インフラ一筋のおじさんが画像生成AI“Stable-Diffusion”を読み込んでみる件
2022年10月03日 月曜日

CONTENTS
なんだかAIって流行ってますよねー
こんにちわ。九州支社で細々と遊んで検証業務にいそしんでいるとみーです。
2022年3月から、どーしても「名前だけ知ってる状態」ってのにもやもやしていて、Deeplearningに手を付けたものの、あまりに内容が奥深すぎて沼にドはまりして周囲に「たすけてぇ、たすけてぇ」って叫んでいる素敵な日々を過ごしています。
取りあえず画像処理としてディープフェイク、NLP(Natural Language Processing:自然言語処理)として簡易チャットボットに取り組んでみたりしてました。オンプレミス時代だとリソース関係がぁって七転八倒してましたが、AzureVMがあるとホント便利ですね。課金に気を付けながらNVIDIA A100に触れるとか夢みたいっす。
全く知らない状態からDeeplearningに手を付け始め、まださすがにコードを書くってレベルには至らないですが、Deeplearningってこんなことをしてるのかとだいぶ奥深くなところを見ることができるようには少しずつなってきました。それがどれだけの実力感なのかは私にはまったく理解できないんですが、取りあえず何も知らないことを覚えて学んで目に見て実現性の評価ができるようになったのはうれしい限りです。
プライベートでは、最近趣味のお絵描きで色々不都合が多かったオンボロQuadro(K2000)を奮発してQuadro M2000にしました。え、それでも古い?いやぁ・・・・実験やったり趣味やったりするとお金が自腹でも飛ぶんで(例えば会社に許可もらうような代物じゃなかったり、すぐに手を付けたいものだったり)ねぇ、同情するなら○をくれ!ということでどうぞお察しください。
そんな中、Deeplearningを使った夢のある何かを作るケースがそこかしこに見られるようになったので、そのネタを一つ取り上げようと思ったのがStable-Diffusionです。
Stable-Diffusionとは
2022年8月23日、テキストを画像に変換するAIがオープンソースとして公開されるとのことで、一部界隈が大盛り上がりしました。そのソフトウェアの名は「Stable-Diffusion」。現在、GithubリポジトリとHugging faceリポジトリで絶賛公開中です。
これを作ったのは、ドイツの大学のいち研究室とイギリス・アメリカにてスタートアップしたベンチャー企業であるStability AIという会社です。所謂産学連携規格で誕生したソフトウェアです。
研究室と言ってるのは、「ミュンヘン・ルートヴィヒ・マキシミリアン大学 マシンビジョン&ラーニング研究グループ」というところでして、リポジトリ名のCompVisって言うのはおそらく「Computer Vision」を略したものと考えられます。
そこでは、Latent Diffusion ModelというAI学習モデルの研究をされているようで、Stable-Diffusionというのはその副産物と言えるようなものです。
8月23日に何が公開されたのかというと、このLatent Diffusion Modelという学習モデルを使用して二十数億枚の画像データとテキストデータを学習させた「事前学習モデル」が公開されたのです。
今回、インフラ一筋19年ちょっと、あまりコードを組んだこともないような筆者が、様々な論文やGithub上のソースなどを眺めて処理を読み込んできた内容の内、何とか理解できたことについてまとめてみたものになります。
Stable-Diffusionで話題になったところとは?
テキストから画像へ変換する処理というのは、Githubリポジトリに公開されているものの内、
scriptディレクトリ内にある txt2img.py というPythonで書かれたスクリプトです。
例えば、Stable-Diffusuionを導入した環境上で、以下のようなコマンドを入れるとこんな画像が出てきました。
python scripts/txt2img.py \ --prompt "A beautiful, kawaii girl with Akira Toriyama style eyes and Dragon Ball style hair, medium sized eyes and long eyelashes, smiling." \ --plms --n_sample 1 --n_iter 1 --scale 20.0 --seed 23800 \ --ddim_steps 50
出て来た画像

とある漫画風のいい感じの画像が誕生しました。
promptに書かれてる通り、「鳥山明風の瞳とドラゴンボール風の髪、中くらいの瞳と長いまつ毛のカワイイ美少女が微笑んでいます。」と入力した結果なのですが、なんとなく確かにそれっぽく見えるような絵になりました。
デフォルト設定ではサンプル数3、生成処理の繰り返し回数は2に設定されているんで、3×2の方眼構成で絵が表示されるんですが、手軽に文章を書けば絵が表示されるというのは確かにすごいですよね。丁度これが登場する少し前に midjourney という同様のサービスが商用として登場したこともあり、このStable-Diffusionをさらに有名にさせたのでは?と感じています。
Stable-Diffusionの実体は?
