GRPOファインチューニング:はじめてのReward Learning
2025年03月04日 火曜日

CONTENTS
大変お久しぶりです。九州支社のとみーです。
つい先日弊社のAIの取り組みに関して「IIJ ✖️ AI活用」で藤本が述べたように、「初めに個人あり」な側面がありまして、私もその個人の一人なんだろうと思ってます。
その輪を広げる過程で社内でも色んな箇所で個人的に取り組む人がいて、その人たちが徐々に集まって社内でAIコミュニティを形成したりしています。
また、個人同士のつながりがわりかし強いのも特徴で、私自身常日頃「社内でローカルLLM APIサーバを構築・運用してみた話」を執筆してるSOC所属の増井だったり、と情報交換しながら・・というか、ほぼ一緒に今回のネタでもありますGRPOファインチューニングを取り組んでいたりします。
そうした活動を通じて、前述の藤本率いるワーキンググループとも連携したりで、九州に閉じてるわけではなく、全社的にコツコツと取り組みを広げながら連携の幅を広げている・・というのが現在の状況でもあるのかな。
今回はまさにそのGRPOファインチューニングなるものに挑みました。
謝辞
今回の記事は私の記事としてリリースしてるんですが、実際には先に紹介したSOC所属の増井と技術情報を交換しながら実践した内容になります。
一種のタッグプレイからなる成果物として見てもらえればありがたいです。
DeepSeek-R1が盛り上がってますね
DeepSeek-AIという中国発のベンチャー企業がすごいものをリリースした!その名も「DeepSeek-R1」!
- 開発費用の低減を図ることができた
- A800/H800など、中国専用モデル(いわゆる性能制限版)を用いたファインチューニング
- RLHFという莫大なコストを必要とする仕組みなしでの強化学習(Reward Learning)
こんな感じでいろいろ騒がれていると同時に、特にDeepSeek-AIが提供するAPIには
- 使用許諾内にプライバシーデータの扱いがちょっと怖い
- 設備設置場所はがっつり中国国内
- 収集したデータは学習にがっつり使う
- アライメントが不十分で、公序良俗に反した質問も平気で答えてしまう
などリスクもあり、とある日の国会答弁とかで議員さんが力説してるのをテレビで一瞬見かけたりもしまして。何とも色んな疑問符を投げかけるモデルが登場したものだと思いまして。しかしながら、このモデル自体がオープンウェイトモデルとして提供されただけでなく、arXiv.orgに論文草稿も公開されており、そこで使われた技術的なノウハウが惜しみなく公開されていることから、様々な派生モデルが生まれ、それを駆使してローカルLLMとして動かしたりしてるケースがいろいろ見受けられます。
また、さすがにローカルモデルとして動かすのが難しいDeepSeek-R1本家モデルもオープンウェイトモデルとして公開されているため、これを用いて様々なLLMクラウドサービスベンダーがそのAPIを自前で公開してたりで、目立ったものとしてはMicrosoft AI ServiceとしてMicrosoft Azureを通したAPIでその質の高さを体験することができるようになってきています。これらはクラウドベンダー側の規約に従って公開されているものなので、先述するような設置場所や使用許諾等の問題はある程度クリアされた状態で利用することが可能です。
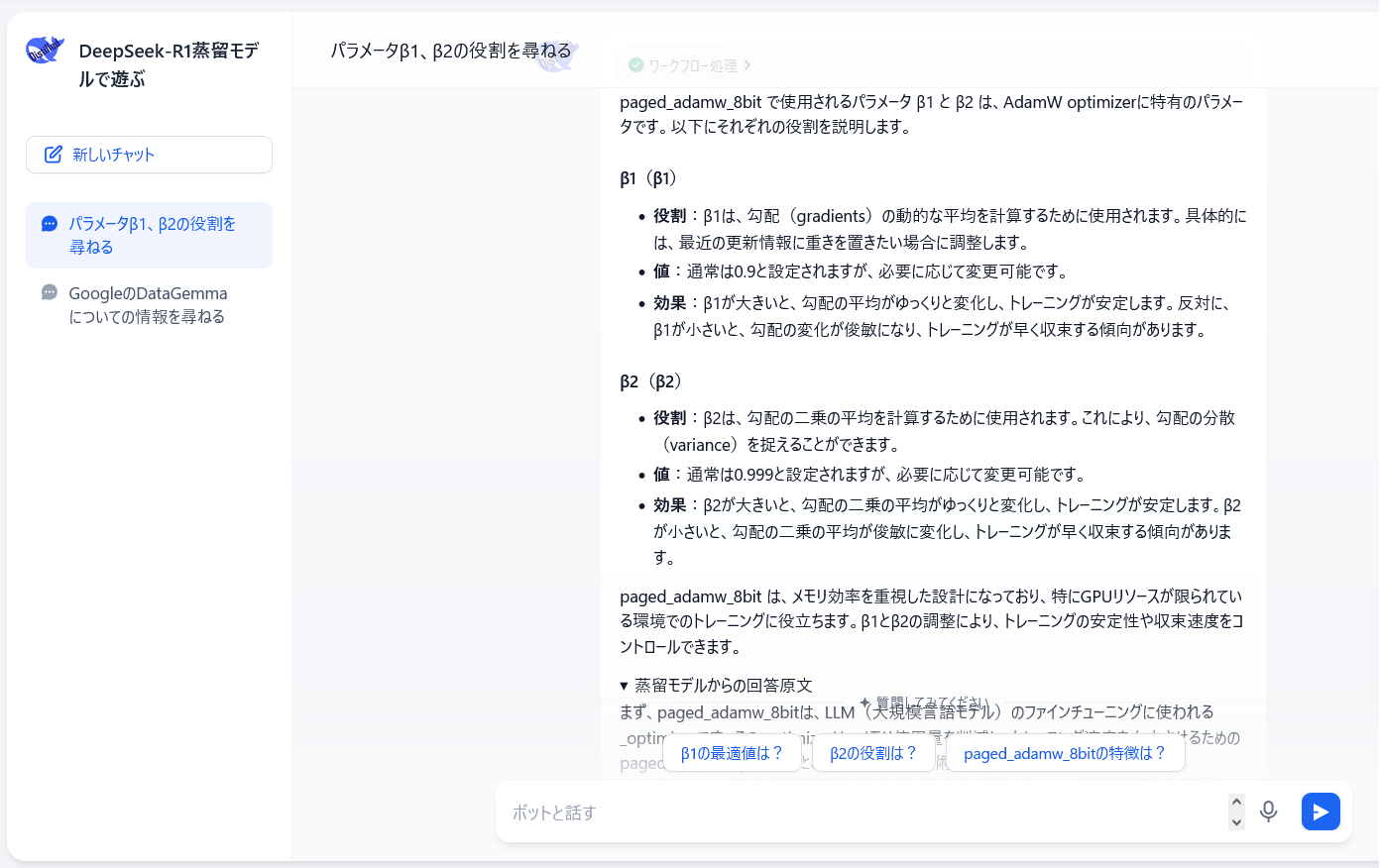
当初はあんまりこれと言って興味を持ってなかったものの、よくよく蒸留モデルに触れてみると、「こりゃスゴイモデルだ」って私や私の同僚たちも驚きまして、ダウンロードできるモデルを入手しては蒸留モデルを様々に動かして検証などをしてました。以下は、例えばファインチューニングでお世話になるオプティマイザであるAdamWで使用するβ1とβ2というハイパーパラメータについて調べてもらった内容です。
数式で理解するのが手っ取り早いのでしょうが、私はこれに非常に疎いため、実際の学習をする際に言語のどの部分に影響するのか、学習のどの部分に影響するのかを答えてもらいました。なかなか懇切丁寧なんですよ。
個人的なお気に入りは DeepSeek-R1-Distill-Llama-8b でして、これをGGUFフォーマットに直したunsloth/DeepSeek-R1-Distill-Llama-8b-GGUFの4bit量子化モデルです。これは何が好きかというと、後述する思考過程が必ず中国語か英語いずれかでかかれるようになっているんですね。
それ以上のモデル(14bモデルや32bモデル)になるとモデル自体が賢いからか、思考内容も日本語で書いちゃうことが多く、何となく自身の思考とシンクロしにくいんですね・・・
