Azure OpenAI Serviceに触れてみる – ポンコツダ・ヴィンチ チャットボットの制作
2023年03月13日 月曜日

CONTENTS
Azure にもOpenAIサービスがやってきた!
こんにちわ。九州支社のとみ(とみーとも言う)です。
最近ChatGPTのAPIがついにリリースされまして、もちろん私もドハマりしています。やっぱり触れてみれば見るほどモデルに対する理解が進んできてますが、それと同時に「プロンプトエンジニアリング」という言葉が生まれてきた点についてなんだか複雑な気持ちを抱いていたりします。
本当は、ChatGPT APIに関する話をしたいなとも思ったんですが、こいつが思った以上の底なし沼でして・・もう少し勉強してからじゃないと記事書き起こせないなと思っており、今回はMicrosoft Azure Cognitive Serviceの一部として登場した Azure OpenAI Serviceについて、こないだついにサービス使用承認が下りましたので使うことにしました。
Azure OpenAI Serviceを使うには
Azure OpenAI Serviceで使用できる学習モデルとしては、NLPモデルであるGPT-3と、画像生成モデルであるDALL-E2の大きく分けると2種類です。
私はこの中でGPT-3のみを使用可能とするよう申請を行いました。

Azure OpenAI Serviceの申請
上記のように、 https://aka.ms/oaiapply へアクセスし、必要事項を記入して提出する必要があります。実はOpenAIはGPT-2の頃から「もしかしてこいつ、世に解き放ったらやばいんじゃね?」と心配するようになり、その後GPT-3からオープンソース化していません。このサービスを使用するにしても、その利用に対して慎重さを求めるようになっており、特に今回はMicrosoft社も関わっていることからより厳しく利用者を審査する方向になったのだろうと思います。
今回私が求めていたモデルはtext-davinci-003というGPT-3の中でも最新モデルであり、これが使用可能になっていたのでとりあえず目的は達成したのでした。
text-davinci-003について
実は、GPT-3の中でもtext-davinci-003は特殊なモデルで、本来の名称としてはInstructGPTと呼ばれます。
パラメータ数はGPT-3の初期Davinciと変わらない175Bなのですが、その調整方法が大きく異なっており、そのファインチューニング手法(アライメント調整手法)にRLHF(Reinforcement Learning from Human Feedback、人間のフィードバックを反映させた強化学習)という手法を用いています。この辺りの詳細はITmediaさんの記事がありますので、これを参考にするとよいと思います。
要は、人間のリアルな評価基準を強化学習のモデルに取り込むというもので、そのモデルづくり自体もGPT-3の6B規模で作られたそうです。強化学習用報酬モデルは、通常のGPT-3とは異なり、出力結果としてスコアを複数観点から算出することになっており、この結果に基づきInstructGPTはさらに人間にとって都合の良い応答を返してくれるようになったようです。
で、Azure OpenAI Serviceの何がいいの?
という話になるんですけど、はい、ある程度の方々はご存じだとは思いますが、ChatGPTのAPIは2023年3月6日時点ではまだAzure OpenAI Serviceには提供されていません。しかし、このサービス、特にMicrosoft Azureの既存ユーザには結構ありがたい機能が盛り込まれていたのでそれを説明したいと思います。
