CHAGEの裏側: レイテンシに呪われないQAQの世界
2019年12月17日 火曜日
CONTENTS
Twitterフォロー&条件付きツイートで「バリーくんぬいぐるみ」を抽選で20名にプレゼント!
応募期間は2019/11/29~2019/12/31まで。詳細はこちらをご覧ください。
今すぐツイートするならこちら→![]() フォローもお忘れなく!
フォローもお忘れなく!

【IIJ 2019 TECHアドベントカレンダー 12/17(火)の記事(その2)です】
こんにちは、CHAGE 開発メンバーの くまさか です。
CHAGEの紹介と並行して、CHAGEの中が気になる人に、CHAGEで使われている技術をちょっと濃い目に解説するという企画の第三弾です。
今回は、QAQ Pipelineに関する記事です。思い入れがあるので、ヒラマツ から奪って書いてしまいます。
今回の記事では、本編でCHAGEやASKSが、複数のサービスから構成されている事を紹介しているので、それら個々のサービスを連携させる際の課題やそれを解決した構造を紹介します。
以下の知識について軽く説明を交え紹介しますが、本題とは異なるので、詳しくは述べません。ご了承ください。
- レイテンシ
- 何かを要求してから、その結果が返送されるまでの遅延時間(待ち時間)のこと
- 小さいほど高速に応答されているとみなせる
- スループット
- 一定時間内に処理されるデータ量のこと
- 大きいほど高速に処理できているとみなせる
- REST
- RPC
- マイクロサービス
マイクロサービスな理由
CHAGE は、複数のサービスからなっているマイクロサービスです。
マイクロサービスで実現できることは、サービス毎のメンテナンス性の向上や、サービスの単純化等があります。
CHAGEがマイクロサービスである理由は、いくつもありますが、最も大きいのは並列処理によるスループットの向上です。
CHAGEは、OSINT支援を行えるよう、一定時間内でより多くのデータを応答することが求められています。そのため、並列処理がどうしても必要でした。
一応、並列処理の例を紹介します。
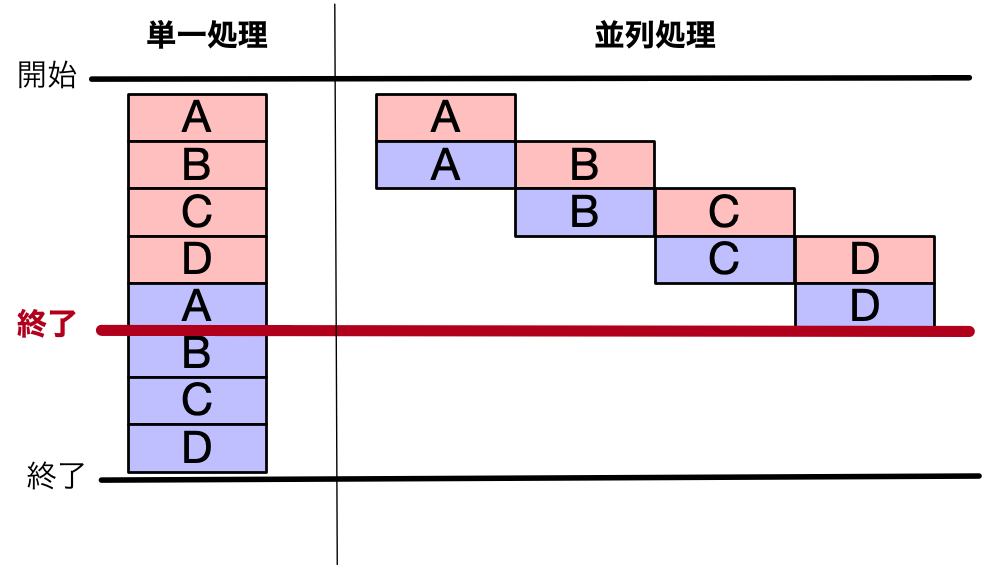
1ブロック1秒かかる処理であると仮定すると。
単一処理の場合、8個のブロックを順番に実行するので、8秒も要します。
サービス単位で動作する並列処理の場合、1つのアルファベットを処理次第、次の処理が行えます。それにより、5秒で処理が終了します。