Stable-Diffusionの実体というのは、このプログラムではなく、この日に初めて公開されたHugging faceというAIの学習モデルを多数収録しているサイト上に登録された4つのチェックポイントファイルと呼ばれるものになります。
事前学習モデルは以下のURLで公開されています。
https://huggingface.co/CompVis
ここには、stable-diffusion-v1-1からstable-diffusion-v1-4までの4つのファイルが存在しており、ファイル名はsd-v1-1.ckptから sd-v1-4.ckpt までの4つのファイルが入手できます。いずれも4GB程度のかなり大きなファイルです。
これは、v1-1がベースとなっていて、v1-2,v1-3,v1-4となるにつれて、特定のデータセットを追加学習させています。その内訳は以下の通りです。
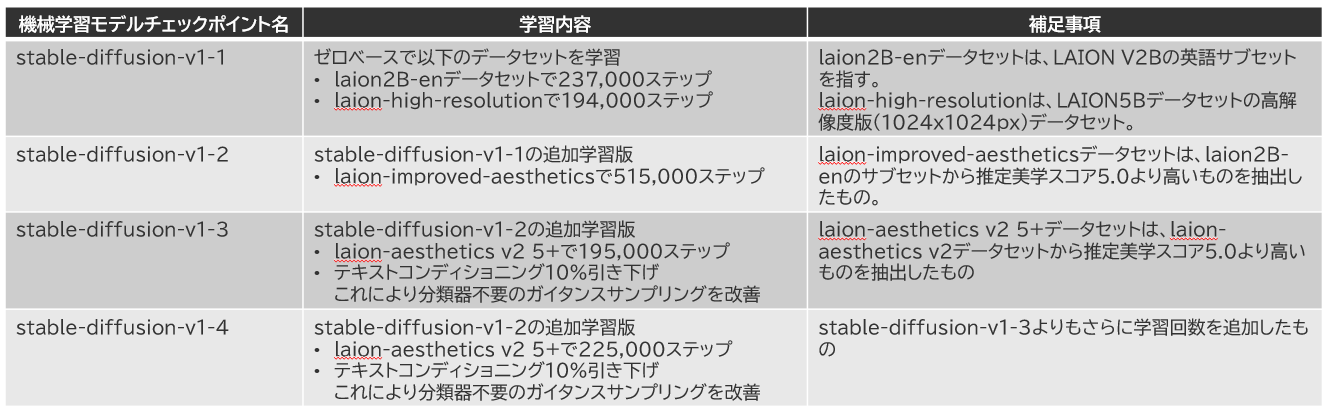
学習に使用されたデータセットはLAIONと呼ばれる非営利団体が提供しているデータセットで、実に様々な画像とそれに紐付くCaptionデータが大量に提供されています。Stable-Diffusionではその中でもlaion2B-enデータセットの数が多く、二十数億枚が収録されていると言われています。そんなモデルがv1-1であり、さらに追加学習されたのがv1-2、それをベースにさらに改良を施して学習回数を少な目に実施したのがv1-3、多めに実施したのがv1-4となっているわけですね。
Stable-Diffusionというのはそれ自体がAIの学習モデル構造を表すものではなく、ある特定のモデルを使用して、大量のデータセットでAIを鍛え上げた結果作られた、AIの脳みその中を指しているのだということを理解してもらえればと思います。
さて、じゃぁ一体どんなAIモデル構造を使用して学習させたのだろう?という所が気になる人もいらっしゃるのではないかなと思います。それがStable-Diffusionのベースとなる Latent-Diffusion-Model というものです。
これを説明するには、AIって言うのが何をしているのか?という所から考えることから始める必要があります。
AIとは何をしているのか?Deeplearningとは何か?
世の中AIって言葉は何度も歴史の中で登場していますが、AIというのは概念であり、その歴史の中で様々にその実現方法は変わっていってます。現在のその実行方法に相当するのがDeeplearningという手法です。
何をしているかというと、数学的な数値計算を大量に行うことで「特徴を取り出す」ということをしています。
私はこれを「雰囲気」と呼んでいて、ユーザが何かを求める「雰囲気」をつかみ取って、その雰囲気から実際にどんな応答を求めるのかという所を蓄えた情報をもとに「きっとユーザはこんなのを欲しがってるんだろう」と最も求められてそうな答えを返すというものです。
Deeplearningをあまり詳しく存じ上げない私はこうした一連の行動を「空気を読む」と表現しています。
数学って非常に便利なもので、だいたいのことは数学に表せると言えるほどに表現力が豊富な世界でして、例えば画像なんかは「画素」と呼ばれる点の集合体として表示できるわけですが、それは以下のような感じで数学的に表現することができます。
写真は画像処理分析を学ぶ際に使用したDeepFaceLabというOSSなディープフェイクツール(参考文献に記載)内に収録されているサンプルデータであるイーロン・マスク氏の合成前動画を引用しています。

言葉なんかも実は数学的に表現できます。これは単純な表現ですが、アスキーコード表みたいに文字を何かしらのIDを割り当て、それを使用することで数学的な表現と言いますか、何かの信号波形のようなものに仕上げることができます。(これは一例です)

数値化された画像データや言葉には何かしらの特徴があります。同時に、言葉データの例を見てみると、不要な情報もたくさんあります。なにも使用されていない0ばかり埋まっている個所なんかがそうです。Deeplearningの処理では、
