CHAGEの裏側: ブルームフィルタとISONの逆引き高速化
2019年10月29日 火曜日
CONTENTS
CHAGE開発者のヒラマツです。
前回(CHAGEの裏側: D3.jsの紹介)同様、CHAGEの紹介と並行して、CHAGEの中が気になる人に、CHAGEで使われている技術をちょっと濃い目に解説するという企画です。
今回は、本編(CHAGE の動き)がISONネタなので、こちらもISONに関係ある話として、ブルームフィルタについて書きます。
ブルームフィルタをざっくり解説してから、ブルームフィルタの具体的な使用例としてISONでの逆引き高速化の方法を紹介していきたいと思います。
目指すのは、ちゃんとした理解ではなく、「ブルームフィルタの雰囲気を知って、利用価値をなんとなく判断できる」ところです。
今回は、以下の知識を前提にしているので、そこはご了承ください。
- プログラムによる、ディレクトリやファイルの基本的な操作
- ハッシュ関数
- プログラムだと、ハッシュテーブルで使われてるのが身近ですかね。
- 暗号化の話では、SHAシリーズのハッシュ関数とか、ふつうに出てきますよね。
- ビット演算
- ビット配列(bit array, bit map, bit vector他)
- Bit array@英語版Wikipediaは存在する。ビットフィールド@Wikipediaにサラッと出てくる。
- ビットをコンパクトに保存した配列です。要はビットを詰めて並べたデータで、ビット演算を駆使して読み書きします。実質、1バイト当たり8ビットの情報が入るので、コンパクトになります。(日本語解説が見つからないので、適当に書きました。)
ブルームフィルタ
ブルームフィルタ(Bloom filter)は、本質的には「入力値から、処理の必要性を低コストで判断する」仕組みです。
ブルームと付くのは、Burton H. Bloomさんが考案したからです。そして、無駄な処理を削減するために使うので、フィルタなわけです。
ブルームフィルタは、いろいろな工夫が存在するので、種類も複数あります。 全部を説明するのは難しいので、わかり易さ重視で、この文章では、もっとも単純なブルームフィルタだけ説明します。単純とはいえ、ISONで使ってるので十分に実用的です。
(わからなくて良いのですが、一応書くと、ハッシュ関数が1つ、カウンタも使わないブルームフィルタです。)
単純なブルームフィルタ
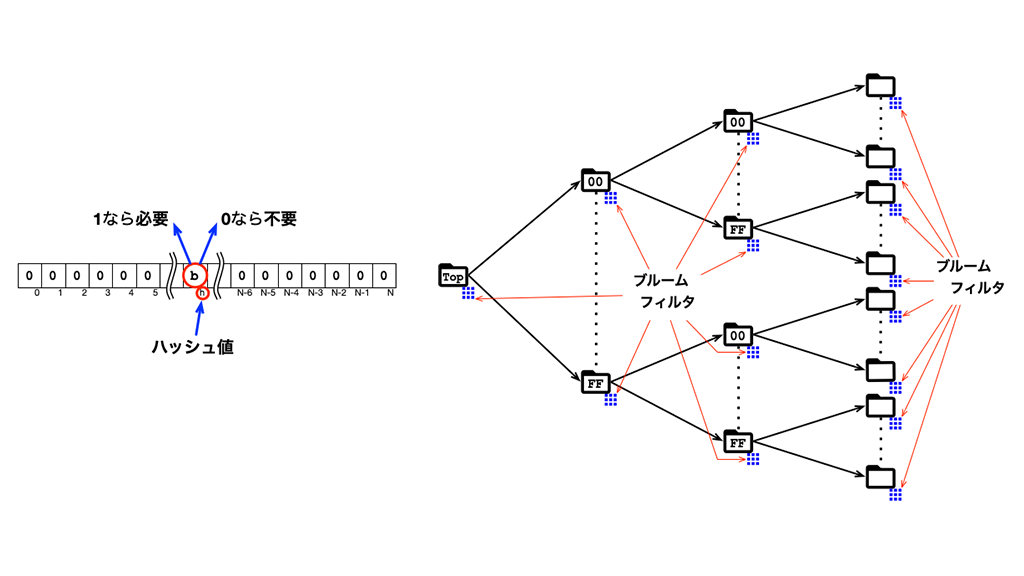
この単純なブルームフィルタは、判断結果をビット配列へ保存しています。ハッシュ値をビット位置として扱うことで、入力値の形式に縛られずに、判断結果の保存を可能にしています。
そして、以下の図のように、準備時に「判断結果をビット配列に保存」しておいて、判断時に「ビット配列から判断結果を取得」することで動作します。
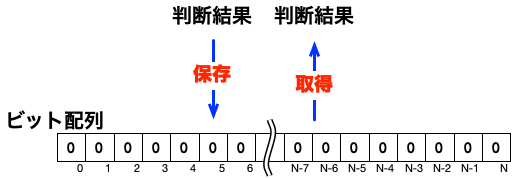
以下で、この「準備」の処理と「判断」の処理の中身を説明していきます。
ブルームフィルタの準備
まずは、「準備」の処理の説明をします。 準備の処理では、ビット配列を用意し、以下の図のようなハッシュ値のビット位置に1を書く処理を必要なだけ繰り返します。
