素人がトピックモデルを試してみた (第3回)
2019年01月28日 月曜日

CONTENTS
前回は LDA によって求めたトピック分布をもとに、「最も高い確率を示したトピック番号にその文書を所属させる」という極めて単純な方法での記事のグループ分けの結果を踏まえて、より良い結果を得るための工夫について考えました。 今回はそれらのアイデアをいくつか試して、実際に結果が良くなるかを見ていきたいと思います。
結果を評価する
前回までは分類結果をつぶさに読んで精査していましたが、この方法はとても時間がかかるため、パラメーターを変えながら試行を繰り返すことは困難です。 そこで、この手間を軽減する方策を考えます。 その前に、まず何をもって「よい結果」とするかの判断基準を決めるために、目指す使い途をより具体的に想定することにしましょう。
ユーザに文書の一覧を提示するシステムを考えます。 第1回の記事で少し触れたように、手元にある文書だけを使って、ニュースアグリケーションサイトなどで行われているように、同じ題材を扱った文書を自動的にグループとしてまとめて表示することにしましょう。
対象とする文書はどんなものでもよいわけですが、最初にこのシリーズでは IIR 英語版テキストを扱うことに決めました。 その中でも、今回は IIR Vol.3~Vol.12に掲載したフォーカスリサーチ(1.4.1節 ~ 1.4.4節)の記事を対象にします。 毎回様々な題材を解説していて、必ず一定量の文章が含まれていることを鑑みてこれらを選択しました。
まずは対象となる記事をざっと読み返して、自信を持って同じ題材だと言える下記のようなグループを作成しました。
- グループ#0 (共通の題材: クラウドのセキュリティ)
- Vol.4 1.4.3節: Cloud Computing and Security
- Vol.9 1.4.2節: Shared System Security
- グループ#1 (共通の題材: Gumblar とその亜種)
- Vol.4 1.4.2節: ID/Password Stealing Gumblar Malware
- Vol.6 1.4.1節: Renewed Gumblar Activity
- Vol.7 1.4.1節: ru:8080, Another Attack with a Gumblar-type Scheme
- グループ#2 (共通の題材: 暗号)
- Vol.6 1.4.2節: MITM Attacks Using a Vulnerability in the SSL and TLS Renegotiation
- Vol.8 1.4.1節: Trends in the Year 2010 Issues on Cryptographic Algorithms
- グループ#3 (共通の題材: 影響が国レベルに及ぶほどの攻撃)
- Vol.5 1.4.1節: DDoS Attacks in the United States and South Korea
- Vol.7 1.4.2節: Targeted Attacks and Operation Aurora
- グループ#4 (共通の題材: Hacktivism)
- Vol.10 1.4.1節: An Overview of the Large-Scale DDoS Attacks in September 2010
- Vol.12 1.4.1節: Continuing Attacks on Companies and Government-Related Organizations
- グループ#5 (共通の題材: 観測システムの解説)
- Vol.6 1.4.3節: Techniques for Surveying P2P File Sharing Networks
- Vol.7 1.4.3節: MITF Anti-Malware Activities
- Vol.8 1.4.2節: Observations on Backscatter Caused by DDoS Attacks
- グループ#6 (共通の題材: コンピュータ・フォレンジックス)
- Vol.9 1.4.3節: An Overview of Digital Forensics
- Vol.11 1.4.2節: Malware Anti-Forensics
どの程度のものを「同じ題材である」とみるかは目的によっても人によっても違ってくるはずですが、今回はこのグループ分けを「正解」とし、これに近いグループ分けができた結果を「よい結果」と考えることにします。 こうすれば、あとはグループ分けどうしの近さをどう評価するかという問題になります。
なお、ここまではグループ分けと言ってきましたが、機械学習の用語ではクラスタリングと呼ばれていますので、以降はそれにならうことにします。
クラスタリング結果の評価手法について
機械学習の分野ではクラスタリング結果を比較するための評価指標が多数提案されていて、Python の機械学習ライブラリのひとつ scikit-learn(※1)に実装されている指標に限ってもたくさんあります(※2)。 その中から自分たちの目的に合うものを選び出します。