あ、ちなみに画面を見て分かるように、私は最近Difyを使いはじめまして、現在必死にこれのソースも追いかけているところです。
これはこれでどうやら近日中に0.x系から1.0系に切り替わりそうで、その様子をある意味「震えながら」見守ってる状況です。
GPROとは何か
GRPOというのは Group Relative Policy Optimization(直訳すると「グループ相対ポリシー最適化」)の略語であり、LLMに対して数学的推論能力を強化するために生まれた、新たなLLM最適化手法と言われています。報酬という考え方を利用するReward Learning、所謂強化学習の一手法です。
このアルゴリズムのベースは、それまでも学習アルゴリズムとしてメジャーな存在であった PPO (Proximal Policy Optimization/近接ポリシー最適化手法)で、強化学習の一手法です。特に医療・金融分野のAIを強化する際に利用されるケースが多いようです。
例を挙げると私が好んで使用するAXCXEPTさんのEZO-Humanities-9b-Gemma2-itというモデルは、この手法もファインチューニング手法の中に盛り込んでその品質向上をさせていることが分かっています。(モデルのメタ情報を見たときに、この手法を2回繰り返し実行してそうな形跡がちらっと見えました。)
個人的に「うわー、やったなー」と感じたポイントは、OpenAIがそれまでo1シリーズで実装してはいたものの秘匿していたReasoningという手法の全てとは言えませんが、Reasoningの裏側を「こういうやり方がある」という感じで表に暴いたことじゃないかなと思います。DeepSeek-R1やその蒸留モデルに触れた人は分かると思うのですが、これらのモデルが回答するプロンプトには、<think>というタグで囲まれた「思考過程」の情報が丸々表示されます。以下は蒸留モデルである、DeepSeek-R1-Distill-Qwen-14bに対して「DeepSeek-R1はどうしてここまで賢いの?」という質問を行ったケースの回答内容です。

最終的な出力は青文字部分だけになります。ただ、全体のトークン出力スピードはほぼ一定であることが多く、赤文字部分が表示されないがゆえに、はた目から見ると「長らく考え込んでるように見える」わけですが、実際には最終的な回答を書くための内容固めの文章をただひたすら書きまくってるという動きになります。
この仕組みは非常に理にかなっていて、ワタシは「LLMは言い訳を重ねれば重ねるほど頭がよくなる」と表現しています。
LLMは結論から話すことが大の苦手なのです。それは、今LLMに用いられてるDecoderオンリー型のTransformerベースのモデル全部に共通する特性です。
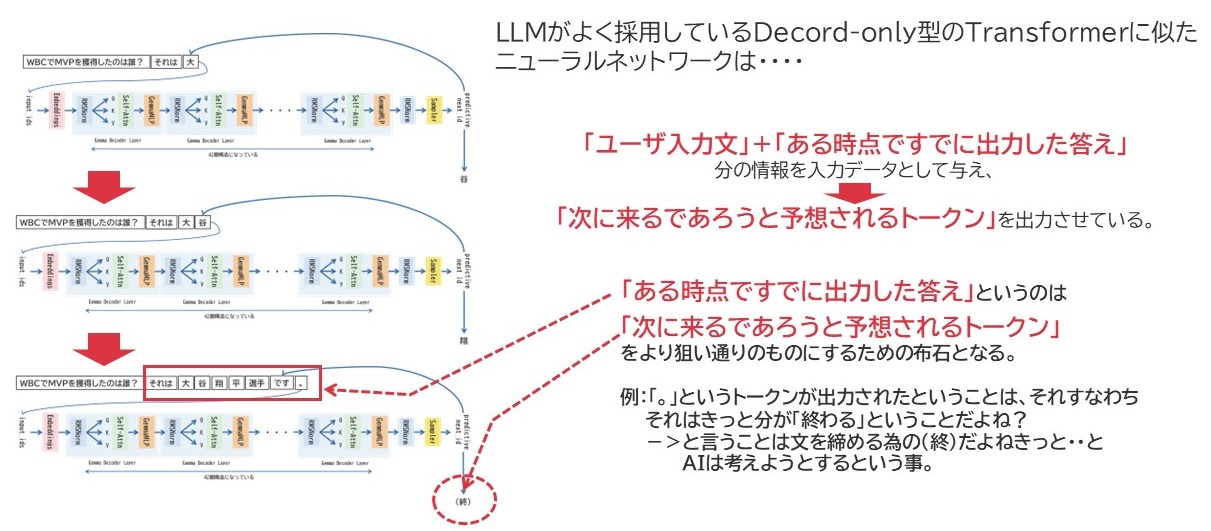 上図は「WBCでMVPを獲得したのは誰?」という質問を例に、その出力過程をGemma2-9b-itの模式図を使って説明しているものなのですが、LLMが次のトークンを予想する際は、質問文字列の情報だけでなく、その直前までに出力しているCompletionのトークン列すべてを繋げてそこから予測を行うようになっています。つまり、出力途中の回答は、次のトークンを予想するための布石になっているのです。
上図は「WBCでMVPを獲得したのは誰?」という質問を例に、その出力過程をGemma2-9b-itの模式図を使って説明しているものなのですが、LLMが次のトークンを予想する際は、質問文字列の情報だけでなく、その直前までに出力しているCompletionのトークン列すべてを繋げてそこから予測を行うようになっています。つまり、出力途中の回答は、次のトークンを予想するための布石になっているのです。
今回のGPROファインチューニングでは、論理的な過程を記述したデータセットを活用することで、Reasoningの癖付けを行っていると考えるとよいでしょう。
今回行ったGRPOファインチューニング
今回はUnsloth-AIが公開しているJupyter Notebookに記述されているコードをもとにファインチューニングを行いました。
- データセットはOpenAIが提供するGSM-8kというデータセットを使用しました。
- チューニングモデルはMicrosoft Phi-4を使用しています。14bパラメータサイズを持つ優秀なLLMです。
- モデル実行はUnslothというライブラリを使用します。これを活用することでメモリリソース・GPU利用の効率を引き上げます。
- チューニングに使うTrainerはHuggingfaceが提供するtrlライブラリのGPROTrainerを使用します。