- 0だらけ・・・のような不要な情報は極力捨てる
- どっかが尖ってる、どこから上がってどこから下がるみたいな特徴は「際立たせる」
ということを行い、より印象を強くしつつ無駄なデータを削減していくような処理が行われています。
こうすることで、コンピュータにとって雰囲気というものがより理解しやすくなるのです。こうした行為を何万、何百万、或いは何十億繰り返して覚えさせることにより、人間の持つ認識とコンピュータの持つ認識を近づけていく行為を「学習」と呼んでいます。
その学習をさせるためにAIにさせる一連の工程を「学習モデル」と呼んでいます。
画像処理における学習モデル(一部)
学習モデルを論じるのはなかなか時間を要するところですので、画像処理に内容を絞って2つの学習モデルを紹介したいと思います。画像の雰囲気を理解させるための学習モデルとして、有名なものにAutoEncoderというのがあります。
AutoEncoder
学習させる画像をエンコーダと呼ばれる回路に突っ込み、「特徴の強化」と「無駄なデータの削減」を行わせ、潜在空間と言われますが、要は特徴データベースみたいなものにどんどん放り込んでいきます。
AIは特徴データベースにため込んだ情報をもとに、空気を読んで「きっとこんな画像を作ってほしかったんだろう」と元画像を推測します。この推測したものを画像化するのがデコーダーで、出力結果は画像となります。当然、学習回数が少なかったり、特徴データベースの情報量が十分でないと似ても似つかぬ画像が出来上がります。
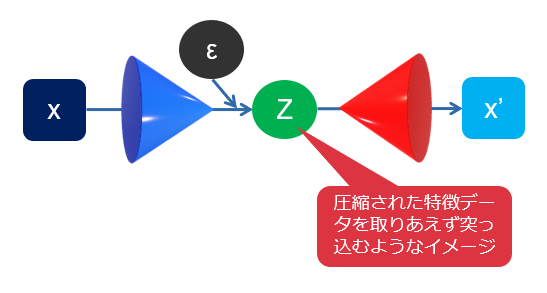
これを審議するのが損失関数と言われる部分で、元の画像から推測画像がどれだけかけ離れてるかを算出し、その算出結果をオプティマイザに渡します。オプティマイザはより損失関数値が下がるように、特徴データベースに突っ込むのとは別のパラメータと呼ばれる部分をいじって、より求めた画像から外れにくくなるようにチューニングをしてくれます。
これを幾度も繰り返すことにより、特徴データベースの持つ認識が人間に近づいていく形となり、結果として求めた画像をより正確に推測できるようになります。
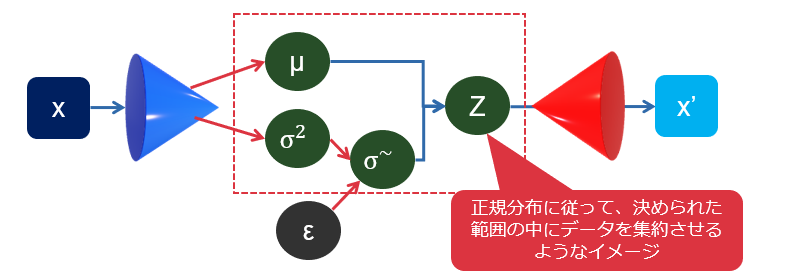
これの発展形として、より本質の抽出が得意なVAE(Variational AutoEncoder)やさらに進化したVQVAE(ベクトル量子VAE)といったものがあります。以下はVAEの構造を描いたものです。
Diffusion-Model
Diffusion-ModelというのはAutoEncoderというものとは全く違う思想で作られていて、こういう仮定が存在します。
- 画像に対してガウシアンノイズ(正規分布に基づくノイズデータ)を加えると
- 画像は特徴を少し失う
- その分ノイズが乗る
- 画像の特徴は無限ではないから、無限にガウシアンノイズをかけまくると、画像は特徴を完全に失ってノイズだけの画像になるのではないか
ということは、
- 完全なガウシアンノイズは数式で表現できる代物だから、逆算プロセスも成立するはずだ
- 画像に掛けたガウシアンノイズに逆算したデータをかけ合わせれば、最終的に元の画像が作れるのでは?
と考えられるというわけで、それらをアルゴリズムとして採用したものになります。図式的には以下の通りとなります。
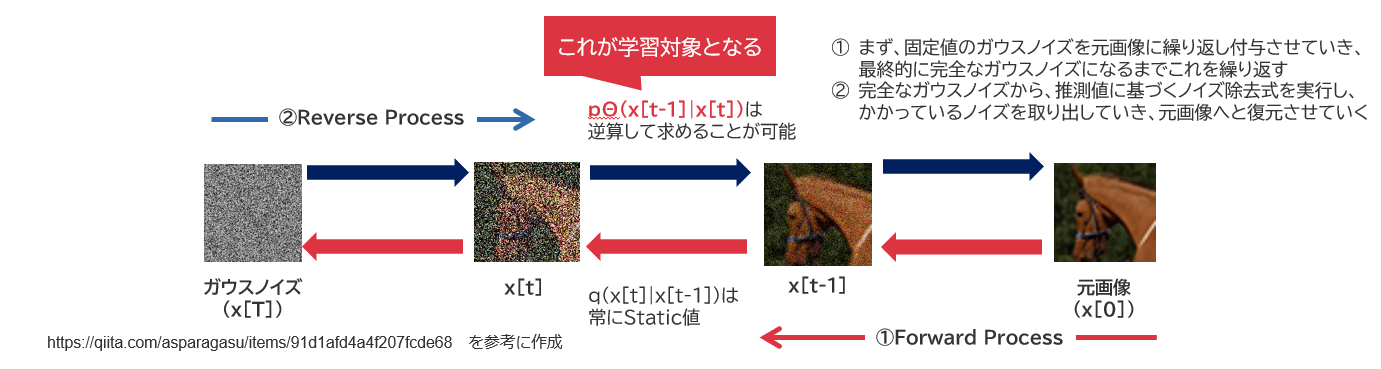
Forward noise processでは一定のノイズパターン、一定のノイズ強度で元画像にガウシアンノイズを加えていきます。
Reverse noise processでは、今より1ステップ前に掛けられたノイズと逆パターンのノイズを逆算により推定して、ノイズ交じりの画像を予想します。それをAutoEncoderでやってたように現画像と予想画像の比較・チューニングを行うことでより元画像に近づくようにしていきます。大量に繰り返しを行わせる点はAutoEncoderと同じです。