このような単純な例であっても、並列処理により、5/8の時間で処理を行えることがわかります。
CHAGEは、数千、数万の処理があるので、より適切な構造であれば、1検索あたりの時間の短縮や同時に行える量が増え、トータルスループットが向上します。
レイテンシの呪い
マイクロサービスには、避けられない問題があります。
それは、サービス間が意図を伝えるのに通信が必要であるという点です。
やりたいことは分割であって、通信ではありません。しかし、通信が必須であるという状況が生まれています。
”なんかSFのワープ的なもの”で瞬間的にサービス間が意図を連携できればいいのですが、我々が活用するコンピュータでは、そういったわけにはいきません。
そのため、サービス間の通信をいかに効率的に行えるかどうかが、マイクロサービスの並列処理で速度を上げる際の課題となってきます。
では、その効率化すべきサービス間通信がどの程度の規模であるかというと、
動作させる処理の1,000倍程度のコストを効率化する必要があります。
では、なぜそんなにも大きなコストがかかるのでしょう。
それは、扱うコンピュータリソースのレイテンシを評価すると答えにたどり着きます。
まずは、扱っているパーツごとに大きく考えてみます。
純粋な処理をごりごり行う場合、メモリやCPUを活用します。
それに対し、サービス同士が通信を行う場合、となりのメモリやネットワークやディスクを活用します。
これら分類でコンピュータリソースのレイテンシをグラフ化しました。
すでにいくつかのメーカから公開されている情報等をまとめている方がいたので、活用させてもらいます。
eshelman/latency.txt : https://gist.github.com/eshelman/343a1c46cb3fba142c1afdcdeec17646
上側のグラフが、純粋な処理をごりごり行う場合に活用しそうなリソース。
下側のグラフが、通信を行う場合に活用しそうなリソースです。
(わかりやすくなるよう、下側のグラフに上側でレイテンシの高いメモリを1つ載せました。)
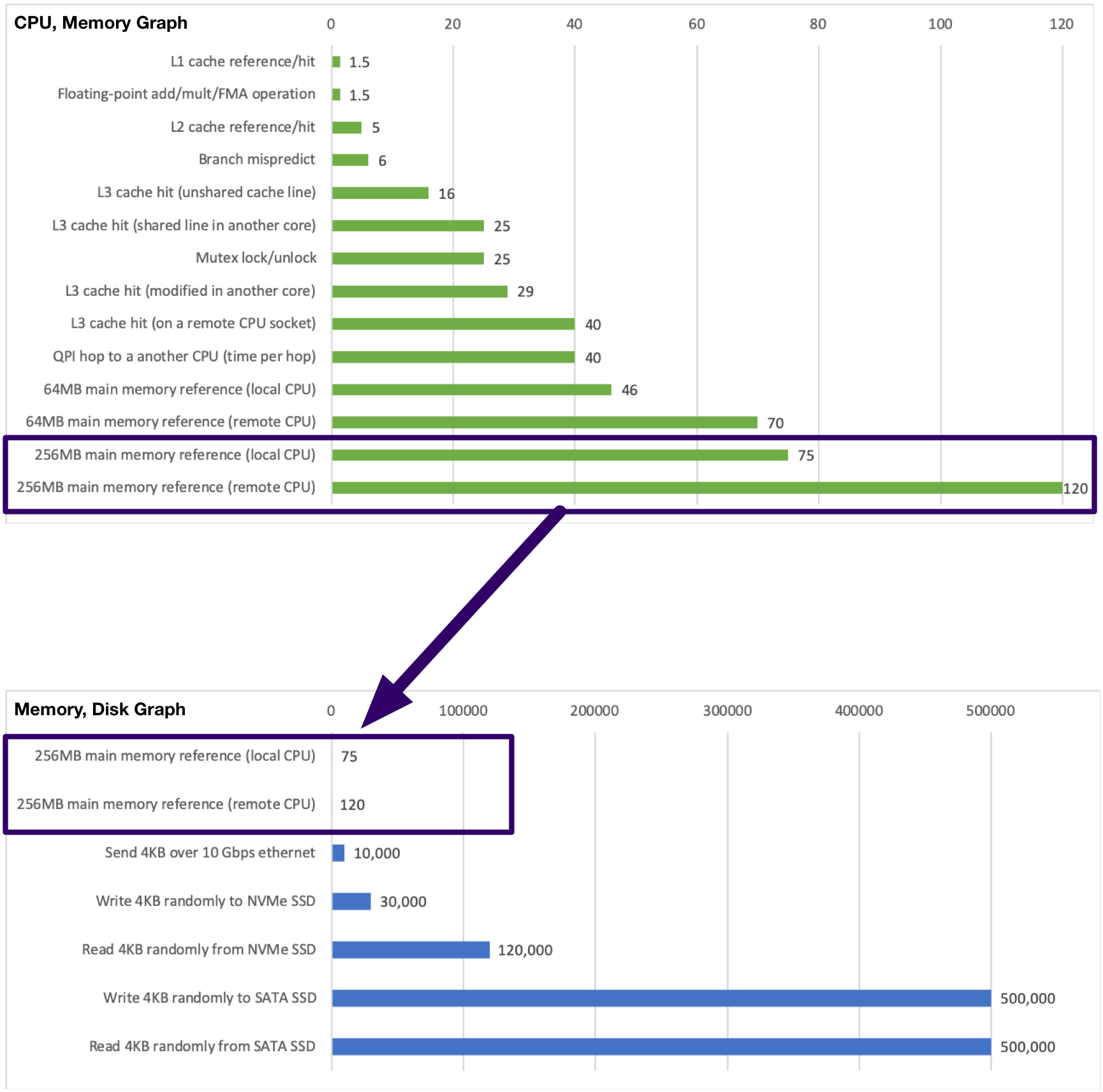
一目でわかるように、通信のレイテンシの大きさと比べると、純粋な処理のレイテンシは微々たるものです。
(HDDは、500万以上で、レイテンシの差が一目でひどいとわかるぐらい大きすぎたので、SSDまでを表にしました。)