- 4bit量子化によるLoRA学習を実行させます。
- AttentionブロックのQKVO、FFN全域全層をチューニング対象とします。
- GPUにはNVIDIA RTX6000 Ada Generationを利用しています。
- このGPU、CAD用途を目的として供給される所謂旧Quadro系列のハイエンドGPUです。
旧Tesla系のミッドレンジであるL40Sとほぼ同等の性能を有しています。 - VRAMは48GB搭載してるので、今回のファインチューニングにはもってこいという感じになりました。
- このGPU、CAD用途を目的として供給される所謂旧Quadro系列のハイエンドGPUです。
学習に関する処理の流れは下図のようになっています。
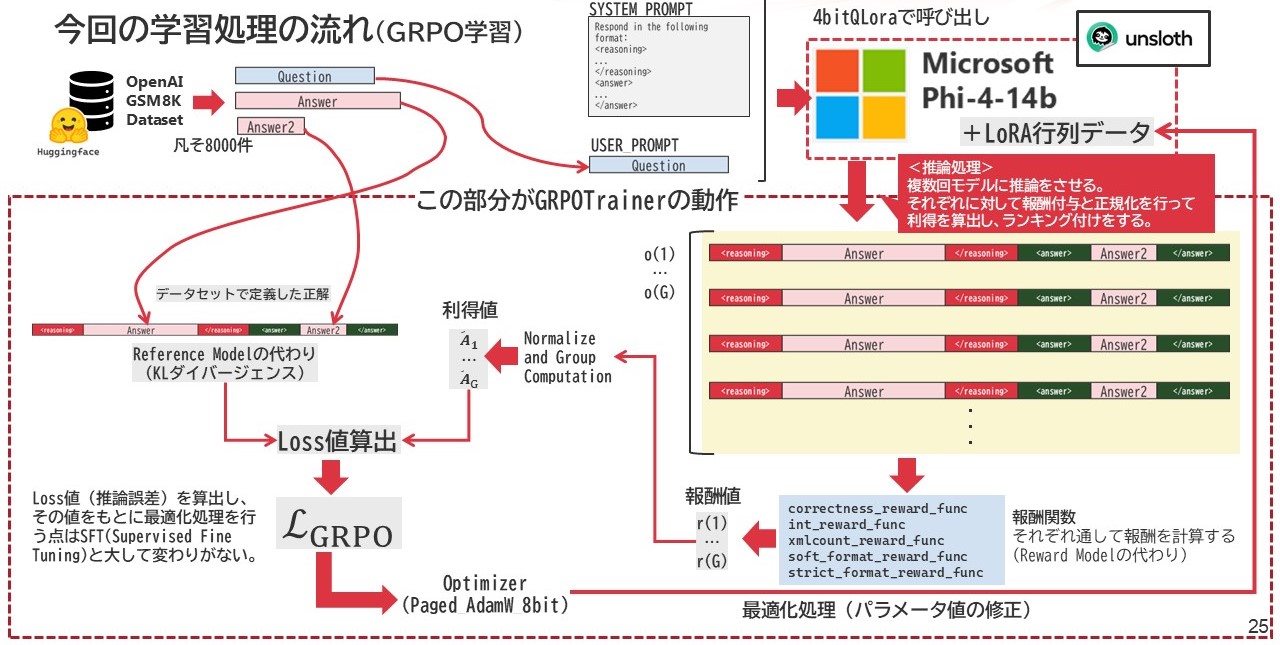
通常、強化学習を実行するには、それを評価するための評価モデルが必要であり、その為のリソースなどを別途確保しなければならないのですが、今回そのモデルを
- 報酬を支払う役割は、様式をがっちり組むための報酬関数
- 内容の逸脱を防止するReference Modelの役割は、正解データ群(データセット側のAnswer部分)
が代替することで、余計なGPUリソースを要求しない構造になっています。
Optimizerについては、メモリ削減を狙いPaged_AdamW_8bitが選択されています。
Unsloth提供のJupyter Notebookの内容について
Unslothが提供するJupyter Notebookですが、以下のような構成となっています。
 コードとして肝心な部分となるところを記述していきますね。
コードとして肝心な部分となるところを記述していきますね。
Unsloth
そもそもUnslothって何だ!?
という話ですが、界隈では割と当たり前に使われてるような印象も受けるんですが、学習処理を「高速化」するためのPythonライブラリです。
Unsloth-AIという会社は現在アメリカに場所を構えるオーストラリア出身の2人兄弟が創業した会社で、GitHub Acceleratorという支援プログラムにおいて、2024年に受賞を果たしてその資金援助を受けながら様々なLLMや便利なライブラリを開発しています。その中で中核となるライブラリが「Unsloth」です。
Unsloth-AIはこのライブラリを「Pytorchの互換ライブラリ」として動かします。Pytorchの命令がやってきたときに、従来のPythonカーネルではなく、互換性を持ちより最適化レベルを引き上げたTritonという独自カーネル向けに書き換えて実行することでCPU/GPU/メモリの動作効率を向上させることで高速化を実現させています。
使い方は「FastLanguageModel.from_pretrained()」をモデル呼び出し時に使うだけです。これだけで特にメモリ使用量の削減に大きな効果を発揮します。現状Llama3.1-8b-itモデルのGRPOファインチューニングには通常のライブラリ構成だと40GiBほどメモリを消費するんですけど、Unslothを使用するとこれよりパラメータ数の多いPhi-4(14B)モデルのGRPOファインチューニングがわずか35GiBで実行できました。
ただ、今のところこのUnslothも万能という訳ではなくて、実は2025年2月時点ではマルチGPUには対応できていないようです。GitHubのDiscussionとか拝見すると、色々と大変そうです。なので、マルチGPU環境で実行する際は、 CUDA_VISIBLE_DEVICES=0 を例とするように環境変数できちんと使用するGPUを特定したほうがよさそうです。
この辺り、実は当方環境ではSlurm Workload Managerを使ってたので、そのGres機能で縛れるかと思ったら縛れず。自動検出したGPUと使いたいGPUが合わずにエラーになったりと苦労しましたので、この辺り要注意ポイントっぽいです。シングルGPU構成においては何も気にすることなく利用できました。
マルチGPUで処理したい場合は、おとなしくaccelerateとの連携で通常通り動かしたほうがよさそうです。
DataPrep処理
今回、GSM8kというOpenAIが公開しているデータセットを使用します。
このデータセットのGSMとは「Grade School Math 」ということを示しており、いわゆる学校で習う算数問題であることを示しています。凡そ8,000件ほどあるので「8k」がついてるのかなと思われますけども、学校で習う算数問題8,000問と言うと分かりやすいのかな?