このあたりについては、実はGoogle Research, Resarch Scientistの小泉悠馬さんのスライド資料を参考にさせて頂きました。
数式の読み方の一例を示してくださっており、非常にわかりやすい資料ですので、興味ある方は是非一読ください。
https://speakerdeck.com/yumakoizumi/kuo-san-que-lu-moderutoyin-sheng-bo-xing-sheng-cheng
Diffusion-Modelは、AutoEncoderの取る方法とは全く異なるアプローチをとっていて非常に面白い仕組みであるわけなのですが、AutoEncoderのように無駄を省くということをしないため、膨大な計算リソースが必要になります。その為、もう少しこれを効率化できないかとして編み出されたのがLatent-Diffusion-Modelになるのです。
Latent-Diffusion-Model
Diffusion-Modelでは画像データそのものに対してノイズ除去をしていました。
Latent-Diffusion-ModelはAutoEncoderの合わせ技を行っており、論文ではVariational AutoEncoderに挟まれた特徴空間と呼ばれる雰囲気データベースみたいなところに対してDiffusion-Modelを実行させています。特徴空間は元データと比べて圧縮された情報であるため、データ量はかなり小さくなっています。ここに対してDiffusion-Modelを実行することにより、より効率的にノイズ乗せ・ノイズ除去のプロセスが実行できるということを示しています。恐らくStable-Diffusionに向けて使用されたモデルは以下のような構成なっています(後述の文献High-Resolution Image Synthesis with Latent Diffusion Modelsより引用)。

データセット上にはサンプル画像、サンプルCaptionが保存されており、それぞれしかるべきエンコーダーを通過してベクトル化されます。画像に関してはさらにエンコーダーの機能によりコンパクト化され、特徴情報としてZに格納されます。Captionは不要情報の除去や形態素解析などが行われ、様々な押さえておくべき単語情報がベクトル化されてエンコーダーに通されます。
ここで、画像データはDiffusion-ModelにおけるForward noise processが行われ、その結果がZtとなります。ここで入力されるCaption情報との関連付けを行いつつ、ノイズ除去処理が行われ、画像の推測が行われるわけですが、1回のノイズ除去ではきれいにノイズは外れませんので、繰り返しこれを実行し、ノイズ除去ユニット上のパラメータがそのたびチューニングされていくと共に、予測除去式を用いたノイズ除去処理が数学的データの状態で繰り返し行われていきます。最終的にはデコーダーで画像化されて予想画像が出力されることになります。
厳密に言えば、ガウシアンノイズは一気に外そうとするとピンボケしたような画像になると言われています。その為、一気に外すのではなくよりクリアな画像が生成できるようなレベルでガウシアンノイズを外すような動きを繰り返し行うようになっています。このノイズ外しの方法は実にたくさん存在しており、現状私がここで説明しているやり方はDDPM(Denoising Diffusion Probablistic Models)という所謂「じわじわとノイズを外す」的なものを想像していただくと良いかと思います。
実際のStable-Diffusionでは、これよりももっと計算効率を良くしたものであるDDIM(Denoising Diffusion Implicit Models)やPNDM(Pseudo Numerical methods for Diffusion Model)と呼ばれる手法が使用できるようになっています。
Stable-Diffusionとして使用するときは、こんな処理が行われています。
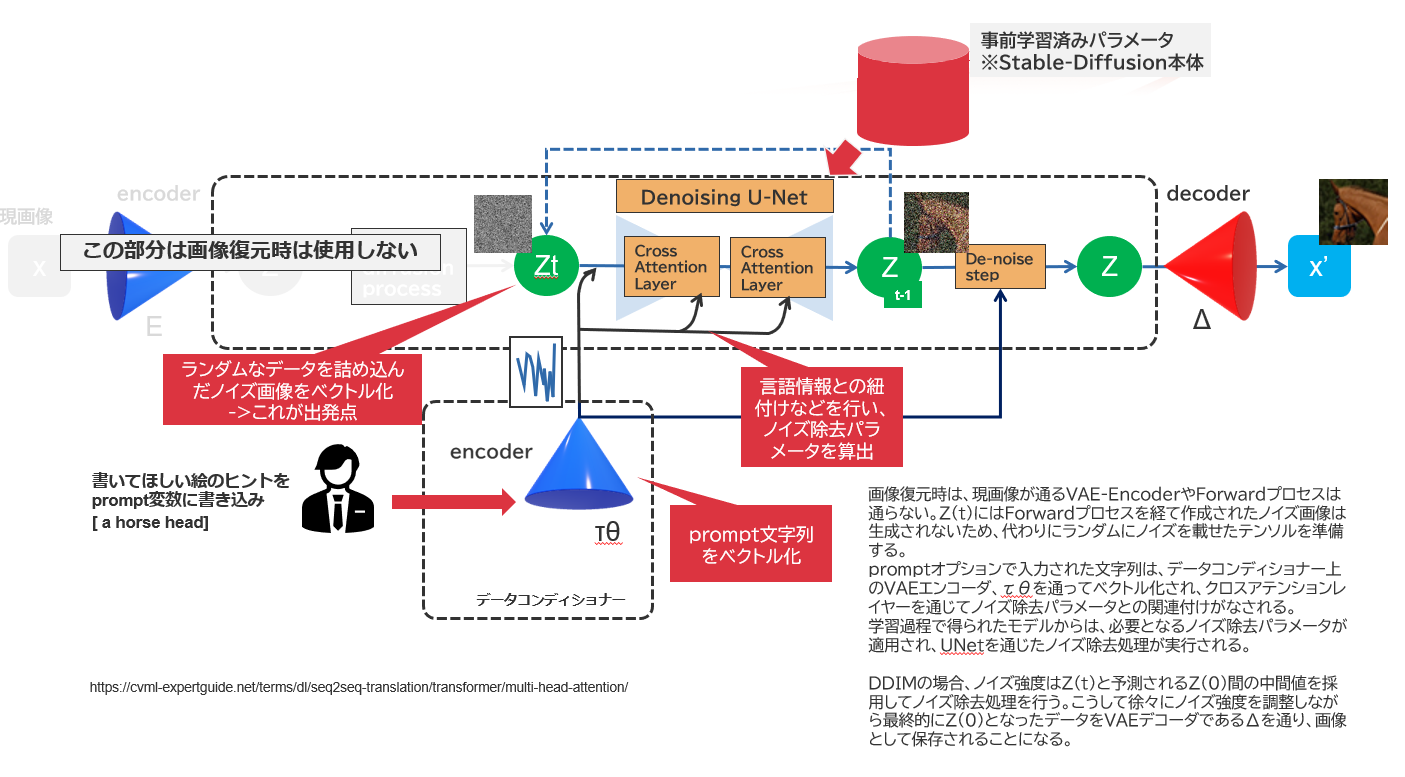