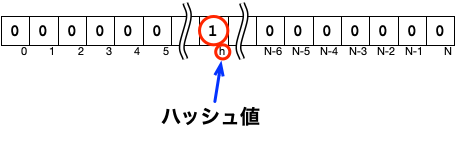
手順にすると、以下のようになります。
- (0で)初期化したビット配列を用意する。
- 処理が必要な入力値をハッシュ値を計算する。
- 計算したハッシュ値を添え字に、ビット配列のビットを1に設定する(設定されないビットは0)。
- 2.と3.の処理を必要なだけ繰り返す。
ブルームフィルタの判断
残る「判断」の処理ですが、以下の図のように、ビット配列のハッシュ値の位置を読み取って、判断結果とする処理です。
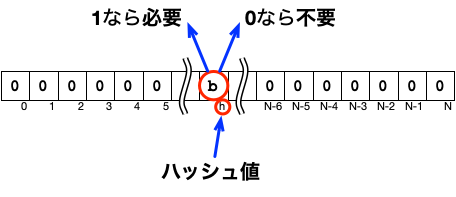
手順にすると、以下のような処理になります。
- 入力値のハッシュ値を計算する。
- 1.で計算したハッシュ値を添え字に、ビット配列からビットを取り出す。
- 2.で取り出したビットが、1なら「処理が必要」、0なら「処理が不要」と判断する。
ブルームフィルタのサイズ
処理の中身は説明しましたが、現実は容量にも限界があるので、データサイズの話をします。
ちょっと不思議かもしれませんが、ブルームフィルタは、ハッシュ関数がサイズを決めています。
ブルームフィルタのデータはビット配列だけなので、ブルームフィルタのサイズは、ビット配列のサイズで決まります。
そのビット配列はハッシュ値を使ってアクセスしますから、ハッシュ値の範囲がビット配列のサイズを決めます。
そして、そのハッシュ値の範囲はハッシュ関数の特性が決めるわけですから、結果的に、ハッシュ関数がブルームフィルタのサイズを決めるのです。
ハッシュ関数とサイズの関係がイメージしやすいように、ハッシュ関数で作られる「ハッシュ値のbit数(範囲)」と「ビット配列のサイズ」の組み合わせをいくつか選んだのが、以下のリストです。
- ハッシュ値が8bit(範囲は0~255)だと、32B(256bit)のビット配列が必要(かなり小さい)
- ハッシュ値が16bit(範囲は0~65535)だと、8kB(64kbit)のビット配列が必要(小さい)
- ハッシュ値が24bit(範囲は0~224-1)だと、2MB(16Mbit)のビット配列が必要(まだ余裕)
- ハッシュ値が32bit(範囲は0~232-1)だと、512MB(4Gbit)のビット配列が必要(なんとか)
- ハッシュ値が48bit(範囲は0~248-1)だと、32TB(256Tbit)のビット配列が必要(たぶん無理だね)
- ハッシュ値が64bit(範囲は0~264-1)だと、2EB(16Ebit)のビット配列が必要(無謀)
利用する状況によりますが、32bit前後ぐらいに現実的な限界がありそうですよね。ふつう、2EBのサイズは保存も困難なので、容量も考慮して、ハッシュ関数を決めないとなりません。
というわけで、ビット演算や剰余演算などを駆使して、ハッシュ関数を調整するのが現実的です。
ブルームフィルタの単純な例
ブルームフィルタ自体はざっと説明できたので、次は、ブルームフィルタの使い方を、単純な例を使って説明していきます。
例として「ユーザIDで、ユーザ情報のDBを検索する」処理を考えます。
この処理の場合、「存在しないユーザ」にデータは存在しないので、「存在しないユーザ」でDBで検索しても意味がありません。 存在しないユーザの検索を省略できれば、DBの負荷が下がり、処理時間も短くなります。ということで、ブルームフィルタの出番です。