とりあえず比較表作りました。
ざっくりとですが、今時点でわかったこととしては以下の通りです。

Azure OpenAI Serviceと純正OpenAI APIサービスの比較
やっぱりうれしいポイントはセキュリティ
Microsoft Azureの既ユーザにうれしいと申し上げた理由は、Azure PaaSやIaaSの環境にあわせて作られており、その連携がとりやすいことです。
まず、純正OpenAIサービスと比べてセキュリティレベルは確実に高いです。
- ファイアウォール機能(IPv4のみ)があるので、外部アクセスに対する規制が可能
- エンドポイントがリソース単位で払い出されるので、環境分離度が純正のそれと比べて高い
- VNETに対するプライベートエンドポイントやサービスエンドポイントの構成ができるため、閉域網だけでの利用が可能
- 日本語情報がMicrosoft Docsに収められており、より理解しやすい環境である
- PlayGroundの構造は純正のそれとあまり大きく変わらないため、あらかじめOpenAIサービスを使ってた人にはわかりやすい
- 規約に違反する入力をAzure側で取り締まってくれる
- Abuse Monitoring:
PromptやCompletion(要はGPT-3に対して命令を投げる内容)はAzureによって監視されているため、不正データが投げつけられたときに気づきやすい - Modified Content Filtering:
明らかに有害と判断されるコンテンツに関しては、あらかじめフィルターが仕込まれており、そのフィルタリング処理で弾かれる - これらは一定の条件を満たせばオプトアウト申請が可能
https://learn.microsoft.com/en-us/legal/cognitive-services/openai/data-privacy
- Abuse Monitoring:
よって、エンタープライズ用途にかなり傾けた形でこのサービスが実装されたことがよくわかります。
Azure OpenAI Serviceに触れてみる
承認が下りたら、ホーム画面の検索ウィンドウで「Azure OpenAI」で探せば、OpenAIのロゴが検索結果に登場しますので、まずそれをクリックして新規リソースを作成してください。これ自体はすべての土台となるリソースであり、Azure Cognitive Serivceの一角として作られます。ここで設定する名前がそのままエンドポイントFQDNのホストパートになりますのでそこだけ気を付けてください。
リージョンは私は米国東部を選択しました。まだこのサービスは全世界展開は出来てないので、米国のどこかのリージョンを使うのがよいかと思います。
その後、OpenAIのモデルを「デプロイ」する必要があります。これを行うことで、AIとしての処理が行えるようになります。こちらは以下の通り図示します。
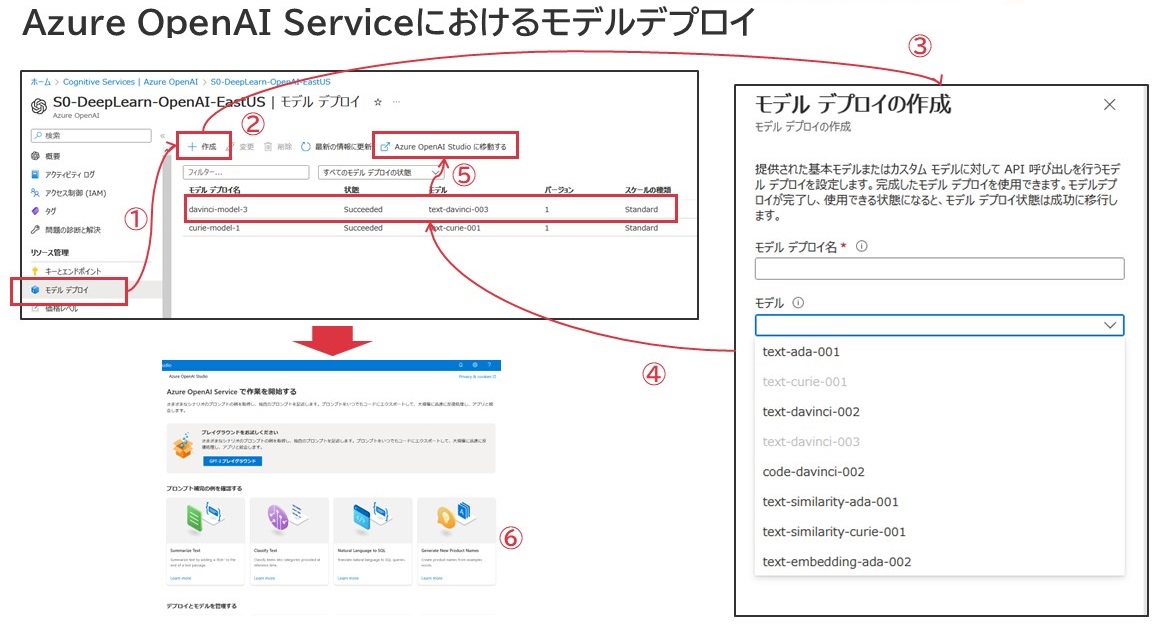
モデルデプロイの過程
順序として、上図番号に対応付ける形で以下補足します。
- 画面左側ペインから「モデルデプロイ」をクリック
- 「+作成」をクリック
- モデル名称の設定とモデルの選択を行う。
この時、各モデルは1度しかデプロイできないように設定されています。すでにデプロイ済みのモデルは灰色文字になっていますが、これはすでにモデルがデプロイされ、使用されているためです。 - モデルのデプロイは数秒程度で完了します。