すべて英語で書かれていて、問題・答えのセットは以下のように記述されています。
Questionの記述例:
Sansa is a famous artist, she can draw a portrait and sell it according to its size. She sells an 8-inch portrait for $5, and a 16-inch portrait for twice the price of the 8-inch portrait. If she sells three 8-inch portraits and five 16-inch portraits per day, how many does she earns every 3 days?
(日本語訳)サンサは有名な画家で、肖像画を描いて、そのサイズに応じて販売することができます。彼女は8インチの肖像画を5ドルで、16インチの肖像画を8インチの肖像画の2倍の値段で販売しています。もし彼女が1日に8インチの肖像画を3枚、16インチの肖像画を5枚販売したとすると、3日ごとに何枚の肖像画を販売することになるでしょうか?
Answerの記述例:
Sansa earns $5 x 3 = $<<5*3=15>>15 every day by selling three 8-inch portraits. The price of the 16-inch portrait is $5 x 2 = $<<5*2=10>>10 each. So, she earns $10 x 5 = $<<10*5=50>>50 every day by selling five 16-inch portraits. Her total earnings is $50 + $15 = $<<50+15=65>>65 every day. Therefore, the total amount she earns after 3 days is $65 x 3 = $<<65*3=195>>195. #### 195
(日本語訳)サンサは、8インチの肖像画を3枚売ることで、毎日5ドル×3枚=15ドルを稼いでいる。16インチの肖像画の価格は、5ドル×2枚=10ドルである。そのため、16インチの肖像画を5枚売ることで、毎日10ドル×5枚=50ドルを稼いでいる。彼女の総収入は毎日 $50 + $15 = $<<50+15=65>>65 です。したがって、3日間の総収入は $65 x 3 = $<<65*3=195>>195 です。 #### 195
ここで特徴的なのが、Answerの内容の末尾にある「####」です。
これは計算過程と最終回答結果の間を仕切る役割を持ってるようです。今回公開されているJupyter Notebookファイルではデータ取り込み時に、Answer内の「####」という文字列をデリミタとして、Question, Reason, Answerの3つの要素に分けます。デリミタを境に手前がReason、後がAnswerとなります。

GRPOで行われる推論・報酬付与処理
続いて報酬関数の定義が記述されています。これに関しては5つの報酬関数が定義されています。
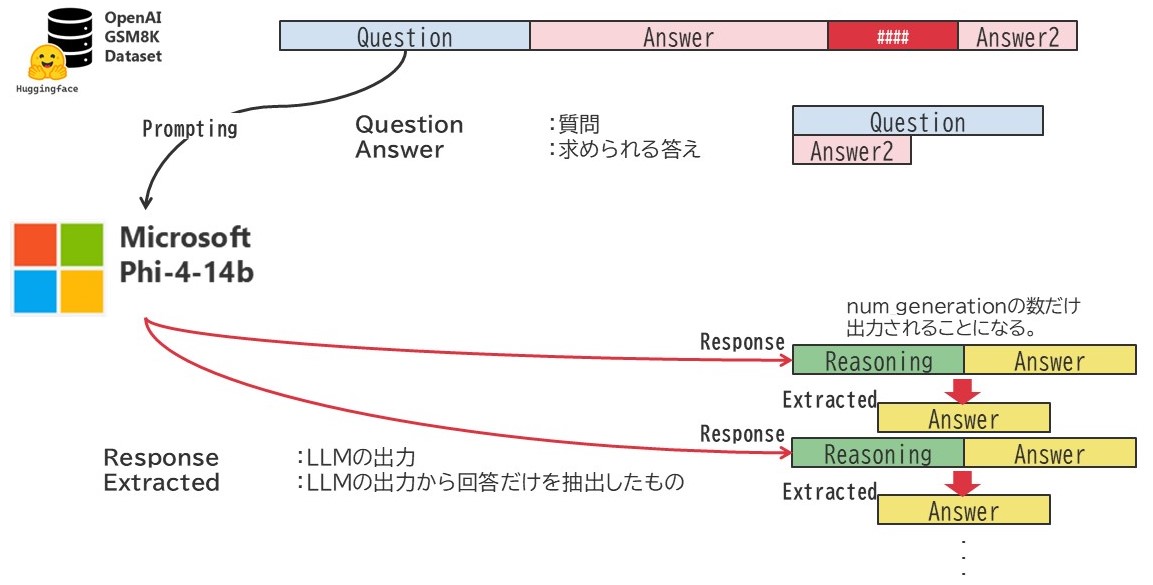 先述したデータセットは取りこんだ時点で元々のQuestion/Answerから、Question/Reasoning/Answerの3要素に再分割されてQuestionは指定されたSYSTEM_PROMPTと共にLLMへ推論要求として送られます。LLMはそこからResponseを返しますが、SFTのように1step1度きりではなく、予め指定された「num_generation」の値に従い複数回推論処理を行います。つまり、想定される回答を候補として複数回実行させるわけですね。
先述したデータセットは取りこんだ時点で元々のQuestion/Answerから、Question/Reasoning/Answerの3要素に再分割されてQuestionは指定されたSYSTEM_PROMPTと共にLLMへ推論要求として送られます。LLMはそこからResponseを返しますが、SFTのように1step1度きりではなく、予め指定された「num_generation」の値に従い複数回推論処理を行います。つまり、想定される回答を候補として複数回実行させるわけですね。
このResponseにはReasoning部分とAnswer部分が混じっており、これからAnswer部分のみを抜き出したものをExtractedとして扱います。
こうして得られたデータ(Question/Answer/Response/Extracted)が1ステップごとにリスト配列でまとめられ、各報酬関数に送られます。
そして、各報酬関数はそれぞれのもつ評価基準で出てきたResponse/Extractedの内容を評価します。
報酬関数は一定の順序に沿って実行されるようです。その順で記述していきます。
- xmlcount_reward_func
タグの登場回数をカウントされます。条件は「それぞれ以下の通り」です。- 「<reasoning>」 が1回のみ登場⇒0.125点加算
- 「\n</reasoning>\n」が1回のみ登場⇒0.125点加算