純粋な処理から考えると、通信のレイテンシは桁違いのコストが発生することがわかります。
こういったポイントがコストを 1,000倍近くにさせる原因です。
処理を効率的に行うためのマイクロサービス化により、通信が必要であるがゆえに膨大なコストを無駄に払わなくてはいけない。まさに呪いです。
同期的通信の場合
マイクロサービスを同期的通信で行うことを考えてみます。 同期的通信は、Requestを出し、Responseを取得する構造になっています。
例えば、RPCやRESTがあります。

個々のサービスが、次のサービスにRequestを出し、Responseを受け取ってから処理を進められるので、わかりやすい構造でマイクロサービスを実現できる特徴があります。
加えて、サービスごとの応答が保証できるので、簡単に安全な処理を作ることが可能です。
課題。応答待ち
RPCやRESTの場合、Requestを出し、Responseが返ってきたら後続の処理を実施するクライアント構造になることが多いでしょう。
そういった場合、Responseが返ってこない限り処理が待たされます。
階層の浅いマイクロサービスであれば、そこまで気にならないかもしれませんが、階層が深くなるとどんどん待ち時間が積み重なっていく問題があります。
先ほどの4つのサービスから構成された例に、積み重なる待ち時間のイメージを追加してみました。
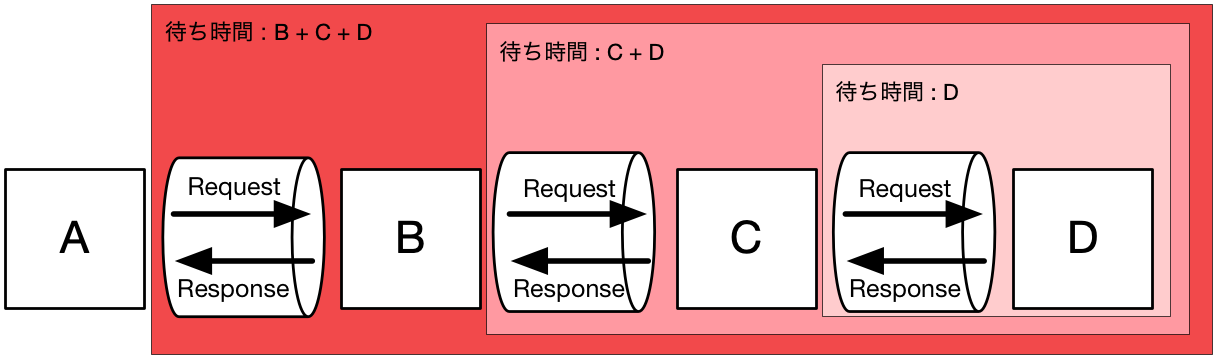
こういった構造の場合、Aの待ち時間は、Bだけであることが理想です。
しかし、Bは、C + Dの待ち時間があり、Aは、実際のところ、B + C + Dの待ち時間があります。
結局、Aを実行する際に、B, C, Dは順番に待ち時間を発生させているので、それらと同期的な動きをします。
せっかくマイクロサービスにして、並列処理で高速化させようとしているのに、これでは意味がなくなってしまいます。
さらに、これらは1階層増えるごとに不要な高いレイテンシが加わっている実情があるので、全体のスループットは階層を重ねるごとに下がります。
本編で紹介しているASKS はどんどん検索するという、数を集めるシステムなので、スループット低下は単位時間あたりに検索できる件数が下がり、大きな問題になります。
それは、CHAGE の OSINT支援に大きな影響を及ぼしていきます。