- 使用するモデルの行を一度クリックしたうえで「Azure OpenAI Studioに移動する」をクリックすると、Azure OpenAI Studioへ移動します。
Azure OpenAI Studioで、プレイグラウンドを使用する
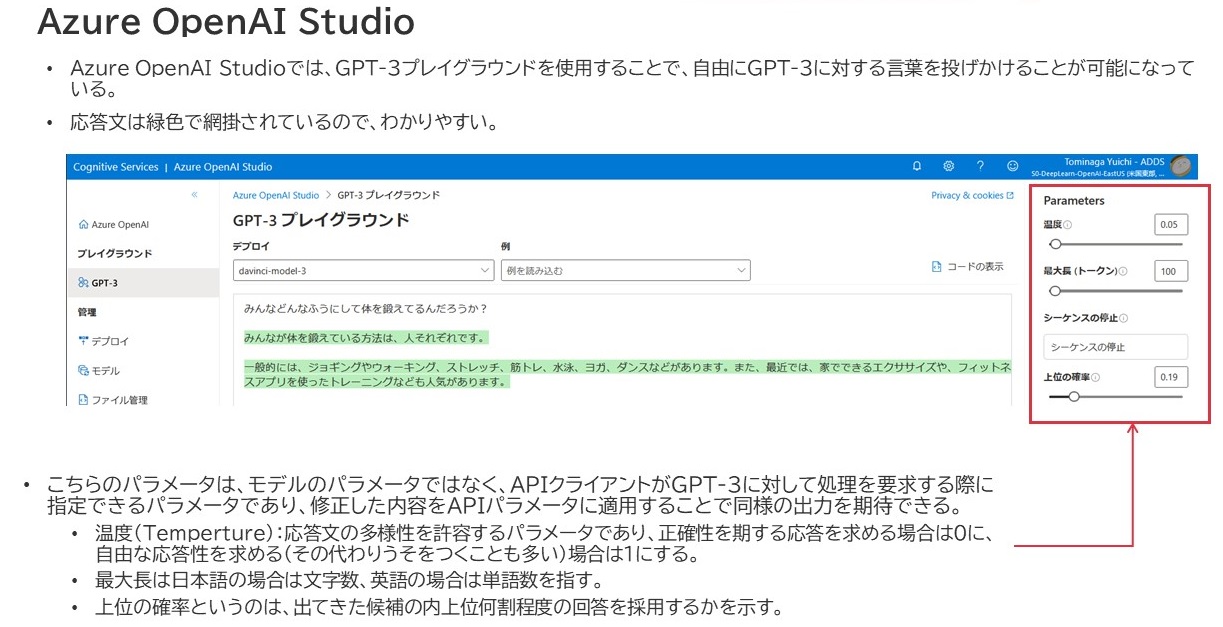
Azure OpenAI Studio Playgroundの画面
プレイグラウンドでは、巨大なテキストフィールドがドーンとあるだけで、ユーザもGPT-3もともに同じフィールドに何かを書く仕様になっています。ユーザがこのフィールド内に何かを入力して「生成」をクリックすると、画面右側Parametersの設定に応じてGPT-3が緑色で網掛けされた形式で応答文を出力してくれます。ちゃんと日本語で入力しても text-davinci-003 は理解してくれました。
なお、このツールの中でモデルのチューニングも可能です。このサービスの用語として「微調整」という用語があるのですが、この「微調整」はそのまま「ファインチューニング」を指しています。そのためのデータセットのアップロード機能も有している・・・のですが、ファインチューニングを実行したモデルはパラメータの値が変わってしまうことから、専用のGPU基盤で稼働することになり、それに応じて関連ホスト稼働に課金が発生してしまいます。要は
「モデルをいじらなければ安いけど、モデルをいじると高くつく」
という素敵な特性を持ってますので、モデルの取り扱いには十分注意してください(Microsoftの担当者も「ファインチューニングは最終手段としてとるもの」とおっしゃってました。)。基本的に、Promptに何か放り込んで応答をもらうといった単純なことについては、OpenAI側の課金体系と全く同じですので、ほとんどお金はかからないと言っていいでしょう。(現状我々だと20円/dayぐらいの使用量です)
Azure OpenAI ServiceをAPI経由で利用する
Azure OpenAI ServiceをAPI経由で使用することを考えてみます。私はPythonで構築しているのですが、実は使用するライブラリはOpenAIの純正ライブラリです。ただし、微妙に使い方が違います。
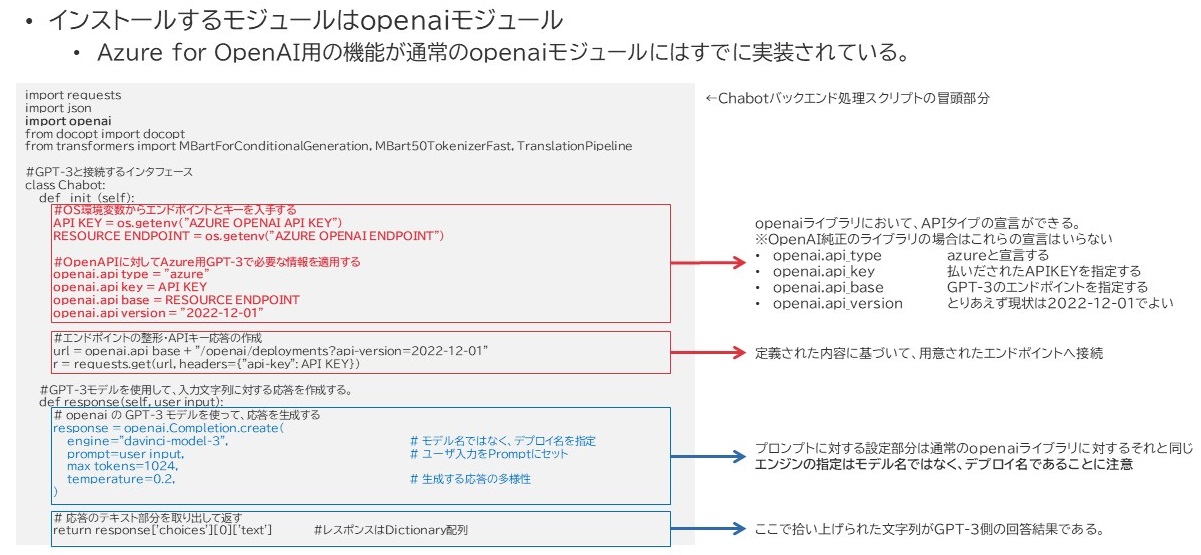
Azure OpenAI Serviceに対するAPI連携
違う点というと、上図赤枠でくくったところが該当します。
- Azure OpenAI Serviceの独自パラメータ設定が必要
- アクセス先であるURLとそのリクエスト作成の処理が必要
純正のAPIのデフォルト設定は、原則OpenAIサービスの決まりに従い、api.openai.com へアクセスするようになっていますので、この辺りを修正する必要があるのです。それ以外は、モデル名として「本来のモデル名ではなく、デプロイされたモデル名を指定する必要がある」という点に気を付ければ大体大丈夫じゃないかなと思います。

OpenAIライブラリによってやり取りされるAPIデータ
APIがやり取りするデータは、リクエスト時もレスポンス時もJSONです。構造は上図のようになっています。
ポンコツダ・ヴィンチの制作
さてそれでは、これを活用したポンコツダ・ヴィンチを作ってみようと思います。なぜポンコツかというと、私がPromptの有効な扱い方が理解できておらず、素のtext-davinci-003に対して普通に会話を投げるだけのチャットボットだからです。もう少しPromptの中身を充実させると会話につながりを持たせたり、キャラづくりが出来たりするんですが、ChatGPT-APIを試した結果その気が現在猛烈に萎えたので、とりあえずはこれでいいか・・・ということになりました。