- 「\n<answer>\n」が1回のみ登場⇒0.125点加算
- 但し、Answer区間より後に余計な文字が存在する場合はその文字数×0.001点減算
- 「\n</answer>」が1回のみ登場⇒0.125点
- 但し、Answer区間より後に余計な文字が存在する場合はその文字数×0.001点減算
- soft_format_reward_func
想定されるとおりの形式で記述しているかどうかをチェックします。その内容は以下の通りです。
正解すると0.5点が付与されます。
【<reasoning> タグで囲まれた任意のテキスト】+任意の空白文字+ 【<answer> タグで囲まれた任意のテキスト】 - strict_format_reward_func
想定されるとおりの形式で記述しているかどうかをチェックします。その内容は以下の通りです。
正解すると0.5点が付与されます。- 「<reason>\n」で開始していること
- その次に任意の文字がゼロ回以上繰り返されること
- その次に「\n</reasoning>\n」が続くこと
- その次に「<answer>\n」が続くこと
- その次に任意の文字がゼロ回以上繰り返されること
- その次に「\n</answer>\n」が続き、文字列が終結すること
- int_reward_func
<answer></answer>区間の文字列において、それが整数であることをチェックします。
正解すれば0.5点付与されます。 - correctness_reward_func
<answer></answer>区間の文字列において、それが正解文字列と一致することをチェックします。
正解すれば2点付与されます。
こうして得点を重ねた結果がトレーニング設定で指定される推論パターン数(num_generate)の数だけ要素を持ったリスト型配列で取得されます。これが r:報酬値 となります。さらに、その報酬値に対して以下の計算を行って、A:利得値 というのを算出します。
算出は以下の式に従って行います。
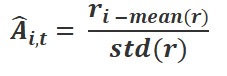 左辺がある推論パターンにおける利得値、r(i)が報酬値、mean(r)はそのケースにおける報酬値全体の平均値、std(r)はそのケースにおける報酬値全体の標準偏差です。
左辺がある推論パターンにおける利得値、r(i)が報酬値、mean(r)はそのケースにおける報酬値全体の平均値、std(r)はそのケースにおける報酬値全体の標準偏差です。
こうして利得値が各回答パターンに適用され、リスト配列として出力されます。この内容は、その問題ケースのグループとして、相対的にどの程度本来すべき回答に見合ったものであるかを示す指標になります。通常こうした評価は人間の評価フィードバックが絡むことが多いわけですが、それを一切介することなく、自身で出力した様々な回答パターンを相対的に評価した結果を参照することでカバーしているという点で非常に大きな意味を持っています。
これが後述するKLダイバージェンスの値と組み合わせられ、さらに細かい計算が為されたうえでloss値としてOptimizerへ送られ、あとはSFTの時と同じようにOptimizerが必要に応じて修正指令を出すわけですね。
これら報酬関数で設定されているルールは、あくまでGSM8kのような、算数をベースとしたデータセットを前提にして組まれています。もう少し高度な推論をさせるための学習をさせるのであれば、RewardModelを準備し、そこで自動採点をさせ、その結果を出力することになります。
Train the model
過去にSFT(SuperVised Fine Tuning)の例をお見せしたことがあるような気がしますけれど、全体的な構成は大体SFTと変わりません。ただ、Trainer設定は今回方式が異なるため、それなりに内容が変わってきます。
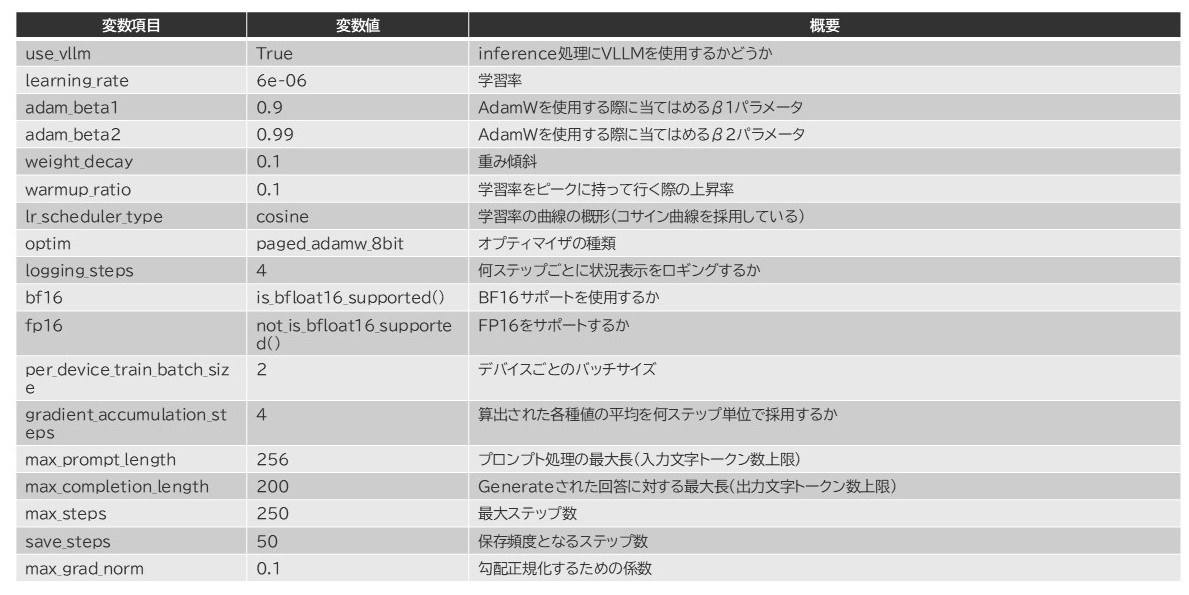 GRPOとして特殊なパラメータとしては、max_prompt_lengthとmax_completion_lengthの2つです。
GRPOとして特殊なパラメータとしては、max_prompt_lengthとmax_completion_lengthの2つです。
書いてる通り、最大入力トークン数と最大出力トークン数です。これはモデル特性に合わせて設定することが望ましいようで、あまり短すぎると推論が入りきれずに報酬値が低くなることがちょいちょい確認されています。
ところで上記の表、一つ変数が抜けてまして。「max_generations」という値があります。LLMが回答候補を出力する個数を示しているのですが、この値はデフォルトが6となっており、それが最適値です。必要に応じてメモリ節約のために4に減らすことがあります。
学習処理を実行させた結果
今回は、この処理を250ステップ実行させています。バッチサイズは2にしてましたので、およそ500ケース程実行した形になります。
学習量としては全然少ないんですが、この学習処理の特徴として「あるところから突然学習効果が出始める」ということがあるようで、Unsloth提供のNotebookはちょうどそれを理解するにちょうどよいポイントで留めてくれてるようです。
ハードウェアの負荷状況をまとめてみました。