これ以降の説明では、計算式の剰余演算子の表現に%を使います。(プログラミング言語では一般的な表記ですね。)
利用状況として、以下のような条件を仮定します。 (値の範囲が極端に小さいですが、分かりやすさ重視のためです。)
- ユーザIDの値の範囲は0〜31
- 存在する(DBにデータがある)ユーザIDは、3,17,25の3人分
- 説明の都合上、3人分で負荷が高いことにします…。
- ブルームフィルタ用のハッシュ関数を16の剰余(
x % 16、ハッシュ値の範囲は0〜15) - ブルームフィルタ用のビット配列のサイズは、16bit(2B、範囲は同じく0〜15)
- すでに書いたように、ハッシュ関数の特性がビット配列のサイズを決めてます。
この条件で、ブルームフィルタの4つ状態について解説します。
1. 準備段階
準備として、ビット配列の「処理が必要」な入力のビットを1にします。今回はデータが存在するユーザIDに該当するビットをセットします
具体的には、以下のように、存在するユーザ3人分(3,17,25)のハッシュ値、3、1、9(3 % 16 = 3、17 % 16 = 1、25 % 16 = 9)の3箇所のビットを1にします。
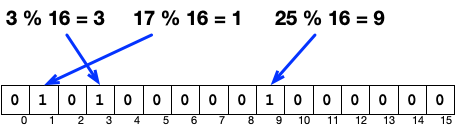
これで、存在するユーザのビットに1が立った状態になりました。準備出来たので、この後は利用の例です。
2. 存在するユーザのユーザID(25)で検索
ブルームフィルタの利用時は、対応するビットの存在をチェックして、処理が必要か判断します。
ユーザIDが25の場合は、ハッシュ値の計算は25 % 16 = 9です。 以下の図のように、9番目のビットが1でしたので、処理が必要と判断し、DBを検索します。
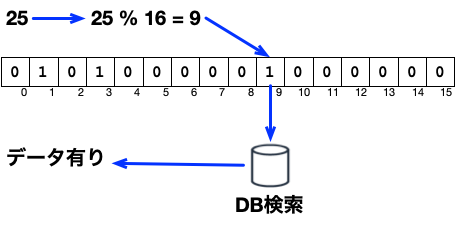
存在するユーザの場合、準備で該当するビットを1にしていますから、問題なく検索が実行されるわけです。
3. 存在しないユーザのユーザID(23)で検索(フィルタ成功)
今度は、存在しないユーザの場合です。
ユーザIDが23の場合は、ハッシュ値の計算は23 % 16 = 7です。
以下の図のように、7番目のビットが0でしたので、処理は必要ないと判断して、DBは検索しません。
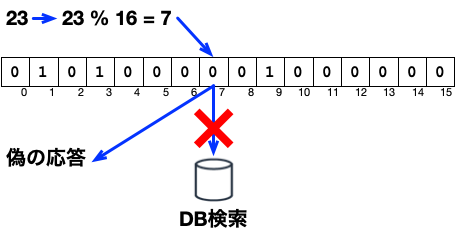
DBを検索しないので、DBの実際の検索結果はありませんから、結果を捏造して返します。
この入力値では、存在しないユーザを事前に判断して、無事にフィルタ出来ました。ただ、常にうまく行くわけでないので、うまく行かないのが次の例です。
4. 存在しないユーザのユーザID(1)で検索(フィルタ失敗)
同様に、存在しないユーザの場合です。
ユーザIDが1の場合は、ハッシュ値の計算は1 % 16 = 1です。
以下の図のように、1番目のビットが1でしたので、処理が必要と判断してDBを検索してしまいます。

でも、DBを検索してもデータは無いので、データが無いとの結果を返します。
この場合、正しく結果は返していますが、DBの検索が無駄に実施されてます。要は、フィルタ失敗です。 ユーザIDの17と1でハッシュ値が一致(衝突)したために、このようなことが起きるわけです。