今回は正解データとの近さを測る指標がほしいので、まずはそれに当てはまらない指標(Silhouette coefficient, Calinski-Harabaz index, Davies-Bouldin index)を外します。 2次元の表形式である “Contigency matrix” は、表どうしを見比べて優劣を決めることが非常に難しいので使いません。 また、クラスタ数に依存した値が出てしまう指標(Homogeneity, Completeness, V-measure, Fowlkes-Mallows score, NMI)は、アルゴリズムの出力結果を比べるときにクラスタ数が異なっていると単純に指標値の大小で良し悪しを評価することができないのが難点です。
ここまでで AMI, ARI の 2つに絞られました。 比較的最近の学術研究に、この両者の理論的関係を明らかにして、どの場面でどちらを使うべきかを示した論文がありました(※3)。
これによれば、
- 正解データのクラスタがどれも同程度のサイズで、それぞれ大きいという場合には ARI を選ぶ
- サイズが不均等で、小さいクラスタを含む場合には AMI を選ぶ
とあります。 今回の正解データは各クラスタが非常に小さいので、AMI を使って評価することにします。
クラスタリング手法について
さて、クラスタリングの手法も前回より高度なものを使ってみましょう。 前回は、LDAで計算したトピック分布で最も高い確率を示したトピックに文書を所属させるという、ごく単純な方法を使いました。
クラスタリングのためのアルゴリズムもまた、さまざまなものが研究、提案されています。 よく名前を見かける k-平均法(k-means 法)はその代表格と言えるでしょう。 scikit-learn ライブラリに実装されているアルゴリズムのうち、なるべく自分の目的にそった性質を持つと考えられるものを選びます。
今回考えている用途では、他の記事にない題材を扱った記事を無理にどこかのクラスタに所属させる必要はなく、むしろ単独の記事として表示して欲しいと感じます。 ですので、各記事を必ずどこかのクラスタに所属させる k-平均法などのアルゴリズムは使わず、DBSCAN というアルゴリズムを使うことにします。 DBSCAN であれば、他に類似の無い記事はどのクラスタにも属さないという分け方が可能です。
実践
前述したとおり、分析や評価の対象にするのはフォーカスリサーチのみですが、モデル作成時にはバリエーションを増やすためにより多くの文書を使用したいところです。 これもこのシリーズで前提とした「手元にある情報を使う」という条件を考慮して、今回は IIR Vol.3~Vol.35 の第1章すべてを使用することにしました。
では、実際にパラメータを変化させながら LDA でモデルを作成して、それぞれのモデルを使って文書のクラスタリングを繰り返して、結果を評価していきましょう。
これまでの実験で、トピック数は多すぎても少なすぎてもうまくないことがわかっています。 そこで、トピック数を変更しながらモデルを複数作成してみます。 以前の記事で、トピック数が数十程度の時にいい結果が出ることがわかっているので、今回は5から100の範囲でトピック数を変化させることにしました。
# トピック数を 5 - 100 で変化させて書き出す
for ntopics in range(5, 101, 5):
lda = gensim.models.ldamodel.LdaModel(bow, id2word=dic, num_topics=ntopics)
modeldir = Path('./Models') / ('topic-%03d' % ntopics)
lda.save(str(modeldir / MODEL_FILE))
このようにして作成したそれぞれのモデルについて、DBSCAN でクラスタリングを試みます。 DBSCAN のドキュメントによると、クラスタの大きさに影響する eps というパラメータがあります。 これを0~1の間で変化させながら評価する文書群を読み込んでクラスタを作成、それぞれの eps 値でのクラスタリング結果と今回正解とするクラスタを AMI を用いて比較します。
# 正解とするクラスタのリストと、AMI スコア計算用のリストを作成する
#
# labels_true: array
# labels_true[i] はその文書が所属するクラスタのインデックス
# クラスタに所属していない文書のラベルには -1 を入れる
names = [ 'IIR03-1.4.1', 'IIR03-1.4.2', ... ]
groundtruth = [
['IIR04-1.4.3', 'IIR09-1.4.2'],
['IIR04-1.4.2', 'IIR06-1.4.1', 'IIR07-1.4.1'],
['IIR06-1.4.2', 'IIR08-1.4.1'],
['IIR05-1.4.1', 'IIR07-1.4.2'],
['IIR10-1.4.1', 'IIR12-1.4.1'],
['IIR06-1.4.3', 'IIR07-1.4.3', 'IIR08-1.4.2'],
['IIR09-1.4.3', 'IIR11-1.4.2'],
]
labels_true = [-1] * len(names)
for i in range(len(groundtruth)):
for name in groundtruth[i]:
labels_true[names.index(name)] = i
# DBSCAN: eps を変化させて、クラスタの数を確認する
# vec_list には LDA での分析結果が入っています
nclusters = []