本編で紹介しているCHAGE 以外のシステムでも、おそらくこれらの問題を認識した人が解決できる構造を色々検討されています。
例えば、Googleが公開したgRPCなどがあります。
QAQ Pipeline 構造
CHAGEのような構造のマイクロサービスで、不要なレイテンシの積み重ねを発生させないための答えはすごくシンプルです。
各サービスが「これやっといて」と他のサービスに投げつければよいのです。
応答結果なんてものは一切待たず、本当に投げつけるだけをすることが大切です。「Request Status : Success !」のようなものすら待っていることにつながるので、成功したかどうかすら気にしないことです。
しかし、ただ投げつけて終わると、結果を受け取らないので、構造を工夫しました。
どのような工夫かというと、結果も「これやっといて」と渡すような構造にすることです。
もう少し技術的な表現をしていくと、RequestともResponseともとれる構造を設計し、依頼のような結果のようなデータをお互いに投げつけあう構造にしています。
依頼とも結果とも取れる構造は、QAQ(Question to Answer 2-way Query)と呼んでいます。
これにより、Queryをただ、どんどん投げつけることでいつのまにかリクエスト元にデータが集まるという構造を実現しています。
つまり、
RPCのようなこんな構造に流れるデータをQAQにして、

それらが、リクエスト元にも「これやっといて」と投げつける概念にし、
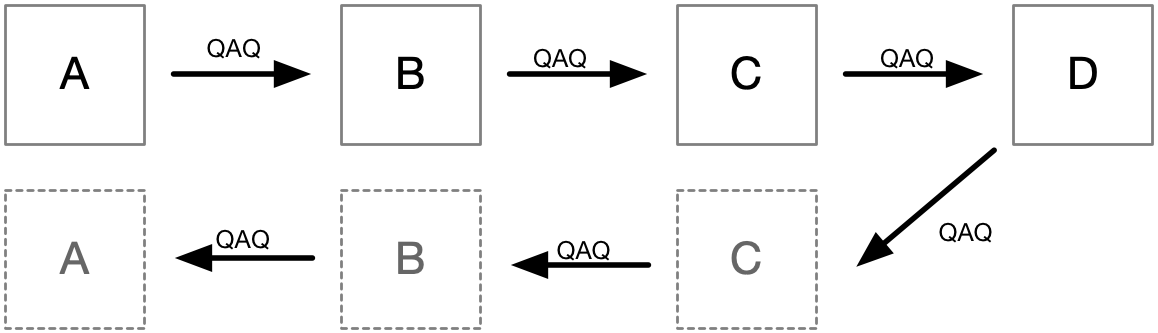
QAQが左から右に流れるだけのPipeline構造と見立てているわけです。
![]()
ちなみに、QAQが流れるPipeline構造なので、この構造をQAQ Pipelineと呼んでいます。
待ちがない。というか待てない
QAQ Pipelineは、左から右にどんどん投げつけるだけの構造です。
投げつけて終わるので、誰も待ちません。
しかし実は、ストリームエンコードが行えないデータを扱うようなケースではデータエンコード待ち時間が必要です。
QAQを早出する際に、データをやりとりできるbyte列へ変換するエンコードの待ち時間が発生してしまう為です。
ただこれは、その前に説明したようにネットワークI/Oの待ち時間の方が大幅に大きいので大きな問題ではありません。