そして、この状態を擬陽性といいます。
ブルームフィルタの特性
とても単純な例でしたが、ブルームフィルタの動きは、おおよそ紹介できたと思います。
ただ、擬陽性の特性をあまり説明しなかったので、擬陽性を中心にブルームフィルタの特性ついて説明します。
先程の例は、説明の都合上、わざと擬陽性を発生させていました。
値の範囲が0~31ですから、ビット配列のサイズを32bit(4バイト)に変更すれば、擬陽性が起こらなくなります(ハッシュ関数の変更も必要です)。
より現実的なユーザIDの範囲が0~65535の場合でも、8kB(65536bit)のビット配列なら擬陽性が起こらなくできます。 8kB程度のサイズなら、オンメモリでフィルタ処理も可能で、コスパ良さそうです。
このように、擬陽性の発生はコスト(容量)の追加で減らせるし、場合によっては、無くせるわけです。
ただ、擬陽性の発生は無くさなければならないわけでもありません。 擬陽性が発生しても、処理が止まったりせず、無駄な処理が減らないだけです。
例えば、負荷を少し減らしたいなら、少しフィルタされれば目的は達成するので、擬陽性は起こっても、小さめなビット配列で十分です。
このように、擬陽性は、「ケチってもそこそこ動く」素晴らしさとも言えるわけです。
これらの特性から、ブルームフィルタをうまく使うためには、擬陽性の発生率とサイズのバランスを取らなければなりません。 逆に言えば、バランスがうまく取れれば、少ないコスト(容量)で、効果的に処理をフィルタ出来るわけです。
要は、ハッシュ関数やビット配列のサイズの決め方が、ブルームフィルタを使う上で注意点になるわけです。
ISONでの利用方法
特性も説明したし、ブルームフィルタの雰囲気もだいたい説明できました。 ということで、具体的な使い方の例として、ISONでの利用法について説明していきます。
ISONの都合
まずは、前提となる、ISON側の都合についてです。
ISONは、保存したデータを検索に再利用するため、以下のような要件がありました。
- データの正引きをそこそこ速く行いたい。
- データの逆引きも正引きと同じように速く行いたい。
- データをより多く蓄積したいので、ストレージ容量も節約したい。(要は、正引き用データを逆引きにも流用して、ケチりたい。)
- データ管理を楽にしたいので、同じkeyのデータ置き場を分散させたくない。(要は、逆引きデータを増やさずに、管理をサボりたい。)
ケチりつつ高速化とかかなり無茶気味ですが、悩んだ結果、なんとか、ブルームフィルタのちょっと変わった使い方を思いつきました。
ということで、ISONは、ブルームフィルタを使って、なんとか要件を満たしつつ、逆引き処理のケチケチ高速化を実現しています。
ISONのデータ構造
ISONは、データの論理構造的には、valueが複数あるKey-Value的(Key-Multi-valueな?)データ管理のシステムです。
データ登録時は、key(入力)に対応した複数のvalue(データ)を登録するので、keyが入力値になります。
ISONの設定で指定されたトップディレクトリに、keyのハッシュ値(0x00〜0xFF)をファイル名にした多段のディレクトリを作り、更にその下に各key用のディレクトリを作って、valueを保存しています。