labels_dbscan_list = []
xp = np.array([ round(0.001 + 0.001*i, 3) for i in range(1000) ])
for x in xp:
dbscan = DBSCAN(eps=x, min_samples=2).fit_predict(vec_list)
labels_dbscan_list.append(dbscan)
nc = dbscan.max()
nclusters.append(nc)
# Adjusted Mutual Information (AMI) スコア計算
ami_values = []
for labels_dbscan in labels_dbscan_list:
ami_values.append(metrics.adjusted_mutual_info_score(labels_dbscan, labels_true, average_method='arithmetic'))
このように、アルゴリズムの呼び出し時に与えるパラメータなどについて、単純な全数探索の要領でプログラム上で値を変えながら繰り返し計算させて、評価値の最も良い値の組み合わせを探す手法をグリッドサーチ(grid search)といいます。
ここまで書いた条件でトピック数と eps の値を変化させるグリッドサーチを行った結果、モデル作成時のトピック数とそれぞれの AMI (最大値)は次のようになりました。
| トピック数 | AMI | コメント |
|---|---|---|
| 5 | 0.107654 | |
| 10 | 0.254468 | |
| 15 | 0.105890 | |
| 20 | 0.262183 | |
| 25 | 0.176706 | |
| 30 | 0.288106 | |
| 35 | 0.173549 | |
| 40 | 0.268112 | |
| 45 | 0.268570 | |
| 50 | 0.258537 | |
| 55 | 0.070780 | |
| 60 | 0.221025 | |
| 65 | 0.307148 | |
| 70 | 0.333033 | 最大 |
| 75 | 0.320074 | |
| 80 | 0.183506 | |
| 85 | 0.174745 | |
| 90 | 0.133450 | |
| 95 | 0.282134 | |
| 100 | 0.033126 | 最小 |
AMI の値はどうなったのか?
それでは、AMI の値が最大になった(うまくいった)結果を見てみましょう。
今回はトピック数70で作成したモデルで AMI の値が最大になりました。 このモデルで対象の文書を解析して DBSCAN アルゴリズムでクラスタリングした時の、eps とクラスタ数の関係は次のようなグラフになりました。 横軸が eps の値、縦軸が生成されたクラスタの数です。 eps の値によってクラスタ数が変化していて、生成されるクラスタの様相が変わっていることが見てとれます。
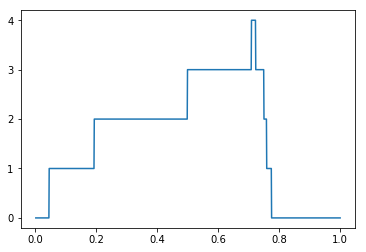
同様に、横軸に eps の値、縦軸に AMI 値をとるグラフを描画してみると次のようになりました。 クラスタの数に変化がなくても AMI 値が変化している箇所が見られますが、クラスタに含まれる文書群が変わったのだと考えられます。

AMI が最大になっているのは eps = 0.341 の時で、その時に生成されているクラスタは下記のとおりです。
| クラスタ番号 | 含まれる文書 |
|---|---|
| クラスタ #0 | IIR04-1.4.2, IIR06-1.4.1, IIR07-1.4.1, IIR10-1.4.2 |
| クラスタ #1 | IIR04-1.4.3, IIR09-1.4.2, IIR09-1.4.3 |
| クラスタ #2 | IIR08-1.4.2, IIR10-1.4.1 |
評価値が最小の時も同様に見てみましょう。 今回はトピック数100で作成したモデルで AMI の値が最小でした。 このモデルを使った DBSCAN によるクラスタリングは次のような様相になりました。
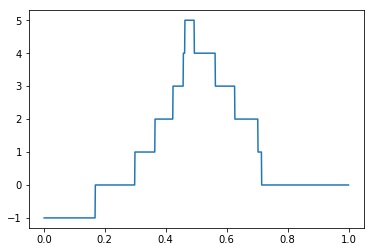
eps と AMI の変化を描画すると次のようになります。

AMI の値が全体に小さいので、目標とするクラスタが生成されていないようです。 実際に AMI 最大時のクラスタ内容を確認すると次のようになっていました。 大きなひとつのクラスタができてしまって分類されていないことがわかります。
| クラスタ番号 | 含まれる文書 |
|---|---|
| クラスタ #0 | IIR03-1.4.1, IIR04-1.4.1, IIR04-1.4.2, IIR04-1.4.3, IIR05-1.4.1, IIR05-1.4.2, IIR05-1.4.3, IIR06-1.4.1, IIR07-1.4.1, IIR07-1.4.2, IIR07-1.4.3, IIR08-1.4.1, IIR08-1.4.2, IIR08-1.4.3, IIR09-1.4.1, IIR09-1.4.3, IIR10-1.4.2, IIR10-1.4.4, IIR11-1.4.1, IIR11-1.4.2, IIR11-1.4.3, IIR12-1.4.2 |
クラスタリングはどの程度うまくいったのか?
