IIJ用Kubernetesディストリビューション「IKE」の永続ボリュームについて
2021年04月30日 金曜日
CONTENTS
IIJ SRE部 牧野です。普段は SRE チームで主に設備部分の設計業務や、利用者からの問い合わせ対応等を行っています。
IIJ Technical NIGHT vol.10 の中で、IKE (IIJ Kubernetes Engine) を構成するコンポーネント群の紹介がありました。

CSI (Container Storage Interface) 自体は Kubernetes 1.13 で GA (General Availability/一般提供) となっていますが、CSI に対応したストレージはオープンソースで長年練りこまれてきたものから商用製品まで多数のものが存在してまだまだ過渡期でどれを使うのがいいとか悩んでいる方が多く、先日の IIJ Technical NIGHT の中でもストレージのことを気にされている方が多かった印象です。
今回はその中で「CSI Driver」として取り上げている永続ボリューム部分について取り上げます。
どんなもの
IKE では大別すると 3種類の永続ボリュームを用意しており、利用者自身で適切なストレージクラスを選択して利用しています。
厳密には異なるリージョンに存在するボリュームをマウントして使えるようにしていたり、 IaaS 提供基盤によってバックエンドで利用しているストレージが異なるため実際の種類は増えますが(多いのですが)、ソフトウェア部分の設計は同一です。
| ストレージクラス | 用途 |
|---|---|
| linstor | Pod とストレージの収容位置を一致させたブロックストレージ。ローカル NVMe SSD を使った低遅延なストレージメニューなどを提供できます |
| standard(IaaS) | RWO 用途のブロックストレージ。利用基盤によりますがバックエンドは IaaS 側から提供されるブロックストレージ、もしくはプロプライエタリなストレージです |
| NFS | RWX 用途を想定(ストレージクラス未指定の場合こちらから提供) |
※RWO: 単一のNodeのみが読み書き可能、RWX: 複数Nodeから読み書き可能
これらとは別にオブジェクトストレージなども利用していますが、今回の趣旨からは外れますので割愛します。
そして、NFS と standard については選定した IaaS 提供基盤のストレージ特性に依存する部分が多く今回は割愛します。
今回少し変わったストレージとして「linstor」についてご紹介できればと思います。
実現したいこと
SSD など高速なストレージデバイスが主流になりつつある今日、SAN(=Storage Area Network。以下 SAN と表記)を経由することで遅延が発生してしまい高速なストレージデバイスの利点(=特にレイテンシ視点)を生かし切れていないのではと推測しています。
具体的には、従来の HDD が前提のストレージであれば HDD プラッタの回転待ち時間が長く待ち時間の多くを占めるため、性能面で SAN 利用のコストはあまり目立たなく SAN 越しに HDD へ並列アクセスすることでディスク I/O 性能を稼ぐことができました。
しかし、高速なフラッシュメモリ等を前提とした場合 SAN 部分のオーバーヘッドが無視できなくなり SAN 越しの並列アクセスではなくなるべく CPU/バスに近いデバイスから優先してデータをやり取りする方がディスク I/O 性能高速化に寄与するのではないかと考えています。
また、同一ノード内からデータを取得することでデータ読み出しに対して SAN を経由する部分が少なくなるため、SAN に対する性能要件も比較的抑えることができるのではと考えています。