クライアントソフトの選定
割と多くの人がSlackの連携とかSNS系インタフェースの連携を多く書いてるんですが、私の場合このポンコツダ・ヴィンチくんには社内で働いてほしかったこともあり、あえて検証サーバページにそびえたつWebチャットとして作成をしました。そこで採用したのがChatux( https://github.com/riversun/chatux )というJavascriptを使用したチャットクライアントソフトです。
このソフトはGitHub.io経由でスクリプトをダウンロード実装できることもあり、設置が楽だと判断しました。
ChatuxにおけるHTTPプロトコルでやり取りするデータの使用は下図のようになっています。
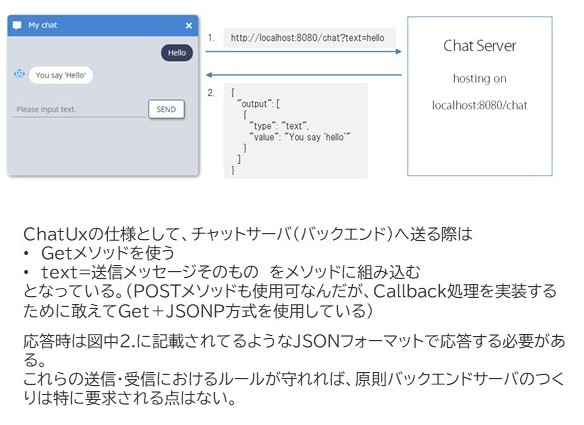
ChatuxにおけるGet+JSONP形式でのデータのやり取り
既存ページへのクライアント実装
既存ページに対して、数赤枠の個所を追加することになります。
1行目がリポジトリからのJavascriptでWebpack化されたスクリプトの入手、2行目以降がその設定内容になります。
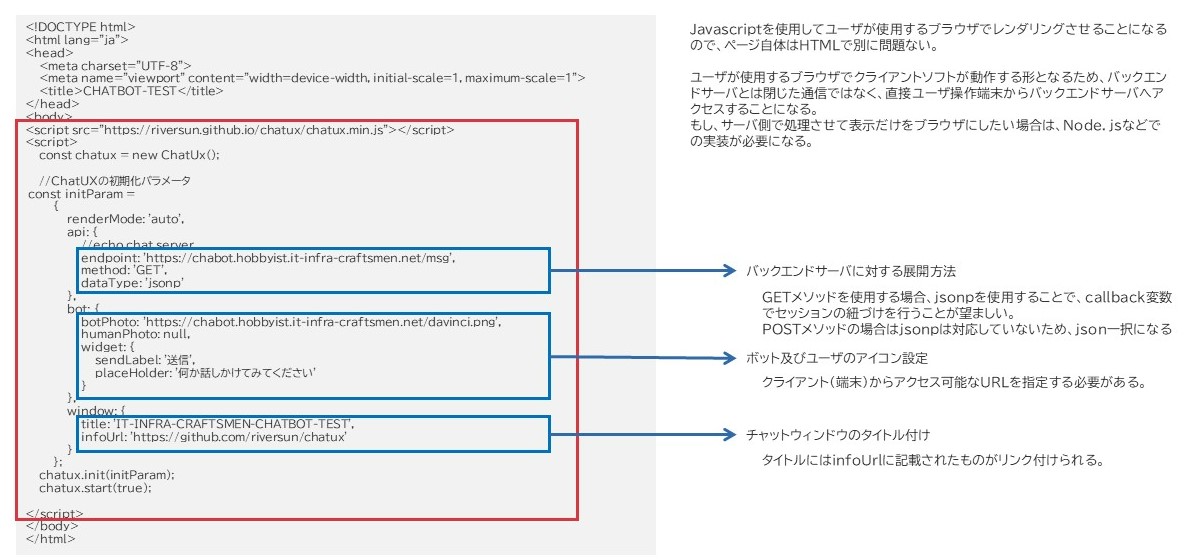
上図にも記載してるんですけど、基本的にはJavascriptベースなのでクライアント側でレンダリングして使う形態となります。よって、設定部分はユーザ環境からチャットサーバへどうアクセスするか?という点に気を付けて定義する必要があります。
ちなみにchabot.hobbyist.it-infra-craftsmen.net というのがポンコツダ・ヴィンチのチャットサーバですが、社内からしかアクセスできないようガッツリパケット規制はかけております。はい。
ポンコツダ・ヴィンチのアーキテクチャ
今回、ちょっと変わったことをやってみました。
ご存じの方も多いかもしれませんが、英語でこのGPT-3を使用した場合、そのトークンの長さは1トークン1単語として計上されます。しかし、日本語の場合はこれに対して不利な面があり、1トークン1文字として計上されます。つまりは、課金額的に日本語のまま取り扱うと高くつくということですね。
そこで、ちょっと悪あがきをして以下の様なアーキテクチャを組みました。結果としてはそんなに課金額に差は出ず、むしろ内部処理で使用するGPUコストの方が圧倒的に高かったんですけどドドド。
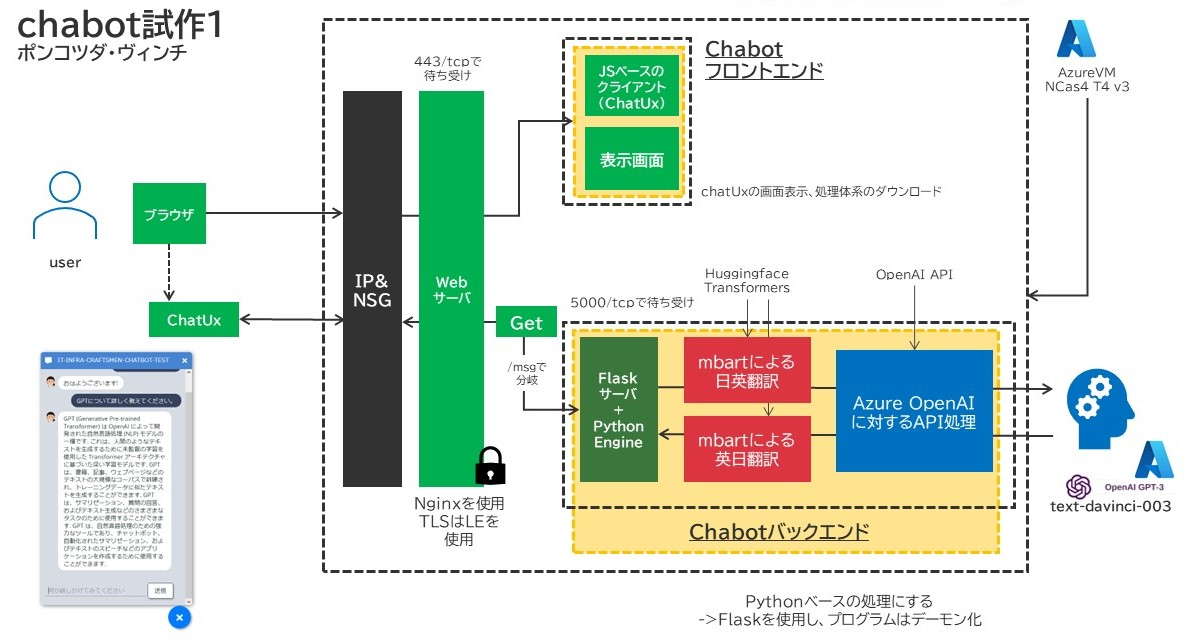
ポンコツダ・ヴィンチのアーキテクチャ
Huggingfaceの記事でも紹介した、mBARTを使用した日英・英日翻訳を行わせました。英語変換してGPT-3に突っ込んだらきっとそのあたりのコストは下がる!と信じて。そうして作成したスクリプトがこちら。(スクリプトは初版です。その後結構色々書き換えまくっています)
#
# 簡易チャットボットプログラム Author:y-tominaga@iij.ad.jp
# Web-バックエンド-GPT3版
# 2023/02/28 v0.2
#
import os
import requests
import json
import openai
from docopt import docopt
from flask import Flask,request,jsonify