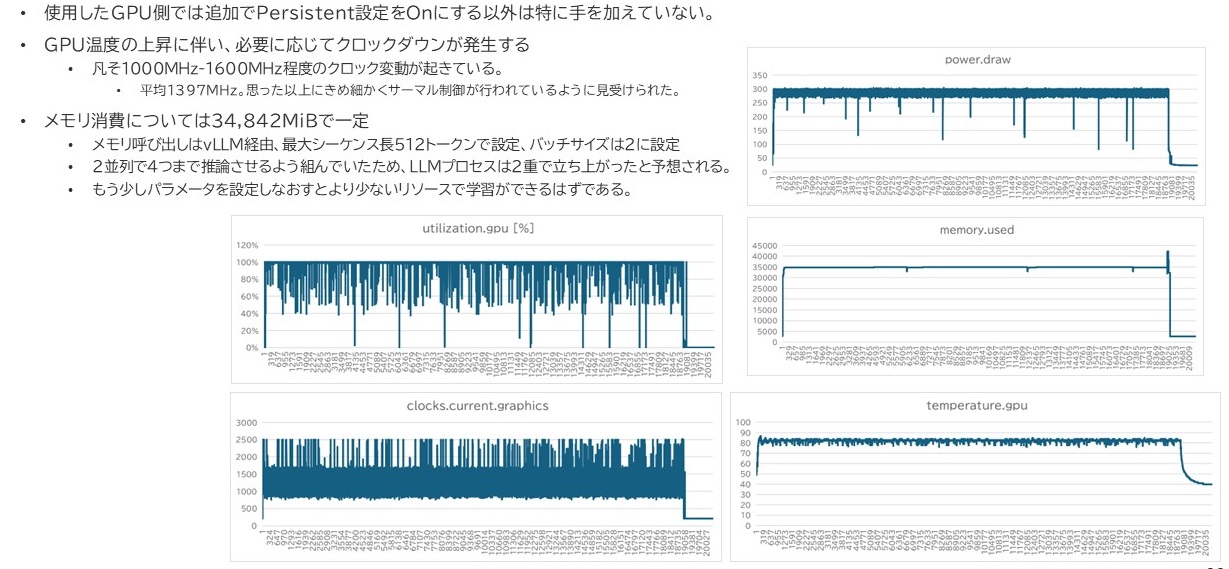 まず、このGRPO学習ですが、過去に実行したSFT(Supervised Fine Tuning)とは比べ物にならないほどの膨大な時間を要します。
まず、このGRPO学習ですが、過去に実行したSFT(Supervised Fine Tuning)とは比べ物にならないほどの膨大な時間を要します。
今回、250ステップという少ないステップ数、500ケースの学習させただけですが、全体で5時間半程度かかっています。
ただ、これは動作している機種があくまでワークステーションであり、空調の整ったラックマウントサーバで処理させた場合はもう少し速くなるのだろうなとも思います。それは、左下(クロック数)、右下(温度)のグラフを見ると一目瞭然です。最高クロックで動作している時間はほぼありませんで、基本的には1600MHz付近をうろうろしていました。
メモリ使用量はUnslothの効果がかなり出ていたと感じます。実はこれと別にLlama-3.1-8b-itを通常のAcceleratorで学習させていますが、その際に必要となったメモリ容量は同じバッチ数、同じ回答数で40GiBほどに達しました。それに対して倍近いパラメータ数を持つPhi-4をチューニングしてLlama-3.1よりも少ないメモリ容量で学習ができてるわけですので、かなりリソース負荷は小さくなってるのだろうと感じています。
学習状況を確認する
続いて、学習状況をグラフに表現してみます。すると以下のようになりました。
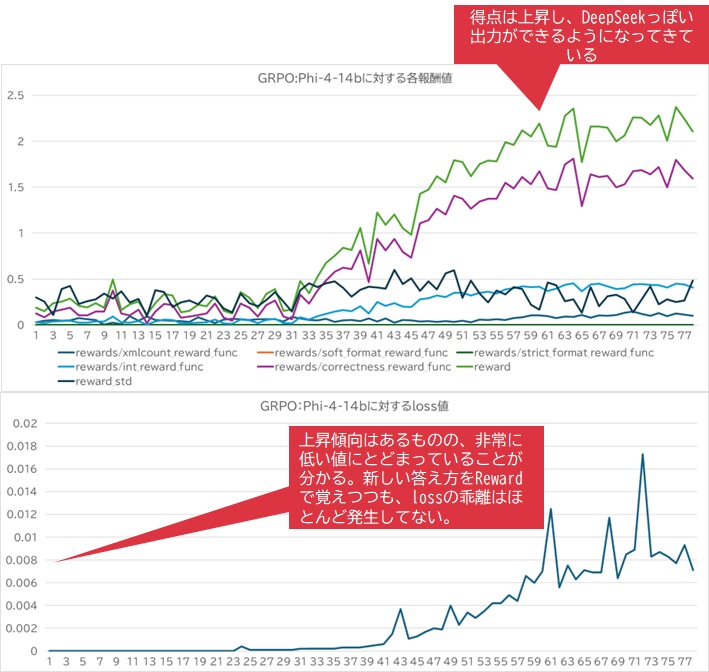 途中から急激に報酬の値が上がっていることが確認できるかと思います。このグラフでは、
途中から急激に報酬の値が上がっていることが確認できるかと思います。このグラフでは、
- 緑色が全体的に算出された推論結果を取りまとめた場合のリワード値
- 紫色がcorrectness_reward_funcで算出されたリワード値
- 黒っぽい色はリワード値の標準偏差
- 水色はint_reward_funcで算出されたリワード値
- ギリギリ地べたの一歩手前みたいなところを這ってるのは xmlcount_reward_funcで算出されたリワード値
- soft_format_reward_func, strict_format_reward_funcの値はともに常時ゼロ
ということが示されていました。また、最終的にオプティマイザに送り込まれるloss値ですが、途中から徐々にわずかではありますが盛り上がることが分かっています。時々スパイクを描くような線になっていますが、それは短時間で補正されているように見えます。
これともう一つ重要なのが、正解データセットと回答内容の中で得られる「KLダイバージェンス」という値です。
これは「あくまで過程と回答はこれと等しくあること」として、タグの形式等は一旦置いて、答えがどこまで近似しているかを判断する指標です。文章の各ベクトルを取得し、そのベクトル間の近似度を測ります。完全一致の場合は0になります。誤差が大きければ大きいほどその値は正値で大きくなるということになります。
形式にとらわれすぎて、回答内容そのものが崩れてしまう学習では意味がありません。KLダイバージェンスの役割は、回答の逸脱を食い止めるための手綱のようなものだと考えるといいのかなと思います。実際に学習させたときは、以下のようにlossグラフとほぼ同じような形状をとっていました。
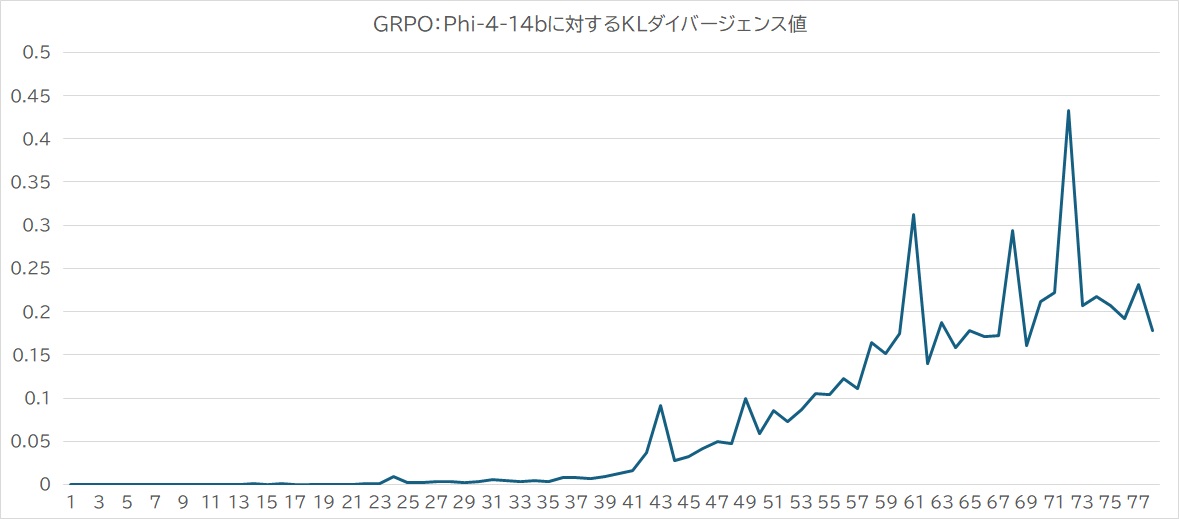
これらの結果から、学習は以下のとおり行われたものと考えられます。
- 前半から途中まで、正しい答えを出力はしていたものの、形式的には正しい記述が行えてない状況が続いた
- あるところから、形式に従わせる挙動が発生した。但し、この時正解内容から少しずれ始めたため、KLダイバージェンスが働き、オプティマイザ側の修正量が調整されたと考えられる
- その後、報酬値の大きさに従い、より報酬を得られるように強化学習の効果が表れ始めるが、その時点でも必要に応じてKLダイバージェンスによる学習量調整が発生して「ジワジワスコアが上がる」ような形でパラメータは修正され続ける
推論内容の参照
この時点でどのような推論が行われていたか?ですが、以下のようになりました。
 GRPOを行う前のPhi-4の推論は非常に単純に記述されているのに対して、GRPOを行ったPhi-4の推論は順序立った内容となっていることが分かると思います。
GRPOを行う前のPhi-4の推論は非常に単純に記述されているのに対して、GRPOを行ったPhi-4の推論は順序立った内容となっていることが分かると思います。
その際、癖付けを行った<reasoning>タグ、<answer>タグがきちんと挿入されていることが分かります。
これと引き換えなのか、<answer>タグの中身は数値だけになっていて、GSM-8kとしての世界ではありますが、人に対してチャットボットでこれを回答させたとき、恐らくHumanityなスコアはきっと低く採点されるでしょう。
算数問題じゃないものを推論させた
では、計算問題ではないものを推論させた場合、GRPOを学んだPhi-4はどうなるのでしょうか。結果は非常に面白いものになりました。