ディレクトリ間の関係は以下の図のようになります。
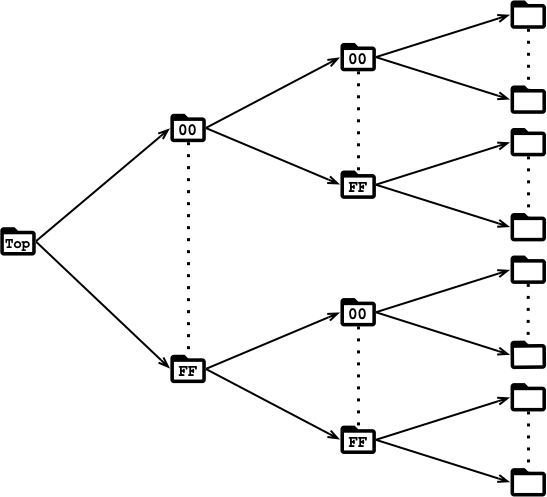
多段のディレクトリに分けている理由は、1つのディレクトリ内のディレクトリが多くなり過ぎないようにするためです。
Apacheやnginxのキャッシュなどで、似たような階層構造でデータ保存しているため、見慣れている人もいると思います。
ISONの正引き
正引き検索は、以下の図のように、keyから作った複数のハッシュ値を、ディレクトリ名と比較することでディレクトリを絞り込み、無駄に探さずに済むようにしています。
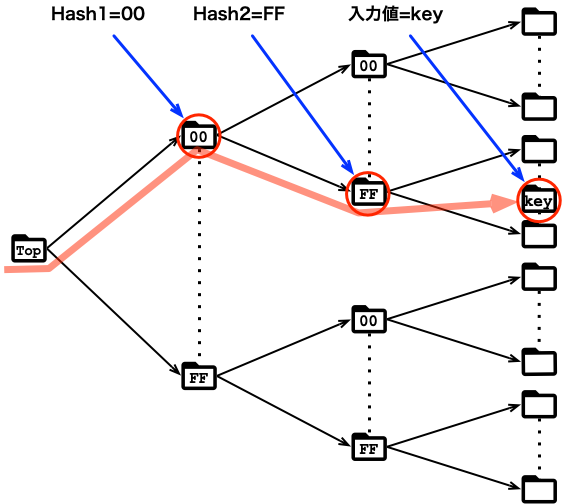
まあ、ここまでは、ふつうですね。
ISONの逆引き
ISONは容量ケチケチ方針なので、正引き検索用に作られたディレクトリツリーを流用して、逆引き検索もなんとかしています。
ただ、逆引きは、valueが入力なので、「keyのハッシュ値を使ったディレクトリの絞り込み」が使えません。
そこで、以下の図のように、正引き時のディレクトリ名の代わりに、value用のブルームフィルタを用意する工夫をしました。 value用のブルームフィルタはデータ保存時に準備します。
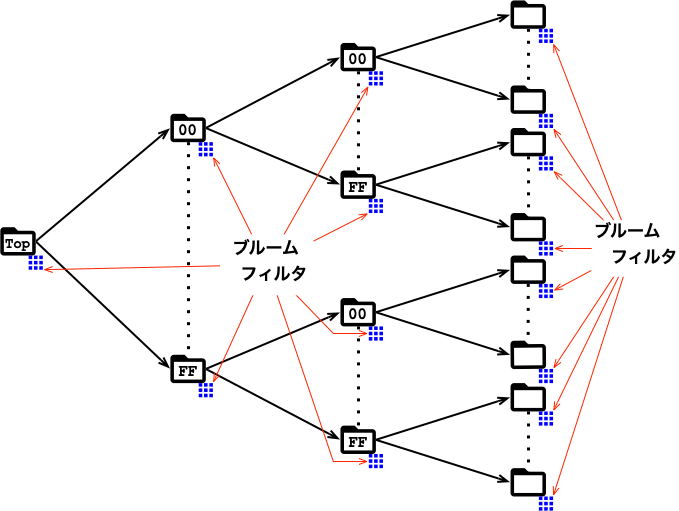
容量は、ブルームフィルタ用のファイルを追加しただけの、少しの増加で済みました。
使い方は、以下の図のように、ディレクトリをたどる毎に、デイレクトリ名の代わりに、ブルームフィルタで対象のディレクトリを絞り込むだけです。

正引きの処理とそれほど変わっていません。 正引き検索との処理の主な違いは、ハッシュ値との比較対象がディレクトリ名からブルームフィルタに変わったことぐらいです。
処理も大きく変わらないのですから、処理時間も同じぐらいです。
ブルームフィルタのおかげで、なんとか無茶な要件が解決できました。 ブルームフィルタって、すごくないですか? (ブルームさんに感謝をこめて、この工夫を勝手に「多段ブルームフィルタ」と呼んでます。)
ブルームフィルタの所感
ブルームフィルタは、実際に使うと便利なのに、あまり認知されていないように思います。 たぶん、この説明で初めて名前を聞いた人も、居ると思います。
ということで、このブルームフィルタの人気(?)のなさは、もったいないので紹介してみました。 ブルームフィルタの雰囲気ぐらいは伝えられたと思ってますが、どうでしたか?
ブルームフィルタの詳しい説明には、擬陽性とか、削除が難しいとか、問題となる癖が丁寧に書かれています。 だから、使いにくそうで、避けられてしまうのも想像できます。
でも、適切な用途で実際に使えば、そんなに問題も起きず、容量効率の良い魅力的な仕組みだとわかります。
「意外と便利そう!」とか「多少癖があっても、うまく使ってみたい!」とか思いませんか?
興味が持てたら、ぜひ、Wikipedia等の解説を探して、読んでみてください。 機会があったら、ブルームフィルタを使って、素晴らしいシステムを作ってみてください。
そろそろ「雰囲気を知ってもらう」を超えそうなので、ブルームフィルタとISONでの使い方の話は、これで終わりにします。