それでは、AMI の値が最もよかった結果に戻り、クラスタの状態を正解と見比べてみましょう。
| クラスタ番号 | 含まれる文書 |
|---|---|
| クラスタ #0 | IIR04-1.4.2, IIR06-1.4.1, IIR07-1.4.1, IIR10-1.4.2 |
| クラスタ #1 | IIR04-1.4.3, IIR09-1.4.2, IIR09-1.4.3 |
| クラスタ #2 | IIR08-1.4.2, IIR10-1.4.1 |
クラスタ #0 は、所属する 4つの記事のうち 3つが正解データでもクラスタを構成しています。 また、クラスタ #1 は 3つのうち 2つが正解データのクラスタを構成しています。
一方、クラスタ #2 に所属する 2記事については、正解データではバラバラですし、改めてそれぞれの内容を見ても共通しているようには思えません。
結果として、正解として想定した7つのクラスタのうち、2つのクラスタと近いものを自動的に抽出することができました。 また、それ以外に不正解のクラスタが1つできています。
この結果をどう評価するかは意見が分かれるところでしょう。 今回想定したような「類似した記事を自動的に抽出する」というような用途を考えると、結果的に不正解のクラスタが多少増えたとしても、もう少し積極的にクラスタリングされて正解を含んだクラスタがもっとたくさん抽出できた方が都合がよいように思います。
また、この実験では、上述の正解データに含まれない記事を全て集めたクラスタと、DBSCAN で外れ値とされた記事を全て集めたクラスタの一致度も評価に加味されることになります。 想定している使い途からすれば、正解データに挙げなかった記事であっても共通点を見出してどこかのクラスタに所属させてくれても構わないわけですから、評価指標の使い方にも一考の余地がありそうです。
まとめ
今回は実際の利用シーンを想定し、それに合わせてクラスタリング手法と評価指標を選んでグリッドサーチで最適解を探すという実験をしました。 さまざまなパラメータ値や工夫を試す際にひとつひとつ結果を精査していると非常に大きな手間がかかりますが、結果の良し悪しを数値で表してくれる評価指標を導入したことで試行を自動化することができ、手間を大幅に減らすことができました。 実験でえられたクラスタリング結果はまだ満足のいくレベルではありませんでしたが、今回紹介した方法で、改良のための別の工夫や評価指標を採り入れた試行を重ねていくこともできます。
これまで 3 回にわたって、素人が、文書のグループ分類を題材として、前処理から想定応用先まで、それぞれの実現に必要な自然言語処理や機械学習のアルゴリズムと手法、指標の数々を基礎から学び、選択し、試行してきました。 経験則として常識になっていそうな事柄でも、その源である経験を積むためにあえて段階を踏んで実行してみました。 「素人がトピックモデルを試してみた」シリーズはこの記事で一旦の終了となりますが、身の回りの文書データはこうしている間にもどんどん増えています。 この記事自体もそのひとつです。 機械処理向けには書かれていない、これらの文書データを十二分に活用するための手段として、ここまで紹介してきたような知識と経験(と”あがき”)を活かしていこうと考えています。
(この blog 記事はnagao、ももいやすなりの共著です。)
脚注:
- scikit-learn の公式サイトは “scikit-learn: machine learning in Python — scikit-learn 0.20.2 documentation“。[↑]
- scikit-learn に実装されているクラスタリング評価指標は、公式ドキュメントの “2.3.9. Clustering performance evaluation” に説明とともに列挙されています。[↑]
- Romano, Simone, Nguyen Xuan Vinh, James Bailey, and Karin Verspoor. “Adjusting for chance clustering comparison measures.” The Journal of Machine Learning Research 17, no. 1 (2016): 4635-4666.[↑]