以下の映画タイトルのリストが与えられたとき、タイトルに含まれる都市名をすべて書き出しなさい。 ・バンクーバーからの挑戦 ・ロンドンの夢 ・織田信長の生涯
これはELYZA社が公開している有名なデータセット、ELYZA-Tasks-100に収録されている問題の一つです。これをGRPO学習してないPhi-4は以下の通り推論しました。無事、正解はしています。
与えられた映画タイトルに含まれる都市名は以下の通りです。
- バンクーバー(「バンクーバーからの挑戦」)
- ロンドン(「ロンドンの夢」)
「織田信長の生涯」には都市名が含まれていません。
これに対してGRPO学習したPhi-4は以下の通り推論しました。
<reasoning>
まず、映画タイトルのリストを確認します。タイトルには以下のようなものがあります。
- バンクーバーからの挑戦
- ロンドンの夢
- 織田信長の生涯
次に、各タイトルから都市名を特定します。
- 「バンクーバーからの挑戦」には「バンクーバー」という都市名が含まれています。
- 「ロンドンの夢」には「ロンドン」という都市名が含まれています。
- 「織田信長の生涯」には都市名が含まれていません。織田信長は日本の戦国武将で、特定の都市名は記載されていないためです。
以上の考察から、リストに含まれる都市名は「バンクーバー」と「ロンドン」の2つです。
</reasoning>
<answer>
バンクーバー、ロンドン
</answer>
数学とは関係ない問題でしたし、言語体系も日本語なんですが、きれいにReasoningを行い、そして結果を導きました。
学習内容はあくまで以下のような感じでした。
- 問題文はすべて英語
- 解答は数値のみしか許容されない
- タグの設置を非常に厳しく見る特性がある
- 答え自体の正解・不正解もほぼ数値のみしか見ないことを前提にしている
上記のような学習の仕方にも拘らず、なぜこんな答えに持って行けるのか?というのは、DeepSeek-R1-Zeroの開発陣達も同様に思ったわけでして、これを彼らは「aha moment」と呼んでいます。意外と知ってる人も多いのではないでしょうか。脳科学者の茂木健一郎さんがよくテレビで紹介されていた「アハ体験」をまさかのDeepLearning Modelがやっているという事なんです。
GRPOがもたらす「アハ体験」
アハ体験という言葉の意味は「未知の物事に関する知覚関係を瞬間認識すること」。これを人々は「ひらめき」と捉えるかもしれません。
今回のGRPO学習では、まず学習元となるPhi-4自体がかなり高性能なDeepLearningモデルであり、自然言語処理の中でもかなりハイレベルなLLMに分類されること、多言語モデルであり、日本語と英語間のニュアンスに互換性を持たせられることから、学習中に学んだパターンと自身でもつ能力をうまく混ぜることができたようなのです。その結果、算数問題に限らずより汎用的な方法として自らReasoning手法を編み出し、それを自分自身に適用させることができたという事なのだろうと考えられます。
つまりは
- 今回Phi-4はGRPO学習を行う中で、Reasoning能力を身に着けて、順序正しく数式を並べていくことで正確な値計算ができるように学習していく。
- ところが、途中Phi-4は同じような論理で文章をきちんと順序良く並べることにより、明確な論理にたどり着けることを理解したようだ。
- 元々、Word2Vecやベクトル近似などもそうですけど、LLMに適用されている技術というのは「いかに数値計算的な感覚で言語をコンピュータが扱えるようになるか?」という考えのもとで理論が組み立てられている側面がありますよね…恐らくそこに似たものがあるのではないかと感じています。
- 汎用的に、同じような理論立てで一般的な文章やQAに対してもより明解な内容をこたえられるよう中身が磨かれて行った
ということも考えられるわけですね。実際にじゃぁ今回主に使うモデルの中でELYZA-Tasks-100で評価をしたらどうなるかを確認してみました。結果は面白いものになりました。今回のLLM評価にはOpenAIのGPT-4oモデルを使用しています。AOAI経由で利用しています。
 なんとDeepSeek-AIがつくったQwen-14b蒸留モデルよりも高いスコアを叩き出しました。予想以上の高得点をマークしてマジびっくり。
なんとDeepSeek-AIがつくったQwen-14b蒸留モデルよりも高いスコアを叩き出しました。予想以上の高得点をマークしてマジびっくり。
ただ、O1-miniのスコアは超えてるものの、これはAPI応答が遅れたりしたことによって正常な回答が出力できないケースが存在したことが原因で下がったために参考値として扱ってるのですが、それを考慮しても割と肉薄する値を記録しているように見受けられました。実際全部答えがキレイに帰ってきたらどうなっていたのだろう・・
ローカルLLMの中でも、GRPOを有効化したPhi-4はかなり高い値を記録しているといっても過言ではないかと思います。
ただ、GRPOを有効化した状態で実行させるには、システムプロンプトは以下の内容を必ず含める必要があります。
Respond in the following format: <reasoning> ... </reasoning> <answer> ... </answer>
これは、学習時に仕込んだSYSTEM_PROMPTの中身です。
