自然言語処理でトラフィック変化検知
2021年12月06日 月曜日
CONTENTS
【IIJ 2021 TECHアドベントカレンダー 12/6(月)の記事です】
猫も杓子も深層学習と言っていた時代も一区切りついたように思います。画像処理の分野で一躍(再)注目を浴びた深層学習技術は、自然言語処理や囲碁ゲームなど、他の分野でもめざましい成果をあげました。
我々はインターネット界隈で活動していますが、それらの技術を自分たちの分野に活用できないかと検討をしたものです。何か今までできなかったようなすごいことが、深層学習を使ったら魔法のように実現するのではないか、と夢を見ていた時期もありました。もちろん、トップ研究者の方々がいろんな方面からインターネットへの深層学習の応用を試みて、素晴らしい成果が上がったことに間違いはないと思います。ただ、それらが今のネットワークサービスを劇的に変化させたかというと、まだそこまでは行っていないのかな、とも思います。
トラフィックの変化検知も近年の深層学習の発展に大きく期待を寄せた分野のひとつです。これまでもさまざまな取り組みがなされてきました。異なる分野で確立された手法を別の分野で応用すると、思いのほかうまく動いた、という話を聞くことがありますよね。この記事では、自然言語処理技術をトラフィック解析、具体的にはトランスポート層ポート番号のアクセス解析に利用するというアイデアを紹介したいと思います。詳しい解説は論文にまとめていますので、詳細を知りたい方はそちらを参照してください。
TF-IDF
自然言語処理といっても、その技術はさまざまです。今回注目するのはTerm Frequency – Inverse Document Frequency (TF-IDF)と呼ばれる手法です。冒頭で深層学習の話を持ち出しましたが、TF-IDFは深層学習とは全く関係のない、従来から広く使われている手法のひとつです。深層学習の話を期待していた人はごめんなさい。
TF-IDFは、自然言語で書かれた文書の中の単語に重みを付ける技術です。基本的には出現数が多い単語がより重要となりますが、単に出現数を数えるのではなく、複数の文書を見渡して、たくさんの文書で使われている単語は重要度が低く、少数の文書のみに出現する単語は重要度が高くなるように調整されます。あるひとつの文書Dを読んでみた時、単語「りんご」と単語「みかん」がどちらも10回出てきたとします。ところが、「りんご」はD以外の他の文書にも頻繁に出現し、「みかん」がこの文書だけにしか出現していない場合、「りんご」と「みかん」がどちらも10回出ているにもかかわらず、文書D内での「みかん」の重みは「りんご」よりも大きくなるということです。
この考え方は直感的に理解できます。少数の文書にだけ特定の単語が出現するというわけですから、その単語はその文書内で重要な意味を持っていると考えるのが自然です。
TF-IDFは簡単に計算できますが、重みの付け方にはいくつかの方法があり、全てにおいてうまく機能する計算式というものはありません。自分が取り扱うデータセットに適したものを選択する必要があります。Wikipediaによく使われる計算式が紹介されているので、興味のある方は参照してみてください。
ネットワークトラフィックとTF-IDF
なるほど、TF-IDFは理解した、でも、それをどうネットワークトラフィックに応用するの?というのが次の段階です。TF-IDFを使うにあたって重要な要素が4つあります。「Term(単語)」、「Term Frequency(単語の出現数)」、「Document(文書)」、「Document Frequency(文書の出現数)」です。これらをネットワークトラフィックの要素に関連付けなければなりません。ここでは以下のような対応付けをしてみます。
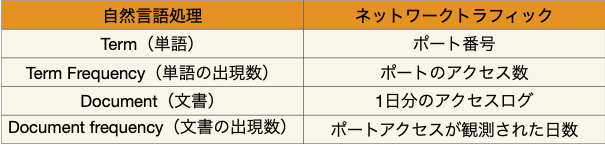
図: 自然言語処理でのTF-IDF要素とネットワークトラフィックでのTF-IDF要素の関係