そして、このアプローチを取ることで性能の点でも利点がありますが SAN 部分やストレージ装置に対する要件を下げることができ費用面でもメリットを出せるのではないかと考えています(その代わり、データ保全とか性能保証、信頼性の視点では犠牲になる部分があると思います)
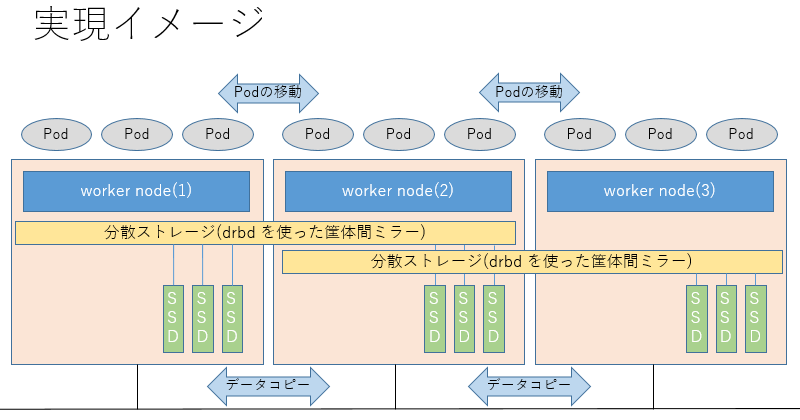
とはいえ、ノード間の Pod 移動や機器保守時のデータ保全は必要なので筐体を跨ぐデータコピー(SAN 越しの同期コピー)に分散ストレージ技術を利用して実現しました。
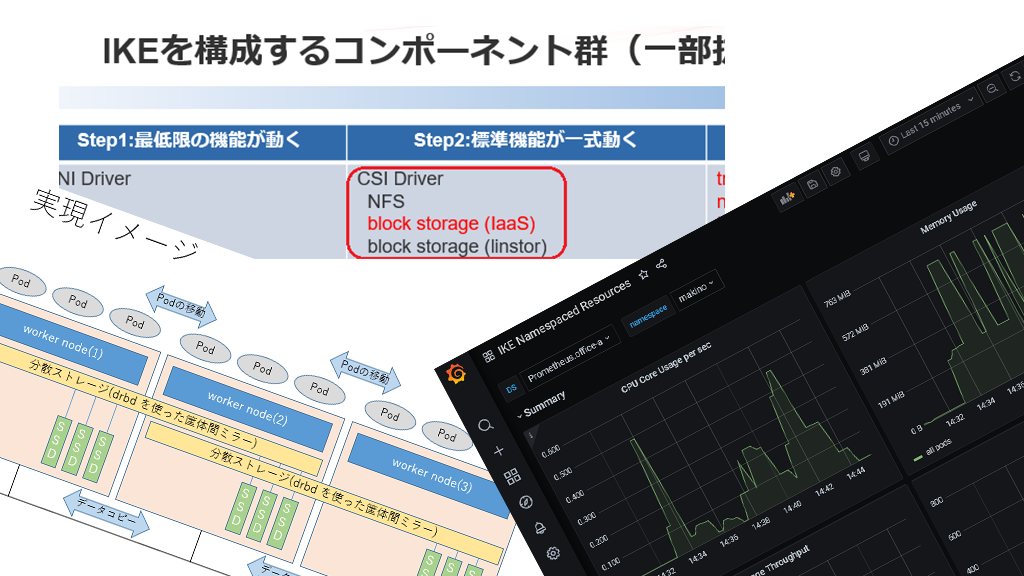
LINSTOR (LINSTOR CSI plugin) とは
Kubernetes の CSI にはオープンソース・商用のものを含め選択肢が多く、我々を含めどれを選択すべきか悩んでいる方が多いと思われます。IKE では LINBIT 社から提供されている LINSTOR を使ったストレージメニューを提供しています。
高速なローカルストレージの活用
複数の動作モードがありますが linstor-csi-node によって適切なラベルをノードに付けることで、例えばローカル接続した NVMe SSD 上に永続ボリュームが存在するワーカーノードでしか Pod が起動しないような制御をすることができます。
参考情報として、ストレージクラス部分のマニフェスト例を記載します(6行目の allowRemoteVolumeAccess と 12行目の volumeBindingMode の部分に注目してください)。
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: linstor parameters: allowRemoteVolumeAccess: "false" autoPlace: "2" storagePool: "pvpool-nvme" csi.storage.k8s.io/fstype: xfs provisioner: linstor.csi.linbit.com reclaimPolicy: Delete volumeBindingMode: WaitForFirstConsumer
allowRemoteVolumeAccess を false にすることで、ローカル NVMe SSD 上にデータが配置されている 2ノード以外には Pod を配置しないよう制御することができます。その代わり、リソース不足など何らかの理由で該当の 2 ノードへ Pod が収容できない場合は Pod 起動が Pending されますのでご注意ください。そのため kubectl drain を利用した Pod の収容変更等はいろいろ気を付けないといけなくなります。
volumeBindingMode についてですが、永続ボリュームを先行して確保してしまうと該当ワーカーノードがリソース不足だったり cordon 状態の時に Pod が起動できなくなってしまうため、この影響を緩和するため指定しています。WaitForFirstConsumer を指定することで初回の Pod 起動時(= Pod の収容位置が確定後)に永続ボリュームの確保を行い、ローカルマウントが可能なように Pod の収容位置を制御します。
つまり、「実現したいこと」で書いたようなローカル接続のディスクを利用した高速ストレージメニューの提供を考えた時の Pod 配置の制御ができ非常に重宝しています。
ストレージ性能(参考値)
弊社内で昨年度いくつかの分散ストレージソフトウェアを使って 2ノード間で筐体間ミラーを作成して永続ボリュームをマウントした Pod からストレージ速度を評価してみた感じでは、最も性能限界に達するのが遅くディスク I/O 性能の劣化が低かったのが DRBD9(+LINSTOR)でした。性能の面でも IKE で採用した理由の一つです。