Stable-Diffusionとして動かす場合は、既に学習済みモデルがあり、チューニング済みパラメータがDenoise-Processの中に構成されています。その状態で、データコンディショナー側のエンコーダーにPrompt文字列を投入し、関連するCaptionとうまく適合する絵の組み合わせをサンプリングしていくような構成になっています。よって、あくまでStable-Diffusionは出来上がり済みのモデルであり、別にここから追加学習をすることはなく、ただひたすらに持ちうるデータで画像を推測していく・・という構成になっているのかなと思います。
データセットはEnglishを前提にしているため、これを日本語対応させるとかになりますと、
- 日本語を英語に翻訳してモデルに投入する処理をつくる
- Latent-Diffusion-Modelにて、徹底的にjaデータセットを使用して学習させまくる
とかになるのかなーという気がします。
GPUを必要とし、かつVRAMを10GB必要とする理由は
Stable-Diffusionでは、VRAM要件が明確にあり、10GB以上の搭載が求められています。そもそもモデルデータが4GB以上存在し、これに加えて付随するPytorchを中心とするディープラーニング処理で使用する行列データの配置量が多いからだろうと予想しています。実は、Stable-Diffusionを動かすには、画像予測処理をするために必要データを全て載せなければならないという制約が存在するのです。
Deeplearningというものは、非常に多くの計算を必要とします。
しかもそれは数学的に表現された行列とは言え、四則演算の中でも「足し算・掛け算」の比率が非常に高いのが特徴です。例えば先述したAutoEncoderでは、行列の「たたみ込み」という計算が圧縮工程で行われるのですが、そこでは実際に「内積」という計算が行われています。この内積計算は掛けて足しての連続を行うような演算です。
実は、GPUは行列の足し算・掛け算がものすごく得意なのです。というよりは逆に言えばその速度を追求するためにCPUだと備わってる投機実行機能や分岐予測機能をかなぐり捨てており、極限まで計算に特化したユニットになっています。
その為、プロセッサコアを極端に小さくでき、プロセッサダイサイズに対して大量のコアを実装できるのが特徴です。
昨今、Intel Xeonでも40コアあたりが精いっぱい、AMD EPYCでも64コアが最大である中、NVIDIA A100と呼ばれる1世代前のハイエンドGPUでは6,912ものCUDAコアが実装されています(A100 PCI-e)。ただ、単体コア性能はCPUと比較して圧倒的に劣っており、だいたい1/10程度の性能だったりします。動作クロック数も最近ではあまり変わらなくなってきた印象も受けますが、やっぱりCPUには及んでいません。
ですが、コア数の比較をした時点でけた違いにGPUの方が多いわけで、並列計算で勝負させると圧倒的にGPUの方が早いわけです。GPUの高速演算は「並列処理できてナンボ」の世界であることを認識しておいてください。当然、出てきた計算結果はバラバラに出てきますので、それをまとめるのはCPU処理です。そのため、GPUに精いっぱい計算をさせまくると同じぐらいCPUも処理を求められ、高負荷になります。
GPUが効率的に動くには、何千ものコアが同時にデータを取りに行けるぐらい帯域の広いデータバスが必要になります。VRAMはそれを実現させたもので、通常使用する汎用RAMがだいたい25.6GB/sec程度のバンドレートを持つと言われていますが、GPUはこれの10倍以上である320GB/secものバンドレートを持っていると言われています。その為注意点として押さえておかなければならないのが「計算させるそのデータ、全部VRAMに載りますか?」となります。
1bitでも載せきれなければGPUによる処理は行われず、一般的なケースで言えばプログラムは例外処理に回されて処理を中断します。プログラムの書き方によっては、CPU処理に移動させることもありますが、その場合は大体処理が遅すぎて使い物にならないケースがほとんどかと思います。