TF-IDFは自然言語で書かれた文書に含まれる単語が、その文書の中でどれくらい重要な意味を持っているかを、文書の中での出現頻度、および複数の文書に跨った出現頻度を元に計算する手法でした。ネットワークトラフィックに対しても期待した通りに動作するとしたら、特定の日付におけるポートへのアクセスが、同じ日の他のポートへのアクセスと比べてどれくらい重要なものだったかを、その日のアクセス数と、他の日でのアクセス傾向を元に計算してくれるはずです。ある特定の日に、複数のポートで同じくらいのアクセス数が観測されていても、その他の日のアクセス傾向を考慮して「よりその日に特徴的な」ポートを知ることができるというわけです。
データセットの前処理
実際にトラフィックデータに対してTF-IDFの計算を実施してみると、全く期待した通りには動作しないことがわかります。これは何も、トラフィックデータに限った話ではなく、自然言語処理においても何の工夫もなく文書を処理したのでは期待した結果は得られません。今回の試みでは以下のふたつの前処理を実施しています。
- ストップワードに相当するポートの選定
- 継続的に毎日アクセスされるポートの処理
ストップワードの処理
TF-IDFではストップワードと呼ばれる、重要度の計算対象としない単語の集合を定義して、事前にその単語を文書から取り除く前処理をするのが一般的です。英語であれば、「a・the」や「and・but」などの冠詞や接続詞類、日本語なら「は・に」や「だから・しかし」などの助詞や接続詞類を取り除くことが多いでしょう。何をストップワードにするかは、解析の目的や、対象となるデータセットに依存します。一般的な単語に加えて、ケースバイケースで指定することもあります。
では、今回のネットワークトラフィックでは何がストップワードに該当するのか、それを決めなければなりません。
結論から言うと、体系的にストップワードを決定する方法は見つけきれていません。今回は、大量のアクセスがみられるポートを列挙し、経験則からストップワードとして取り除くポートを決定しました。具体的には445、23、22、80、81、8080、443を選択したのですが、どのポートをストップワードとして指定するかは、データセットに大きく依存するはずです。もしみなさんが同じ手順を手元のデータセットに対して実行する場合は、データセットの特徴を見極めて選定してください。
継続的に毎日アクセスされるポートの処理
今回解析対象とするデータは、特定のアドレス空間の範囲のトラフィックを観測して、そこへ到達するパケットの数をポート番号ごとに数えたものになります。ネットワークのトラフィックデータは、観測対象となるアドレス空間が大きくなればなるほど、ほぼ全てのポートへのアクセスが毎日観測されるようになります。世の中にはポートスキャナーと呼ばれるソフトウェアが存在し、インターネット上のノードに対してどのポートがアクセス可能になっているかを定期的に調べるポートスキャンと呼ばれる予備攻撃を実行しています。これらのソフトウェアはトランスポート層のポート空間(0~65535)を広範囲にわたってアクセスしてきます。アクセスを観測しているアドレス空間が広くなれば、それだけポートスキャンを受ける頻度も上がり、結果的にアクセスされるポート番号の範囲も広くなります。
このことはTF-IDFのIDF部分の計算に影響を及ぼします。IDFとはInverse Document Frequencyですから、ある単語がいくつの文書に出現したかでその値が決まります。もし10個の文書があって、全ての単語が全ての文書に出てくるとすると、全ての単語のIDFの値が同じになってしまいます。するとTF-IDFの結果はTF、すなわち単語の出現頻度のみで決まってしまうため、文書ごとの単語の出現傾向の違いが全く反映されなくなるのです(全ての文書に全ての単語が出現しているので、当然の結果です)。
通常、自然言語の文書ではそういうことは起こりにくいのですが、先に述べたように、ポートアクセスでは全てのポートが毎日観測されるという事象は珍しくありません。そこで、今回の試みでは、日ごとのアクセスログを確認し、アクセス数が極端に小さいポート番号に関しては、その日のログから取り除く処理をしています。閾値の決定についての詳細は論文を参照してもらえればと思います。
結果紹介
それでは、TF-IDFを利用してポート番号のアクセス解析をした結果を2つほど紹介したいと思います。ひとつ目は2020年8月3日のTCP 9530番ポートに関するもの、ふたつ目はUDPのポートアクセスに関するものです。
2020年8月3日 TCP 9530番ポート