具体的にはベンチマークソフト(fio)で I/O を発生させ、ディスクの種類とソフトウェア部分を変えて評価を行いました。その中で LINSTOR 部分のみを抜粋します。
デバイスの種類や条件、パラメータによって測定値は変わってしまうので値自体はあまり気にせず、物理ホスト上で直接計測した値との差を見ていただけると幸いです。
- NVMe SSD: Samsung PM983 3.84TB (MZ1LB3T8HMLA-00007)
- fio のパラメータ: ブロックサイズ: 16k, 並列実行数: 64, ファイルサイズは 8GiB
- ファイルシステム: xfs
- drbd9 のミラーリング Protocol: 同期(C)
- 左側の値が Pod 内から fio を実施した時の値、右側の値が同一構成の物理マシン上から fio を実施した時の値
| シーケンシャルリード | シーケンシャルライト | ランダムリード | ランダムライト |
|---|---|---|---|
| 2,472MB / 2,493MB/s (99%) | 599MB / 1,440MB/s (42%) | 2,125MB / 2,216MB/s (96%) | 528MB / 1,300MB/s (41%) |
| 151k / 152k IOPS (99%) | 36.6k / 87.9k IOPS (42%) | 130k / 135k IOPS (96%) | 32.2k / 79.3k IOPS (41%) |
ざっとまとめると以下のような感じです。
- 読み出し性能についてはほぼ NVMe SSD の速度そのまま(= SAN 側には出ていかない)
- 書き込み性能についてはデータ同期のため SAN 利用によるボトルネックは発生しますがおよそ SAN 経由で外部ストレージを利用する時と同等の速度
- 但し、今回 RDMA が使える環境ではなくソフトウェア実装の iSCSI イニシエータと同程度という判断です
気を付けなければいけないこと
LINSTOR を利用する場合、ストレージプールを構成するノード全てで LINSTOR のバージョンを揃える必要があります。バージョンが異なると「VERSION MISMATCH」 となり該当ノードの制御ができなくなります。
# linstor node list +-----------------------------------------------------------------------------+ | Node | NodeType | Addresses | State | |=============================================================================| | worker1 | SATELLITE | 172.16.1.100:3366 (PLAIN) | Online | | worker2 | SATELLITE | 172.16.1.101:3366 (PLAIN) | Online | | worker3 | SATELLITE | 172.16.1.102:3366 (PLAIN) | OFFLINE(VERSION MISMATCH) | | worker4 | SATELLITE | 172.16.1.103:3366 (PLAIN) | OFFLINE(VERSION MISMATCH) | | worker5 | SATELLITE | 172.16.1.104:3366 (PLAIN) | OFFLINE(VERSION MISMATCH) | +-----------------------------------------------------------------------------+
また、LINSTOR のバイナリパッケージ提供についてですが Ubuntu の場合 LINSTOR の最新版パッケージのみかつ 対応 OS については LTS 版最新 2 バージョンのみ公開となっています(但し商用サポート契約を結べばこの制約はありません)。