なお、参考までに申し上げると、デフォルトでは出力される画像のデータは512x512pxですが、この解像度を512x1024pxに設定して出力させたところ、およそ45GB程度のVRAMメモリ領域が使用されました。ディープラーニングってホントメモリを食うんですよね・・・
GPUは手加減を知らない
GPUは手加減を知らないようで、常にフルパワーで動作しようとします。その為、電源使用量がリアルにTDPに達します。
引きずられてCPUも最大負荷を要求されるので、こちらもTDPに達します。GPUサーバを動かしてDeeplearningしようぜーと考えている方々はぜひとも電源容量に余裕をもってハードウェア構成を行うようにしてください。

またこういう時はクラウドVMを使用するのも一つの手かもしれません。私はよくMicrosoft Azure VMでGPUインスタンスを使用していたりします。今回の検証も最近登場したNVIDIA A100 80GB VRAM搭載インスタンスを使用して実験していますが、こうしたクラウドVMはサイズの変更が比較的容易に行えるため、通常時は安価なGPUインスタンスを、ここぞというときにA100インスタンスをという形で切り替えて使うことで、月間のコストはわずか10,000円前後(純粋なVMの稼働額のみ)に収めることができています。
こういう所はある程度時間の読みも必要ですが、実行計画を立てながら動かしてみることで知見もたくさんたまるのではないかと思います。
検証で使用した構成
弊社ではこのような検証環境を組み立て、検証を行いました。
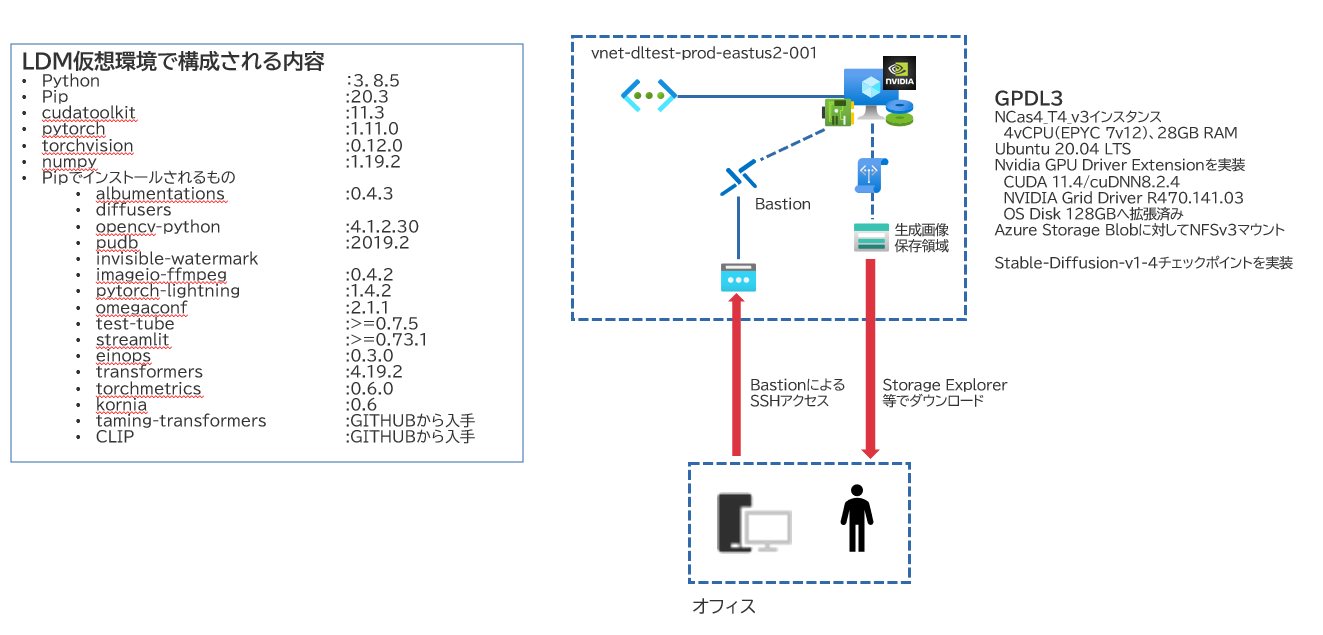
基本的にはEAST US2リージョンのAzureVMを使用して構成しており、生成された画像の配置はNFSv3でマウントしたAzure Storage (Standard v2)へ行うようにしています。出来上がった画像はAzure StorageのBLOBコンテナ上に配置されますので、Storage Explorerなどで入手するような形をとっていました。環境に関しては、Anacondaを当初は組み込んでましたが、のちにMinicondaに入れ替えを行っています。
OS操作はBastionを使用したり、あるいはJPEASTに置いてるVMからVNET Peeringを行ってTeratermでアクセスしたりなど扱い方は様々でした。
基本的な動作確認はTesla T4搭載インスタンスを使用していましたが、性能比較などを行うために一時的にNVIDIA A100搭載インスタンスを使用したりもしています。一度リソース切り離しを行った上でサイズ変更をすることで、待ち時間なしで切り替えが行えます。
この時、Azureが提供するNVIDIA GPU Driver Extensionは非常に便利です。その環境で必要なドライバ・CUDA・cuDNNの実装を自動で行ってくれます。こうした環境で試せたことに関しては、可能な限りでもう少し掘り下げて述べられたらなぁとか思ってます。
おわりに
今回、こうした所まで理解できたのはソースコードがあったこと、それに伴う研究論文が公開されていたことだと思います。
それでも完全に理解できたのか?と言われると全くそんな領域には到達できず、しかしながら数学というものからだいぶ離れていた私にもある程度それを思い出させてくれるような、そんな気付きや学びがたくさんありました。
ただ使うだけでも面白い代物ですが、どうしてそんなことができるの?って思いながら、あるいは「この単語ってどういう意味なの?」とか思いながらソースを眺めていくとそこから新しい世界が開けていくし、場合によっては新たなソリューションを見つけることだってあったりします。全く異なる分野のデータを視点を変えてみることだってできます。
私は先日齢44になりました。歳の衰えもありますし、神経難病による体の不調もあります。痛い・キツイ・苦しいなんて日常茶飯事ですが、そんな歳・体になっても衰えずにやっていきできるネタはまだまだこの業界豊富にあるようですんで、取り組めそうなものはどんどん取り組んでいくといいのではないでしょうか。取りあえず私はのめり込んだらその分苦痛が取り除かれるんで重宝しています(個人の感想です)。