from transformers import MBartForConditionalGeneration, MBart50TokenizerFast, TranslationPipeline
#GPT-3と接続するインタフェース
class Chabot:
def __init__(self):
#OS環境変数からエンドポイントとキーを入手する
#別途OS環境側でエンドポイントとキーは指定済み。
API_KEY = os.getenv("AZURE_OPENAI_API_KEY")
RESOURCE_ENDPOINT = os.getenv("AZURE_OPENAI_ENDPOINT")
#OpenAPIに対してAzure用GPT-3で必要な情報を適用する
openai.api_type = "azure"
openai.api_key = API_KEY
openai.api_base = RESOURCE_ENDPOINT
openai.api_version = "2022-12-01"
#エンドポイントの整形・APIキー応答の作成
url = openai.api_base + "/openai/deployments?api-version=2022-12-01"
r = requests.get(url, headers={"api-key": API_KEY})
#GPT-3モデルを使用して、入力文字列に対する応答を作成する。
def response(self, user_input):
# openai の GPT-3 モデルを使って、応答を生成する
response = openai.Completion.create(
engine="<Deploy Name>", # モデル名ではなく、デプロイ名を指定
prompt=user_input, # ユーザ入力をPromptにセット
max_tokens=1024,
temperature=0.2, # 生成する応答の多様性
)
# 応答のテキスト部分を取り出して返す
return response['choices'][0]['text'] #レスポンスはDictionary配列
#mBARTによる日英翻訳
class ja_to_en_Translate:
def __init__(self):
#モデルの指定
self.trans_model_ja_en='facebook/mbart-large-50-many-to-one-mmt'
#モデル・トークナイザの作成
self.model_ja_en=MBartForConditionalGeneration.from_pretrained(self.trans_model_ja_en)
self.tokenizer_ja_en=MBart50TokenizerFast.from_pretrained(self.trans_model_ja_en)
self.tokenizer_ja_en.src_lang="ja_XX"
self.tokenizer_ja_en.tgt_lang="en_XX"
#パイプラインの作成
self.trans_ja_en=TranslationPipeline(model=self.model_ja_en,tokenizer=self.tokenizer_ja_en,src_lang="ja_XX",tgt_lang="en_XX",device=0,batch_size=16)
def response(self, input_word):