プロダクション環境で利用していくことを考えると、利用状況に合わせて後からワーカーノードを足したりすることが一般的だと思いますので、過去に構築したノードと LINSTOR バージョンを合わせるためには事実上全ノードで LINSTOR を適宜最新版に更新していく必要があります。
つまり、継続利用のためには LINSTOR パッケージだけではなく OS、Kubernetes などについても適宜最新版に追従してアップデートしていく覚悟が必要だと思われます。もちろん、商用サポート契約をすることで過去の LINSTOR パッケージを入手することはできるでしょうがこれによって根本解決する話ではないと考えています。
モニタリングとの組み合わせ
従来の IaaS だと、例えば共有ディスクが高負荷になるなど性能劣化を観測した時は以下のようなことをしていました。
- ストレージ機器の統計情報などから、高負荷状態を引き起こしていると推測されるボリュームを特定する
- 上記で特定したボリュームに紐づく利用者を特定する
- 上記で特定した利用者に対して利用状況を共有して改善を促す。利用者での対処が困難であれば何らかの方法で利用制限を行う
今回の主題からは外れますが、Exporter 経由で常時メトリクスを収集するようになり負荷状況の把握や利用者の特定について格段にやりやすくなりました。利用者への情報共有についても Grafana の「Share Dashboard」機能を使えば状況を見て欲しいダッシュボードを簡単に共有することができます。
オブザーバビリティ(可観測性)の実現についても、多くの製品やオープンソースのソフトウェアが存在してどんなやり方をしているのか興味あるところかと思われます。こちらについては今後別の機会にご紹介できればと考えています。
今後について
ストレージクラスの種類を増やしすぎると、利用者の理解が追い付かず適切な選択ができないのと分割損が生じたりするため現時点ではメニューを絞っているのですが、一部の利用者からはいろいろ要望をいただいていたりします。
- 永続ボリュームのファイルシステムに任意のものを選択したい(少なくても xfs, ext4 の 2種類を選択したい)
- ブロックストレージでも RWX(ReadWriteMany) もしくは ROX(ReadOnlyMany) で利用したい
- ストレージ障害によって全滅もしくは半壊は避けたい。ストレージドメインを指定して Pod を収容できるようにして、ストレージ障害時の影響範囲をコントロールしたい
- Volume Expansion に対応したストレージクラスを利用したい
- スナップショット機能を使いたい
- ストレージ側の機能でリソース制限や QoS を実現したい
- オブジェクトストレージなど容量単価が安価なものへ定期的にバックアップを取りたい
現時点でも利用ソフトウェアのバージョンアップや設定変更で実現可能なものもありますが、無暗にストレージクラスの種類を増やさずバランスのよいストレージメニューを提供できるよう評価・検証等を継続していきたいと考えています。
この分野の進化はとても速く、我々も世の中の流れを追い切れていません。現時点であればもっと高機能かつ低遅延な選択肢があるのに気づいていないだけかもしれません。もし、より優れたソフトウェア等ご存じでしたら情報等いただけると幸いです。
関連リンク
IIJの商用サービスのインフラ改善を目指し、IIJ用KubernetesディストリビューションIKE(IIJ Kubernetes Engine)の開発を進めるIIJのSREチーム。
メンバーがウォッチしたKubernetes業界の話題と、大規模サービスインフラに求められるSREの気づきを投稿しています。