GPT-4oから登場した新しいトークナイザ「o200k_base」
2024年06月06日 木曜日

CONTENTS
新しく登場したOpenAIのモデル GPT-4o (GPT-4 Omni)
ここ最近、OpenAIが新しいモデルをリリースして話題になっていますね。その名もGPT-4o(末尾のoは小文字の「オー」)。この「o」はOmniを意味していると言われています。このモデルはその出力パフォーマンス(回答生成スピードの速さ)がものすごく速いと言われていますね。
恐らくは推論エンジン側のハードウェア・ソフトウェアの強化もあるのだろうと思われますが、その中でも我々の目から見て特徴的だなぁと思えるのがそこで使用されているTiktokenと呼ばれるOpenAI製トークナイザの新しいエンコード体系です。
https://github.com/openai/tiktoken/blob/main/tiktoken/model.py
にて紹介されていますが、これまでのGPTモデルで使用されてきたエンコード体系は「cl100k_base」と言われてきました。これに対して新しいエンコード体系は「o200k_base」と書かれており、GPT-4o限定で今のところは使用されているエンコード体系のようです。
# TODO: these will likely be replaced by an API endpoint
MODEL_PREFIX_TO_ENCODING: dict[str, str] = {
# chat
"gpt-4o-": "o200k_base", # e.g., gpt-4o-2024-05-13
"gpt-4-": "cl100k_base", # e.g., gpt-4-0314, etc., plus gpt-4-32k
"gpt-3.5-turbo-": "cl100k_base", # e.g, gpt-3.5-turbo-0301, -0401, etc.
"gpt-35-turbo-": "cl100k_base", # Azure deployment name
# fine-tuned
"ft:gpt-4": "cl100k_base",
"ft:gpt-3.5-turbo": "cl100k_base",
"ft:davinci-002": "cl100k_base",
"ft:babbage-002": "cl100k_base",
}
途中書かれている100k/200kというのは、そのままトークンIDのおおよその総数と言えるかなと思います。
だいたい中小規模のローカルLLMですと、LLamaTokenizerが使われてることが多かったりして、その場合は32kであることが多いです。GoogleのローカルモデルであるGemmaではGermmaTokenizerというものが使われており、そのトークン数は凡そ256kあります。
ローカルモデルですと、そのトークンIDと文字列あるいは文字的なものがJSON形式で対応付けられ、「tokenizer.json」というファイルに格納されています。単純にトークンIDと文字列の対応付けが記録されているだけですので、その容量は32kサイズで凡そ2MB程度とそれほどファイルサイズは大きくありません。中身はこんな感じで表現されています。(以下はMistral-7b-Instruct-v0.3モデルにおけるその中身です)
"দ": 31638, "Ṣ": 31639, "録": 31640, "伊": 31641, "落": 31642, "雄": 31643, "雪": 31644, "映": 31645, "著": 31646,
Transformerをベースにしている昨今の大半のLLMは、入力された文字列をTokenizerと呼ばれるプログラムを通じてまずはこのトークンID体系に変換され、一度IDの羅列に変化し、見た目的に数値化されます。
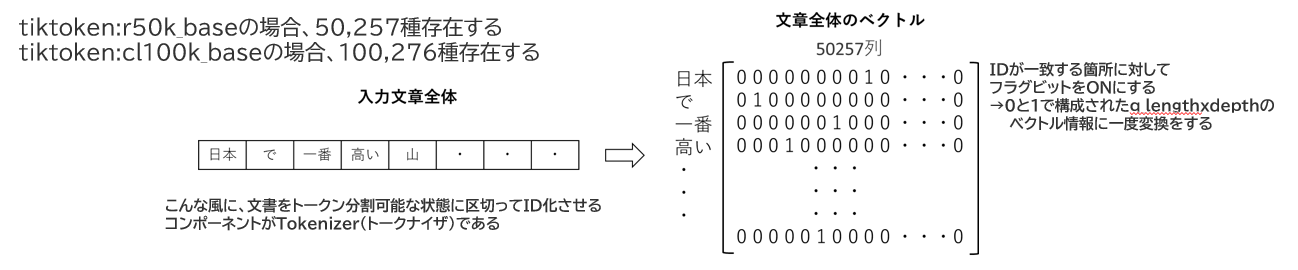
これがその後Embedderと呼ばれるプログラムによって行列変換させられ、ようやくコンピュータで処理できる形となり、その後のプロセスを経て「次に来るであろうトークン」を予測することで、私たちが求める回答として文章が出力されるようになっています。
つまり、トークナイザというのは私たちの自然言語とコンピュータで理解するための一次データに変換する橋渡し的な役割を担っているわけなんですけれども、ここに登録できる語彙数がそれまでのGPTモデルと比較して倍になったということですね。
とりあえず新旧トークナイザの変換結果を見比べてみよう
というわけで、トークナイザの違いを見てみたいなーとtiktokenのバージョンを上げてみました。
$ pip install -U tiktoken
Looking in indexes: https://pypi.org/simple, https://pypi.ngc.nvidia.com
Requirement already satisfied: tiktoken in /home/aiuser/miniconda3/envs/tiktoken/lib/python3.11/site-packages (0.5.2)
Collecting tiktoken
Downloading tiktoken-0.7.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (6.6 kB)
Requirement already satisfied: regex>=2022.1.18 in /home/aiuser/miniconda3/envs/tiktoken/lib/python3.11/site-packages (from tiktoken) (2023.12.25)
