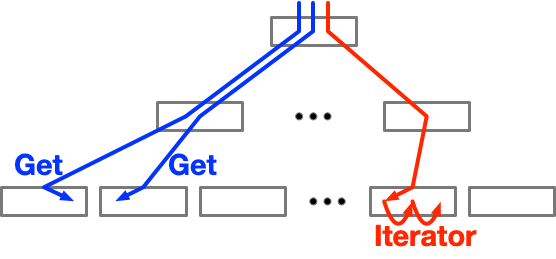
このように、連続する要素を取得する場合、DB-Key毎に毎回検索する「Get」と、隣の要素をたどる「Iterator」で、動きが全然違います。
この動きの違いで、Iteratorを使うとアクセスが減るので、かなり効率が良くなります。 だから、ベンチマークの「Sequential Reads」も速かったのです。
Iteratorの活用
必要なLevelDBの特性が説明できたので、最適化でのLevelDBの活かし方の話になります。
Iteratorの特性から閃いたのが、以下の図のように、DB-Valueを使わず、DB-Keyのみを使う構造の工夫です。

DB-Valueは空で、AP-KeyとAP-Valueの両方をDB-Keyに入れた構造になっています。
この構造のDB-Keyを使うと、AP-Keyが同じデータはソート順が近くなります。
その結果、AP-Keyが同じデータは隣り合った領域に保存され、Iterator機能で順番に取り出せるようになります。
ただ、「Sequential Reads」のベンチマークのように、先頭から検索したのでは遅くなるので、AP-Keyが同じデータだけを読み出すようにしました。
具体的には、IteratorのSeek処理とNext処理を利用して、AP-Keyに先頭一致するデータのみを検索しています。 以下の図のように、Seek処理で先頭のデータを見つけた後、Next処理で順番にデータを出す動作になります。

後は、AP-Valueの取り出し処理と送信処理を追加すれば、以下のような手順になります。
- AP-Keyが一致する、先頭のデータを探す。(Seek処理)
- 探したデータがなかった場合は、終了する。
- 見つけたデータからAP-Valueを取り出して、送信する。
- 次の順番のデータを探す。(Next処理)
- 2.に戻る。
この方法で、LevelDBを使って時間分散方式の処理が実現しました。 Iterator機能のおかげで、それほど遅くならずに、そこそこシンプルな処理になっていると思います。
もちろん、実際に、時間分散方式の特性が発揮され、負荷をかけても滑らかに動くようになってます。
プログラムの最適化
始めに触れた「システム全体を意識することが重要なことを感じてもらう」を説明します。
いろいろなソースコードを読んでいると、「プログラム単体の能力をあげる」ことを目指したソースコードにそこそこ遭遇します。 残念ながら、私も、無意識にそんなソースコードを書いてしまうことがあります。
無意識にそんなソースコードを書いてしまう理由は、プログラムの最適化として、以下のような変更をすることが比較的多いからです。
- プログラムの負荷をより小さくする
- プログラムの処理をより速くする
- プログラムの使用メモリをより少なくする
これらの「プログラム単体の能力をあげる」変更は、多くの場合、システムも改善するので、慣れてくると習慣になりがちです。
でも、その変更でシステムが遅くなることも、そこそこあります。 そして、今回解説した最適化のように、プログラムを遅くすることで、システムが速くなることすら起こります。
プログラムの最適化は「プログラム単体の能力をあげること」ではないので、このようなズレが起こります。
求められているのは「(システムにとって)最適な状態に近づく変化を起こす」ことです。
それを意識せずに、システムへの考慮が不足すると「プログラムを速くして、システムが遅くなる」ことが起こるわけです。
そんな「システム全体を意識することが重要なことを感じてもらう」ために、私への反省もこめて、遅い最適化を紹介しました。
ぜひ、たまに、遅い最適化もしてみてください。
「CHAGEの裏側」の舞台裏
「CHAGEの裏側」の企画は、実は今回が最後です。
最後なので明かすと、「CHAGEの裏側」の裏テーマは、システム開発の雰囲気をちょっと知ってもらうことでした。
システム開発をうまく進めようとすると、いろいろと調べたり考えたりすることになります。
このいろいろ考える雰囲気を少しでも伝えたくて考えたのが、以下のような「CHAGEの裏側」の構成です。
- コーディングに関する話「D3.jsの紹介」
- プログラミングの技法の話「ブルームフィルタとISONの逆引き高速化」
- アーキテクチャの話「レイテンシに呪われないQAQの世界」
- プログラムの最適化の話「LevelDBでの並列化用の最適化」(今回)
いろいろ考える雰囲気が伝わるように、できるだけ異なる工程から題材を選んだつもりです。
少しはシステム開発の雰囲気が伝えられたでしょうか?
CHAGEの裏側はこれで最後ですが、CHAGEシリーズの本編はまだ続きますので、そちらもぜひ読んでください。
(1月下旬~2月上旬の公開予定)