response_data = self.trans_ja_en(input_word,max_length=512,truncation=True)
return response_data[0]["translation_text"]
#mBARTによる英日翻訳
class en_to_ja_Translate:
def __init__(self):
#モデルの指定
self.trans_model_en_ja='facebook/mbart-large-50-one-to-many-mmt'
#モデル・トークナイザの作成
self.model_en_ja=MBartForConditionalGeneration.from_pretrained(self.trans_model_en_ja)
self.tokenizer_en_ja=MBart50TokenizerFast.from_pretrained(self.trans_model_en_ja)
self.tokenizer_en_ja.src_lang="en_XX"
self.tokenizer_en_ja.tgt_lang="ja_XX"
#パイプラインの作成
self.trans_en_ja=TranslationPipeline(model=self.model_en_ja,tokenizer=self.tokenizer_en_ja,src_lang="en_XX",tgt_lang="ja_XX",device=0,batch_size=16)
def response(self, input_word):
response_data = self.trans_en_ja(input_word,max_length=512,truncation=True)
return response_data[0]["translation_text"]
#メインルーチン
app = Flask(__name__)
app.config["JSON_AS_ASCII"] = False
#GPT-3接続用インタフェースの作成
chatai = Chabot()
# 翻訳機インスタンスを作成する
tr_ja_en = ja_to_en_Translate()
tr_en_ja = en_to_ja_Translate()
#URLおよびメソッドの指定
@app.route("/msg", methods=["GET"])
# ユーザーからの入力を受け取る
def request_and_response():
input_jpn_msg = request.args.get('text','')
callback = request.args.get('callback','')
# mBARTは文章を完結しないと暴走するため、抑止のために末尾に句点を打つ
input_jpn_msg = input_jpn_msg + '。'
# 日英翻訳を行い、翻訳された文字列を出力する
input_eng_msg = str(tr_ja_en.response(input_jpn_msg))
# chataiからの応答を取得する
res_eng_raw = str(chatai.response(input_eng_msg))
res_eng_msg = res_eng_raw.replace('\n\n','')
# 受け取った英語応答文を日本語に翻訳する
res_jpn_msg = str(tr_en_ja.response(res_eng_msg))
# JSON応答を作成する
response = {'output' : [{'type' : 'text', 'value' : res_jpn_msg }] }