追伸
先日、Stability AIが公開しているDreamStudio Betaへアクセスしてみると、このStable-Diffusion部分がさらにチューニングされたようで、事前学習モデルにStable-Diffusion v1-5なるものが誕生していました。加えて、サンプラーも別途OSS公開されているk-diffusionというソフトウェアで実装されているサンプラーがマージされているようで、DDIM/PNDMを使ったPLMSの2種類意外にたくさんの方法が選択できるようになっていました。
このあたりはGithubやHuggingFaceにも掲載されておらず、今後チューニングされていく学習モデルは有償サービスとして扱われていくのかもしれないなー・・・と感じました。実際、Stable-Diffusionが登場したことをきっかけに様々な学習モデルやサンプラーが公開されたように思いますし、技術的発展を遂げる起爆剤として、作者たちの狙い通りの結果にもしかしたら至っているのかもしれないです。
追伸その②-2023/2/9記述追加
その後Stable-DiffusionはStabilityAIが開発を進めており、2023年1月時点ではv2.1が登場しており、HuggingFace社提供のdiffusersライブラリからお手軽に利用できるようになりました。社内でもWeb素材づくりとかで役立てられないか?ということで、これを利用したツールを作って社内公開していたりします。
なお、実はVersion1の途中から、言語の関連付けで使用するベクトル化処理を担うエンコーダーにOpenAIがDALL-Eの副産物として公開しているOpenCLIPというエンコーダーを使用するようにしてるみたいです。Version2からは、さらにこれをLAIONのデータセットを使用して追加学習させたエンコーダを採用しており、精度がアップしたりします。
追伸その③-2023/2/16記述追加
追伸がだんだん重なってまいりました。これもどんどんStable-Diffusionが進化しているからなんですけれども。
今回は、これまでよく理解出来てなかったSamplerに関する記述を追加してみることにしました。実はDiffusion-ModelにおけるReverse Processをもう少し具体的なニューラルネットワーク構造を並べてみた場合、以下のような動きをしていることがわかっています。
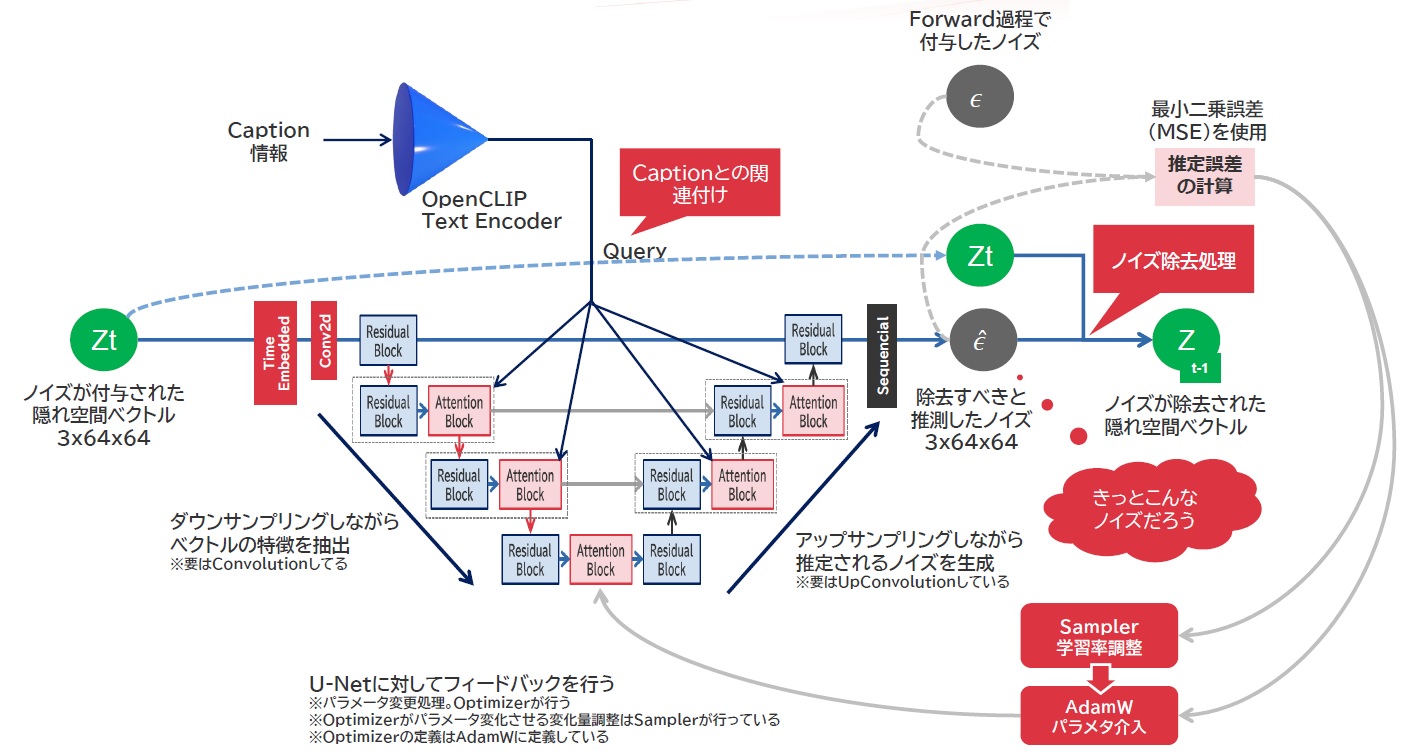
LDMにおけるデノイズプロセス
サンプラーは、当初Stable-Diffusion v1のころはPNDM(PLMS)もしくはDDIMの二種類しかありませんでしたが、Stable-Diffusion-v2になってから、これを進化させたサンプラーが多々登場しています。このサンプラーってそもそも何か?というと、LDMというモデルの中ではオプティマイザに働きかける「スケジューラ」として機能しています。スケジューラとは何かというと、例えばこのLDMを使ったStable-Diffusionでは、オプティマイザに「AdamW」という重み値による学習率減衰を自ら行う最新(?)のオプティマイザが動いているのですが、このオプティマイザがニューラルネットワークへ影響を及ぼす際に、何割影響させてもよいのか、その学習率を調整する役割を持っているのが「スケジューラ」という奴になります。
例えば今回、k-washiさんのソースをベースにWhisperの記事を書いたりもしたわけなんですが、その時のソースではこんなスケジューラが組まれてました。
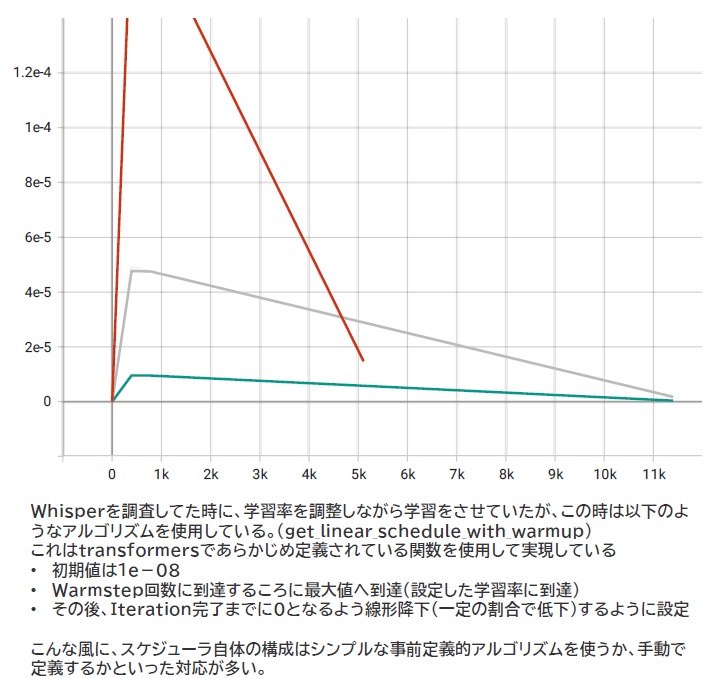
Whisperで使われていたスケジューラの設定