例えば以下のように、流れるデータが、サービスごとに受け取り切らないと次のサービスに渡せないという構造に限った話です。
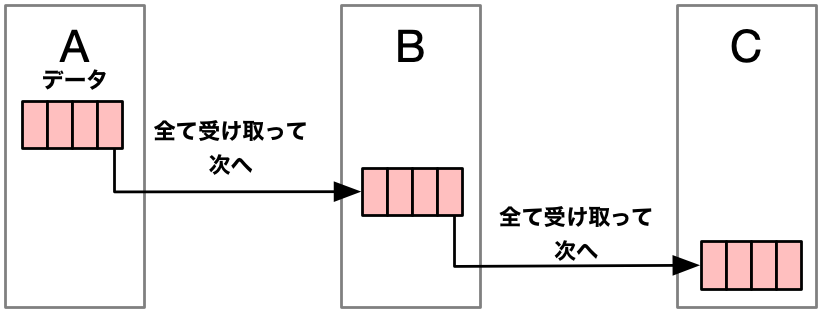
しかし、本編で紹介しているCHAGE は、I/Oで待つ時間が大きいから、シリアライズの処理で待って良いといった考え方で開発していません。
ストリームエンコードが行えるプロトコルとしてMPPPというもの定義し、小さな無駄も削減しています。(MPPPについては本編で紹介しています)
MPPPはストリームエンコードが行え、その上で転送されるデータもヘッダから次の転送すべきサービスが判明する構造になっているので、受信しつつ、変換しながら、その先のサービスに送信(転送)するといった構造が実現できています。

レイテンシが与える影響は?
サービス同士を連携するレイテンシは抑えきれません。
しかし、QAQでは、応答という概念を無くしたことで、要求と応答が同期しないので、サービス同士を連携するレイテンシが積み重ならなくなりました。
それにより、サービス同士の連携では、スループットが低下しなくなり、高速な並列処理を実現しています。
これまでの裏側記事で、いくつかの技術や組み合わせを紹介していました。
CHAGE の対象であるOSINTで活用するデータソースのほとんどが内製なので、技術の組み合わせや構造は私たちの自由にできます。
今回のQAQ Pipelineは、まさに自由にやりまくった結果です。
とは言っても、自由に変えられない領域もあるので、その辺を正しく認識し、適切に組み合わせることが必要です。
今回の記事でいうところのコンピュータのパーツの速度を紹介したあたりですね。
私は当時よく知らなかったので、QAQ Pipelineの為に調べました。
PCを自作する時に個々のパーツの速度を見ることはあります。ただ、パーツ種別間の比較情報って、あまり見ないんですよね。
SSDの速度なんてCPUやメモリの世界からみたら本当に遅かったですね。
Linux界隈のどこかで「メモリいっぱいあるなら、SSDがいくらはやくてもSwap確保しない方がいいよ。」と言っていた方の気持ちが実感できました。
さて、最後に。
QAQ Pipelineという構造。なぜ思い入れがあるかというと、構造がすごいってことももちろんありますが…。
顔(QAQ) が、オノ(P) を持っているように見えて、脳内擬人化によって愛着が湧いているからなのです。
皆さんはどう見えますか。。。。??