この日のTF-IDFの値を計算した結果、上位5つのポート番号は1443、21、5555、9530、3389となりました。計算には過去30日間のアクセスログを利用しています。TF-IDF的には30個の文書があるということです。過去30日分のアクセスログに出現するポート番号を調べ、その回数や観測された日数を考慮して計算した結果、先程の5つのポートが上位に上がってきました。
これらのポートへの過去30日間のアクセス履歴を確認してみます。

図: 2020年8月3日のTF-IDF上位5ポートの過去30日のアクセス履歴
左から4番目のポート、TCP 9530番ポートへのアクセス推移が特徴的ですね。このポート番号はMiraiの亜種でよく利用されるポート番号です。決して新しいものではありませんが、今でも不定期に活動が活性化します。パケットヘッダを調べてみたところ、Mirai亜種にみられるヘッダの特徴が確認できました。よって、このアクセスはMirai亜種が2020年8月頭に再活性化した影響と推測できます。8月3日前後のアクセスログを確認してみると以下の図のようになります。

図: 2020年7月から9月のTCP 9530番ポートアクセス推移
8月3日にTF-IDF上位に登場したTCP 9530番ポートですが、その後半月ほどでアクセス数のピークを迎え、40日程で沈静化していったことがわかります。7月30日に再活性化が始まり、4日後の8月3日にその動きが検出できたわけですが、その後の傾向をみてみるとそれなりに良いタイミングでの発見できたと言えるかと思います。
UDPポートアクセス
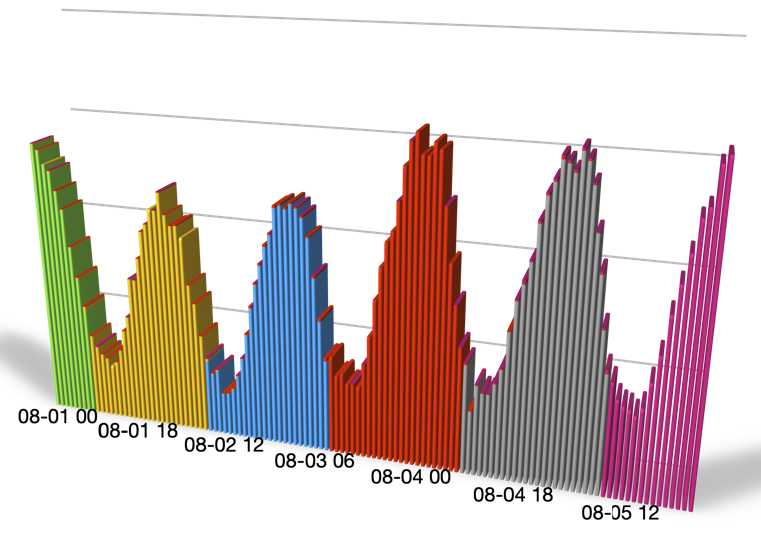
UDPポートに関しては、TCPポートとはまた違った発見がありました。UDPポートのTF-IDFを計算してみると、毎日ひとつのポート番号が特に高いTF-IDFの値を示していることがわかりました。ここでは2020年8月1日から5日までのポート番号を取り上げます。
- 8月1日: UDP 58246番ポート
- 8月2日: UDP 51455番ポート
- 8月3日: UDP 59483番ポート
- 8月4日: UDP 57591番ポート
- 8月5日: UDP 60609番ポート
それぞれのポートは、特定の一日だけ特に活発にアクセスされており、他の日にはほとんどアクセスが見られませんでした。これらのポートへのアクセス頻度を1時間単位でグラフにしてみたものが以下の図です。

図: 2020年8月1日から8月5日に高いTF-IDF値を持っていたUDPポートへのアクセス頻度の推移
一連のポート番号へのアクセス数を同時に描画してみると、これらの動きがそれぞれ独立しているものではなく、ひとつの大きな動きの一部であることがわかります。特定のポートへのアクセスは日本時間の9時(世界標準時では0時)に始まります。アクセスは24時間継続した後に突然終了し、類似したアクセスが別の特定ポートに対して観測されます。
アクセス数の変化が24時間周期の波状になっていることから、何らかの社会的な活動周期と関連していると予想しています。これらのアクセスに使われたパケットを調べてみたところ、ソースIPアドレスは広範囲に分散していることがわかりました。もっとも、UDPパケットですからソースIPアドレスは詐称されていると思われます。パケットサイズは70から200バイトの間で、均等に分散していました。ソースUDPポート番号は、ほとんどのものがRFC6056でエフェメラルポートとしての利用が推奨されている範囲(49152~65535)に収まっているようです。手元のデータで分かったことはこれくらいで、残念ながらこれ以上の詳細は分かりませんでした。
もし、このトラフィックに関して何か情報をお持ちの方がいたら、ぜひ意見交換させていただきたいところです。
おわりに
今回は自然言語処理で広く使われてきたTF-IDFをトラフィックデータ解析に応用する取り組みを紹介しました。この手法を用いることで、いくつかの興味深いアクセスを発見することができました。ここで紹介した手法はアクセス傾向の変化検知が目的です。変化があったことは分かりますが、それが必ずしも何かの攻撃に結びつくわけではありません。ただし、そういった動きを大域的な視点で把握することは後々役に立つと思います。