Whisperを活用した議事起こしツールを作成した時、当初は赤色のスケジューラを、途中で灰色・緑色のスケジューリングを試行し、最終的には灰色のスケジューラ設定が採用されました。ゆっくり減衰させていく方がどうやらきれいに求めるものが求めやすいという判断でこの時は選択をしています。
この時のスケジュールには、基本形として get_linear_schedule_with_warmup と呼ばれる事前定義済みスケジューラ(Pytorch側で持ってる)を使用していて、Warmupステップの間は線形的に指定された学習率まで上昇し、その後は最大ステップ数で0になるようにこれまた線形で学習率を減少させていくという単純なものを採用しています。
ところが今回画像生成となると扱う情報がより複雑になり、パラメータの組み方も数こそWhisperより少ない(およそ800Mぐらい)ですが、パラメータ変化のさせ方にはより慎重な手法が求められるということで、そのアルゴリズム自体も微分方程式と呼ばれる勾配問題を解く手法を応用した様々なものが登場しています。
ちなみにサンプラーを変更したから全く違う絵が生成されるか?というとそうではありません。どんなサンプラーを使おうとも、基本的にはランダムシードの値が同一である限り出力される絵は最終的に同じものになっていきます。違いはその収束速度です。最終的に求められる絵になるまでに必要なステップ数が違っており、その導出過程で生成される絵の違いもあり、何かしらの変化が得られるものと考えるケースもあろうかと思いますが、大体1000stepsぐらいやらせるとほぼ同じ絵が出てくるようです。
ただ、Ancestral方式(伝承サンプリング方式)というものを組み合わせたものについては、ニューラルネットワーク上のノードの進み方を高速条件に定めている影響で、サンプリングの収束速度は上昇するのですが、stepsを極端に進めた最終的な絵の構図は変わってしまうという傾向があります。
なぜ収束速度にこだわるのか?それは、生成画像をリアルタイム動画に適用することを究極的に求めているからのようです。現状、Diffusion-Modelというのは弱点として収束に時間がかかることが最大の短所として挙げられています。これをGAN(敵対学習を用いたNN)に匹敵させることで、リアルタイム的に多くの画像を生成させることでこの短所を克服する、それを左右するのが所謂サンプラーなのです。
今のところ、隠れ空間にDiffusion-Modelを適用するLatent-Diffusion-Modelが確立したことによりその計算回数は半減したと言われています。このことでノイズ除去過程における計算回数自体は極限まで削れたと判断しており、今だ未開拓の値はSamplerであると考えたのでしょう。
こうした技術について、SONYさんが取り組んでいるようで、nnablaディープラーニングチャンネルでかなり詳細に踏み込んだところまで紹介をなさっています。
興味のある方はご覧いただくとよいのではないかな?と思います。それでは。
参考文献
CompVis – Machine Vision and Learning LMU Munich Repositry
https://github.com/CompVis/
Denoising Diffusion Probablistic Models
https://arxiv.org/abs/2006.11239
High-Resolution Image Synthesis with Latent Diffusion Models
https://arxiv.org/pdf/2112.10752.pdf
拡散確率モデルと音声波形生成
https://speakerdeck.com/yumakoizumi/kuo-san-que-lu-moderutoyin-sheng-bo-xing-sheng-cheng
HuggingFace, CompVis
https://huggingface.co/CompVis
LMU-Machine Vision -Learning Group
https://ommer-lab.com/
DeepFaceLab
https://github.com/iperov/DeepFaceLab