Requirement already satisfied: requests>=2.26.0 in /home/aiuser/miniconda3/envs/tiktoken/lib/python3.11/site-packages (from tiktoken) (2.31.0)
Requirement already satisfied: charset-normalizer<4,>=2 in /home/aiuser/miniconda3/envs/tiktoken/lib/python3.11/site-packages (from requests>=2.26.0->tiktoken) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /home/aiuser/miniconda3/envs/tiktoken/lib/python3.11/site-packages (from requests>=2.26.0->tiktoken) (3.6)
Requirement already satisfied: urllib3<3,>=1.21.1 in /home/aiuser/miniconda3/envs/tiktoken/lib/python3.11/site-packages (from requests>=2.26.0->tiktoken) (2.1.0)
Requirement already satisfied: certifi>=2017.4.17 in /home/aiuser/miniconda3/envs/tiktoken/lib/python3.11/site-packages (from requests>=2.26.0->tiktoken) (2023.11.17)
Downloading tiktoken-0.7.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.1 MB)
qqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqq 1.1/1.1 MB 13.7 MB/s eta 0:00:00
Installing collected packages: tiktoken
Attempting uninstall: tiktoken
Found existing installation: tiktoken 0.5.2
Uninstalling tiktoken-0.5.2:
Successfully uninstalled tiktoken-0.5.2
Successfully installed tiktoken-0.7.0
0.5.2から0.7.0へバージョンが上がったことを確認しました。
続いて、引数からトークン列に変換して、そのトークン長を求めるスクリプトをざざっと書きました。
import tiktoken
import sys
# エンコード
enc = tiktoken.get_encoding("o200k_base")
enc_old = tiktoken.get_encoding("cl100k_base")
tokens = enc.encode(sys.argv[1])
tokens_old = enc_old.encode(sys.argv[1])
print("o200k_base:")
print(len(tokens))
print(tokens)
print("cl100k_base:")
print(len(tokens_old))
print(tokens_old)
で、何か適当な例文を突っ込んで実行してみました。結果は以下の通りです。
$ python tiktoken-demo.py "ワタシらは未来のために船出するんや!と細々いそしんでおります。これが九州支社 事業推進部 技術推進課です。" o200k_base: 44 [34022, 12288, 13668, 8870, 5205, 66231, 3385, 103912, 5280, 76683, 6390, 39065, 6676, 19160, 3393, 5330, 51251, 68975, 3826, 11275, 3829, 6676, 4344, 127204, 788, 54459, 6632, 17990, 13465, 18904, 12330, 220, 8669, 23784, 11800, 77897, 8572, 154255, 45463, 11800, 77897, 155126, 15121, 788] ['ワ', 'タ', 'シ', 'ら', 'は', '未来', 'の', 'ため', 'に', '船', '出', 'する', 'ん', 'や', '!', 'と', '細', '々', 'い', 'そ', 'し', 'ん', 'で', 'おります', '。', 'これ', 'が', '九', '州', '支', '社', ' ', '事', '業', '推', '進', '部', ' 技', '術', '推', '進', '課', 'です', '。'] cl100k_base: 59 [2845, 107, 47307, 57207, 33503, 15682, 39442, 37507, 16144, 28713, 62004, 20230, 63105, 117, 20834, 54926, 25827, 71289, 6447, 19732, 27869, 108, 1300, 227, 16995, 27929, 15024, 25827, 16556, 33334, 31431, 33541, 1811, 85701, 29295, 18259, 251, 55139, 46456, 61337, 220, 30926, 61964, 255, 84851, 11589, 110, 34048, 97255, 222, 13079, 241, 84851, 11589, 110, 45918, 110, 38641, 1811] ['ワ', 'タ', 'シ', 'ら', 'は', '未', '来', 'の', 'た', 'め', 'に', '船', '出', 'する', 'ん', 'や', '!', 'と', '細', '々', 'い', 'そ', 'し', 'ん', 'で', 'お', 'り', 'ます', '。', 'これ', 'が', '九', '州', '支', '社', ' ', '事', '業', '推', '進', '部', ' 技', '術', '推', '進', '課', 'です', '。']