contents = callback + '(' + json.dumps(response) + ')'
return contents
このファイルを作ったところから、以下のようにコマンドを設定すると、サーバプロセスが起動します。
export FLASK_APP=/home/<user_name>/<Directory>/chabot_backend.py export FLASK_DEBUG=true flask run --host=0.0.0.0 --port=5000
この状態でクライアントページにアクセスすれば、チャットボットが応答を返してくれるようになります。
やってみた
で、現在このポンコツダ・ヴィンチは社内に設置している当課の検証サーバページのトップの顔になってもらっています。時々ちょっとした質問をしたい人とかがつついてたりすることがあるようです。
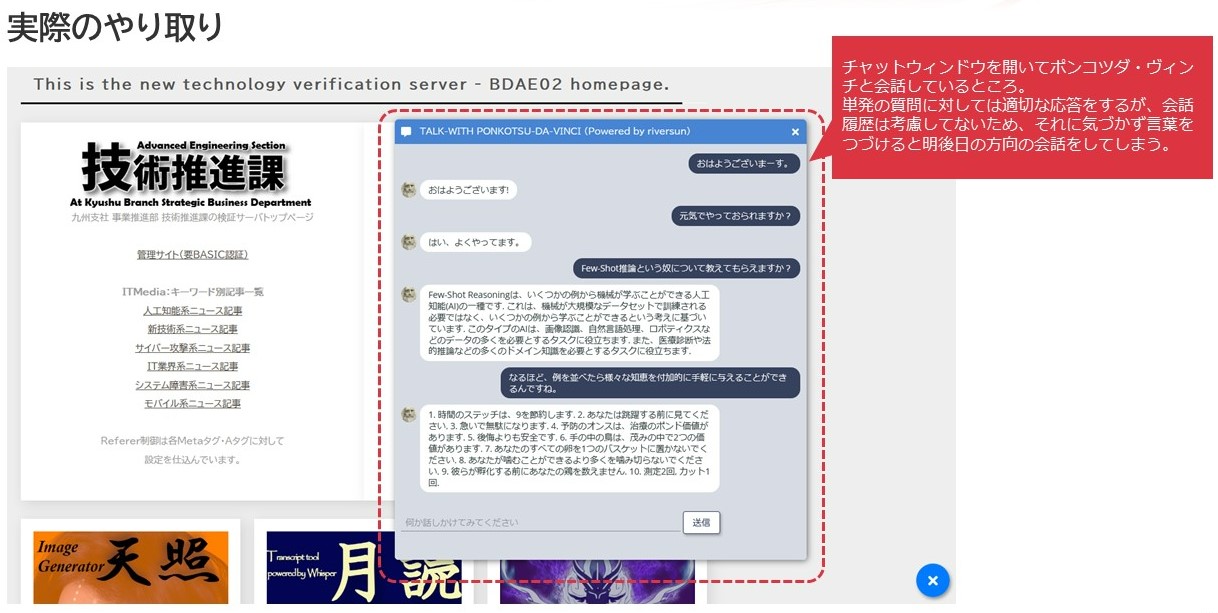
ポンコツダ・ヴィンチとの会話
やった!無事応答が返ってきた!と最初は狂喜乱舞したんですが、あと後よく見ると文脈が受け継がれてないことや、場合によってはニュアンスが崩れた故に意図する内容とは違う答えが返ってきたりと徐々に顔はスンとしていきましたが、APIを使ったやり取りについて一定の理解を得ることができたのかなと思います。
かかるコストについて
なお、text-davinci-003モデルですが、1,000トークン(日本語の場合1,000文字に相当、英語の場合は1,000単語相当)でおよそ2.5円かかります。(OpenAIが配布するChatGPTはこの1/10の0.25円)
それでもコストとしてはこんなもんでした。半分以上が予測値なので、何とも言えないところはありますが、開発に際しかなりAPIに文字を投げまくり応答を受け取りまくったので、それなりにコストはかかってるはずです。
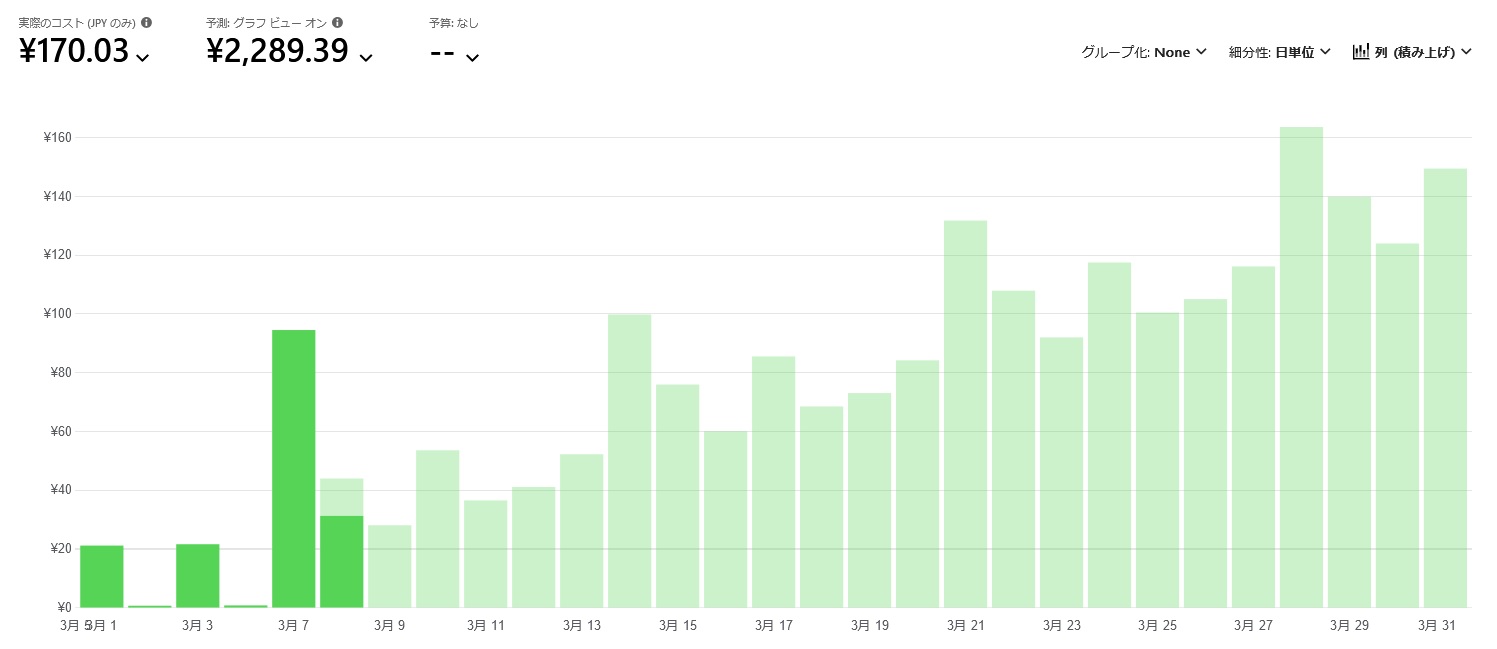
2023/3/9時点のコスト
とりあえずは、ベースモデルにContextで情報補填しながらやり取りする分には、そこまでコストはかからないようです。
ちなみにもちろんChatGPT(gpt-3.5-turbo)に対してもやったよ。
もちろんこれをChatGPT相手にも行いました。ただし、こちらについては個人で取り組んだので(理由は単純で、トークン単位の単価がメッサ安いから)実装自体は個人環境でやってますが、まぁコードもそれなりの修正を要しました。それにしても度肝を抜かれました。ちなみにお皿くんはこのブログでも使ってるアイコンのキャラ名で、オリジナルなやつです。

gpt-3.5-turboとのやりとり
ノーチューニングの text-davinci-003 とはレベルの違いを感じる応答内容です。とはいえ実はやっぱりこの辺りの扱いはGPTに対して渡すPromptの内容次第のようです。このPromptの取り扱いに関して、gpt-3.5-turboで使われているChatCompletionという関数は非常にやりやすく作られており、より直感的にそのPromptの渡し方を工夫出来てるようになっているようです。
さて、こんな記事を書いてるさなかに実はAzure OpenAI ServiceにもChatGPTモデルがPublicPreviewではありますが、提供が開始されました。本当に何事も動きが速すぎてブログ記事の投稿タイミングすごく悩みますね。これについては、次回の記事で合わせて説明したいと思います。