学習時、必ずモデルはこの内容を受けることを前提にしてケースが組まれていましたので、その経験を使用させるためのトリガーとして上記を仕込む必要があります。これがない場合、GRPOに基づくReasoningを使った回答は行いません。このように、システムプロンプトに対して一定の制約が発生するのもGRPO学習の特徴となっています。
また、出力はタグ含めて丸ごと出力されます。私がこれを利用する際は「タグ付き全文」と「本文だけ」の2パターンで出力させてます。
回答内容を理解する際に、本文だけではあまりにも「答えそのものだけ」を出力させることになり、情報が少なすぎるためです。
本文だけを抽出する際、必要に応じて後処理にLLMを介させ、出力文を整理したうえで出力するような処理を入れていたりもします。
DeepSeek-R1蒸留モデルも同様で、Reasoningさせて正常な結果を得るには以下の条件が必要となっています。
- Temperatureを0.5-0.7の間にセットすること
- User Promptの様式として
<|begin▁of▁sentence|><|User|>AIによって私たちの暮らしはどのように変わりますか?<|Assistant|>という形式で入力する必要があること - SystemPromptには「何も書かない」こと
これも恐らくGRPO学習をさせる過程でそうした記号を埋め込んだことが要因となっているのだろうと推察されます。
但し、DeepSeek-R1の場合、ものすごく回答本文の内容が充実してるのは、今回GRPOだけを行ったPhi-4とは明らかに違っていました。これは、DeepSeek-R1の場合、GRPO実行後にSFTを追加で行っているためだろうと考えられます。回答レベルの調整をそこで行っている可能性があるなと感じました。
逆にOpenAIのo1やo3はそうしたことを考慮することなく、従来のGPTと同様のプロンプティングでやり取りができますので、そうしたところがOpenAI側のReasoningモデルは強みとなるのではないでしょうか。
しかし、一定の癖がついてしまうとは言え、ローカルLLMで手軽にGRPO学習を通じてReasoningモデルを作れるというのは非常に大きなことだと思います。
実際、たった250stepしか実行していないこのGRPO学習したPhi-4でも、業務に活用していてとても重宝してるような状況ですから。現在私の参謀になってくれています。
特にDeepLearning基礎系の情報収集に威力を発揮してまして、非常に助かっています。
モデルからメソッド、ファインチューニング手法に注目しながら
DeepSeek-R1はこのGRPO学習を行った後、そこにさらにSFTで学習をさせたことで、きちんと一定の思考過程をまとめた内容を補足として記述できるような仕組みを実装し、適切な説明を伴った回答をさせるようなモデルに成長させています。
しかし、お国柄という所もあって、国家をより尊重するような回答などはかなり強烈に学習されているところがあります。そうしたものについては、<think>タグの中身が空っぽになったりしており、これはSFTの影響を強く受けているのだろうと考えられます。
これを逆手にとって、Huggingfaceを中心に、DeepSeek-R1完成までのプロセスを徹底的に見直してより汎用性を高めた「OpenR1」というモデルを構築しようという取り組みが行われています。
要はDeepSeek-R1に対して行ってきたプロセスをトレースし、お国柄的な不安定さをもたらす部分を見直し、よりグローバルで汎用的に使えるモデルの構築を目指すもので、そのコンセプトは以下のように記述されていました。現在進行形で進んでるようです。
DeepSeek-R1の技術報告書をガイドとして使用し、これを大まかに3つの主要ステップに分けることができます。
- ステップ1:DeepSeek-R1から高品質なコーパスを抽出して、R1-Distillモデルを再現する。
- ステップ2:DeepSeekがR1-Zeroを作成する際に使用した純粋なRLパイプラインを再現する。これには、数学、推論、コードに関する新しい大規模なデータセットのキュレーションが必要になる可能性が高い。
- ステップ3:ベースモデルから多段階のトレーニングを経てRLチューニングを行うことができることを示す。
他にも、Gemmaベースのモデルで大変お世話になってる日本でも随一の高品質LLMをオープンウェイトモデルとしてリリースしてるAXCXEPTさんは私たちよりずっと早い時期からこのメソッドに目を付けてPhi-4ベースに機能強化したモデルをリリースしています。
このように、私たちはそのメソッドに着眼点を置き、より論理的なモデルを組むにはどうしたらよいかと言ったところを可能なレベルで分析して、いいところ取りするにはどうしたらいいかを模索していく形で取り組みを続けています。
事前学習的なところはどうにもこうにも難しいところが多く、リソースもなかなか充足できるレベルで確保することは難しい面もあるんですが、そのメソッドを体験し、その仕組みを把握することで、どこまでそのLLMは適用できるか?を探っていくことは、それ自体はなかなか表に出ることは難しいですけど、取り組む価値があると感じつつ進めているところです。
引き続き、こうした取り組みを継続しつつ、IIJとしてAI知見のより高いレベルでの充実を図っていこうと思います。