例文の長さは全角53文字です。
o200k_baseでエンコードされた結果、その配列長は44になりました。
cl100k_baseでエンコードされた結果、その配列長は59になりました。
cl100k_baseに比べて、どうやらo200k_baseにすることで、こんな感じの日本語文章であれば、およそ74.5%程度の長さに圧縮されるようです。
トークン長が短くなることのありがたみ
元々Tiktokenには日本語だと特に際立つ弱点があり、それは「日本語におけるトークンの変換効率が悪い」というものでした。ChatGPTが登場したころからよく言われていたことなのですが、Tiktokenは英語やアルファベットを主体とする言語においては1単語=1トークンに変換してくれるのですが、日本語においてはかなり「1文字=1トークン」で処理する比率が高く、これが推論で足かせになっていました。その理由は、「単語単位で推論するよりも、文字単位で推論をする方が大変」だからです。
文章は単語の羅列で構成されているものですが、単語単位に連ねるのであれば、単語の種類(主語・述語って観点から名詞・動詞・形容詞・副詞などなど)の性質上繋がりやすいものとつながりにくいものがあり、AI側も膨大な学習結果から、それらの特性に基づいて確率分布が構成されることが多いのです。そうした性質を考慮することで文章の破綻を押さえることが出来るのです。
しかし、文字単位の推論の場合、その文字自体の意味はまだ現在のAIでとらえることはできず、あくまで確率分布的な特徴から繋げて回るしかありません。膨大な学習で「大体正しいレベルで文が繋げられるようにはなっている」というレベルだとどうしても柔軟な回答を生成させる際にいくつかの失敗ケースを踏んでしまい、そこから大きく意味が逸脱してしまうようなケースも少なくありませんでした。
まだGPT-3.5-Turboがメインで利用されていたころなどでは、そうした事情を考慮してシステムプロンプトを英語で書くケースも多くありました。プロンプト量を削減することで課金を押さえるという目的もありましたが、それ以上にAIにとって推論しやすい言語体系で推論させ、それから日本語にもっていくようなケースもそれなりにあったように思います。
昨今、他のAIベンダーやOSS界隈などでは、こうしたトークンの単位を1文字から1単語にもっていこうとする動きは多く、その中で特に顕著なのがGoogleなのかなと思います。GeminiやGemmaはトークナイズデータをかなり大きく保有しており、GemmaTokenizerでもo200kを上回る256kものトークンID体系を保有していたりするので、かなり単語レベルでの日本語推論を可能にしているのではないかなぁと思われます。
さて、こうしてトークン語彙が増えることでこんなありがたみがあります。
- 推論スピードが上がる。
出力するトークンID量を減らすことが出来るということは、だいぶ単語単位でIDがまとめられているということで単位時間に出力される文章量が増えることを示しています。 - 文章の崩れが発生しにくくなる。
これも単語単位でまとめられたことで、日本語の文章として文字単位の推論比率が減り、単語同士の結合をするケースが増えることから、文章が崩れにくくなり品質が向上します。 - 学習データの結びつきがより単語単位で行えるようになる
所謂AttentionレイヤーやMLPレイヤー内における単語間情報がかすみ難くなります。 - コストが減ります。
1つの文章を出力するために必要となるトークン量が減るので、Prompt及びCompletion共にボリュームが減って課金額が減少します。
但し、これはあくまでトークン単位課金を採用している場合に限られ、文字数単位とかで課金しているようなケースでは効果はありません。
旧モデルを堅守することはあまりお勧めしない・・・・・・が。
このように、トークナイザ体系が新しくなるだけでもそれなりに推論速度は上がりますし、出力結果の内容もより良いものになっていくことになります。逆に古い推論モデルはそこからおいて行かれてしまう形となり、そうしたパフォーマンス的な部分のデメリットがより際立ってしまう事にもなるので注意が必要です。
また、Copilot等様々なAI組み込み済みツールが登場してきたこともあり、以前は遅い推論でも待っていられたものが気づかぬうちに高速な出力に慣れてしまって、いざ古いモデルから推論させた際に「なんでこんなに遅いんだ!」ってなってしまうことも決して少なくはありません。実は旧モデルが「遅くなった」のではなく、単に「今のモデルが速すぎる」だけなのかもしれないなってことを頭の片隅にとどめておくとよいかなと思います。
ファインチューニングとかをしない限り、基本は旧モデルを使い続けることはあまりお勧めしません。とは言え、学習内容が偏っていたり、アップデートしたモデルが微妙な応答を返すようになっていたりなどの問題はないとは言い切れないことから、今後こうしたディープラーニングモデルのアライメントを担うところの第三者的な性質がより強く求められるような気がすると共に、そこが破綻したときの我々に対する影響って計り知れないものがあるんじゃないかと若干現在の状況を危惧していたりもするところです。