先行調査ならOpenAI純正、エンタープライズ用途ならAzure OpenAI Service
いくらMSが独占契約を結んでるとは言え、自社のモデルを自社より先に渡すってのも難しいのでしょうから、やっぱり最新モデルを追いかけるならOpenAIの方がいいでしょう。実際新しいOpenAIライブラリはChatCompletionの実装により、さらにこれに取り組む人が増加するんだろうなーと思います。
Azure OpenAI Serviceは、探索したうえで選定したモデルの中でも安定版というか、より使われてるものが蓄積されており、その環境分離の度合いもOpenAIよりしっかりしていることで、特にセキュリティを意識したつくりになっているなと感じました。高くつく部分はあるにしても、アーキテクチャをしっかり組むことによって、ある程度のコスト圧縮は可能かもしれませんし、OpenAIと同じようにPlayGroundがあるのはやっぱりありがたいです。何しろクライアントパラメータの変化に対する影響評価がその場でぱっとできるんですから。
こうしたところをうまく使い分けることで、OpenAIサービスをより有効活用できるようになるのではないか?と思います。
ところで
ChatGPTとかなんでローカル環境に設置できないの?なんでうちのものにできないの?とか思う人結構いるんじゃないかと思います。
実はNLPモデルのファインチューニングって、私がそれまでに取り扱ってた特定用途向けのAIモデルと比べて扱いが非常に難しいんです。
https://lifearchitect.ai/chatgpt/ というサイトにとっても面白いQAが載ってましたので、これを翻訳したものを転載します。
なお、このサイトの記事を書いている Alan D. Thompson氏はなかなか強烈なAIコンサルタントさんで、
- Mensa International 元会長
- 人工知能と人間の知能の分野で企業・政府・国際メディアにアドバイスを提供
結構な経歴をお持ちの方のようです。著書もいくつかリリースされてるようで・・
 赤文字で書いたところを見ていただけるとわかるかと思うのですが、GPTやそれに類するモデルへの学習、つまりはファインチューニングって数日のレベルではできないんです。数か月、十数か月ぐらいを要するケースがほとんどで、ChatGPTの学習情報が古い理由はここにあります。最新情報を組み込もうにもそれが使い物になるのが1年近くあるいはそれ以上先になってしまうのです。
赤文字で書いたところを見ていただけるとわかるかと思うのですが、GPTやそれに類するモデルへの学習、つまりはファインチューニングって数日のレベルではできないんです。数か月、十数か月ぐらいを要するケースがほとんどで、ChatGPTの学習情報が古い理由はここにあります。最新情報を組み込もうにもそれが使い物になるのが1年近くあるいはそれ以上先になってしまうのです。
それゆえに、それに追従できる、あるいは別のアプローチで知識を後付けできるようなことが求められ、よりそこを考慮したモデルPrometheus(つまりはMicrosoft社のBingSearch的なもの)が誕生したのかもしれません。
参考情報
逆瀬川さんのQiita記事: https://qiita.com/sakasegawa/items/db2cff79bd14faf2c8e0
TwitterでAI関連の発言を多くなさってる逆瀬川さん( https://twitter.com/gyakuse )の記事を応用させていただきました。逆瀬川さん、ありがとうございます!