JSON ファイルを CSV ファイルに変換したい
2017年12月06日 水曜日
CONTENTS
【IIJ 2017TECHアドベントカレンダー 12/6(水)の記事です】
JSON ファイルを CSV ファイルに変換したい
異なったサービスやアーキテクチャ間でデータをやり取りをしたいときに、JSON 形式を使うことはよくある話です。構造化されたデータを適切に表現するのにもってこいですし、大規模運用に欠かせない Elasticsearch も一瞬で JSON 形式の結果を返してくれます。
しかし、この JSON 形式、何らかの理由があって目で紐解こうとすると厄介です。大変読みにくいのです。
巷にある jq コマンドなどで、ある程度の整形は可能ですが、目が JSON フィルタになっている職人はさておき、ネストしている開きカッコに対応する閉じカッコを探したり、運用でよくあるワンライナーでサクッと処理したいときに苦労します。
できれば 1要素 1行で処理したい。可能なら、みんな大好きな CSV で見たい。
そんなとき、csvkit を使うと便利です。
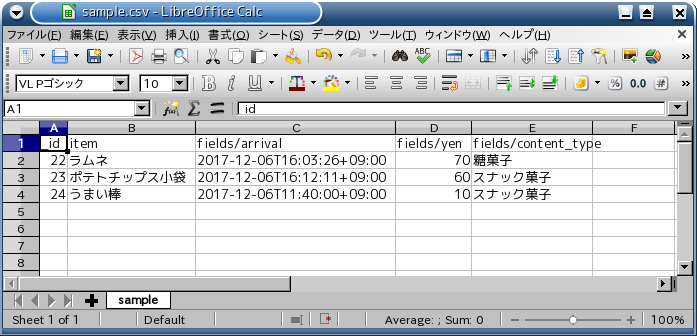
例えば、こんな JSON ファイルが転がっているとします。
$ cat sample.json
[
{
"_id": 22,
"item": "ラムネ",
"fields": {
"arrival": "2017-12-06T16:03:26+09:00",
"yen": 70,
"content_type": "糖菓子"
}
},
{
"_id": 23,
"item": "ポテトチップス小袋",
"fields": {
"arrival": "2017-12-06T16:12:11+09:00",
"yen": 60,
"content_type": "スナック菓子"
}
},
{
"_id": 24,
"item": "うまい棒",
"fields": {
"arrival": "2017-12-06T11:40:00+09:00",
"yen": 10,
"content_type": "スナック菓子"
}
}
]
これを CSV 形式に変換するには、csvkit に含まれる in2csv コマンドを使います。
$ in2csv sample.json _id,item,fields/arrival,fields/yen,fields/content_type 22,ラムネ,2017-12-06T16:03:26+09:00,70,糖菓子 23,ポテトチップス小袋,2017-12-06T16:12:11+09:00,60,スナック菓子 24,うまい棒,2017-12-06T11:40:00+09:00,10,スナック菓子
すごい! 便利すぎて鼻血が出そうです!
これなら Excel が大好きな、あの人にも一発で提出できます。こんな風にね。

Excel ファイルも CSV にしたい
ところで Excel といえば、お客様のポリシー上の理由で、送付されてくるファイルが全て Excel 形式であることがあります。
しかし、我々は運用エンジニア。1日のほとんどをターミナル内で過ごしていますし、昨今の標的型攻撃にしかり、ときには危ないコンテンツが含まれているかもしれません。そんなとき in2csv コマンドが使えます。なんと in2csv は Excel ファイルも読めるのです!
サンプルとして、今年から M2M (Machine to Machine) サービス専用として運用が開始された、020 番号の割当状況を in2csv で読み込んでみます。本資料は総務省で公開されている「電気通信番号指定状況」の「4. M2M等専用番号(020)」から入手できます。
$ in2csv --skip-lines 4 --no-inference 000477281.xls | head -n 20 番号,0,1,2,3,4,5,6,7,8,9 02010,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ 02011,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI 02012,ソフトバンク,ソフトバンク,ソフトバンク,ソフトバンク,ソフトバンク,ソフトバンク,ソフトバンク,ソフトバンク,ソフトバンク,ソフトバンク 02013,ソフトバンク,ソフトバンク,ソフトバンク,ソフトバンク,ソフトバンク,ソフトバンク,ソフトバンク,ソフトバンク,ソフトバンク,ソフトバンク 02014,ソフトバンク,ソフトバンク,ソフトバンク,,,,,,, 02015,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ 02016,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ 02017,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ 02018,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ 02019,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ 02020,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ 02021,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ 02022,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ 02023,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,NTTドコモ,,, 02024,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI 02025,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI 02026,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI,KDDI 02027,KDDI,KDDI,KDDI,沖縄セルラー電話,,,,,, 02028,,,,,,,,,,
わお! 素晴らしい! このデータの再利用を全く考慮していない Excel ファイルも、たちまち何やら使えそうな形式になりました!!
ところで、鼻血を出していて忘れていましたが、我々は CSV 職人ではありませんので、ターミナルで Excel っぽく見たくなったとします。
$ in2csv --skip-lines 4 --no-inference 000477281.xls | csvlook --no-inference | head -n 21 | column -s '|' -t 番号 0 1 2 3 4 5 6 7 8 9 ----- ------ ------ ------ -------- ------ ------ ------ ------ ------ ------ 02010 NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ 02011 KDDI KDDI KDDI KDDI KDDI KDDI KDDI KDDI KDDI KDDI 02012 ソフトバンク ソフトバンク ソフトバンク ソフトバンク ソフトバンク ソフトバンク ソフトバンク ソフトバンク ソフトバンク ソフトバンク 02013 ソフトバンク ソフトバンク ソフトバンク ソフトバンク ソフトバンク ソフトバンク ソフトバンク ソフトバンク ソフトバンク ソフトバンク 02014 ソフトバンク ソフトバンク ソフトバンク 02015 NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ 02016 NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ 02017 NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ 02018 NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ 02019 NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ 02020 NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ 02021 NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ 02022 NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ 02023 NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ NTTドコモ 02024 KDDI KDDI KDDI KDDI KDDI KDDI KDDI KDDI KDDI KDDI 02025 KDDI KDDI KDDI KDDI KDDI KDDI KDDI KDDI KDDI KDDI 02026 KDDI KDDI KDDI KDDI KDDI KDDI KDDI KDDI KDDI KDDI 02027 KDDI KDDI KDDI 沖縄セルラー電話 02028
見える! 見えるぞ!
インストール
インストールはかんたん。Python が入っている環境なら、pip コマンドを一発叩くだけです。
# pip install csvkit
まとめ
入力されるデータが不定であったり、サクッと行処理したいときに、このように小回りできるツールが手元にあると大変便利ですね。
Excel ファイルの扱いについては、「一度、Excel で開けば CSV にできるじゃん」という声も聞こえてきそうですが、csvkit と他のツールを組み合わせることで in2csv を強力なフィルタとして使うこともできます。
また、今回は触れなかった csvcut で特定の列のみを抽出したり、csvjoin で複数の CSV ファイルを横に結合したり、csvsql で CSV ファイルを RDB のテーブルに見立てて、そのまま PostgreSQL に挿入できる形式に変換するといった、CSV マニアにはたまらない機能があります。ぜひ触れてみてください。
補足
冒頭で触れた Elasticsearch の出力は、キーがネストされる場合があります。JSON 形式としては valid なのですが、現状の in2csv コマンドでは対応できないため、jq コマンドなどで前処理してあげる必要があるかもしれません。例えば、このような感じです。
jq .${keyname1}.${keyname2} < sample2.json | in2csv --format json > sample2.csv